
T-MAC
优化低比特量化LLM推理的CPU加速框架
T-MAC是一个创新的内核库,采用查找表技术实现混合精度矩阵乘法,无需反量化即可加速CPU上的低比特LLM推理。该框架支持多种低比特模型,包括GPTQ/gguf的W4A16、BitDistiller/EfficientQAT的W2A16和BitNet的W1(.58)A8。T-MAC在多种设备上展现出显著性能提升,例如在Surface Laptop 7上,单核处理速度可达20 tokens/s,四核可达48 tokens/s,比llama.cpp快4~5倍。




T-MAC
<h3 align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/717cc9ef-2088-46bb-8962-b7069789483e.gif"> <p><a href=https://huggingface.co/1bitLLM/bitnet_b1_58-3B>BitNet</a> 在 T-MAC(基于查找表)与 llama.cpp(基于反量化)上的对比</p> </h3>新闻
-
2024年8月14日 🚀:T-MAC GEMM (N>1) 内核现已集成到 llama.cpp 中,以加速预填充。
-
2024年8月6日 🚀:支持 GPTQ 格式的 1/2/3/4 位量化 Llama 模型。使用 EfficientQAT 发布的预训练模型进行测试。
-
2024年7月27日 ✨:我们注意到在最新的骁龙 X Elite 芯片组上,T-MAC 在token生成速度上甚至比 NPU 更快!查看与 NPU 比较获取更多详情。
-
2024年7月23日 🚀🚀:我们已经支持通过 T-MAC 执行任何 GPTQ 格式的 2 位量化 Llama 模型!使用 EfficientQAT 发布的预训练模型进行测试。
-
2024年7月22日 🚀🚀:我们已经为 ARM 架构的 Windows 添加了原生部署支持。T-MAC 在 Surface Laptop 7 上展示了显著的 5 倍速度提升。
简介
T-MAC 是一个内核库,通过使用查找表直接支持混合精度矩阵乘法(int1/2/3/4 x int8/fp16/fp32),无需反量化。T-MAC 旨在提升 CPU 上低比特 LLM 推理的性能。T-MAC 已经支持各种低比特模型,包括来自 GPTQ/gguf 的 W4A16、来自 BitDistiller/EfficientQAT 的 W2A16 以及来自 BitNet 的 W1(.58)A8,适用于配备 ARM/Intel CPU 的 OSX/Linux/Windows 系统。
对于 3B BitNet,T-MAC 在 Surface Laptop 7 上单核可达到 20 tokens/秒的 token 生成吞吐量,四核可达到 48 tokens/秒,相比于最先进的 CPU 低比特框架(llama.cpp)实现了 4~5 倍的加速。T-MAC 甚至可以在树莓派 5 等性能较低的设备上达到 11 tokens/秒。
端到端加速
我们在五种不同的设备上评估了不同模型的 token 生成性能:Surface Laptop 7、Apple M2-Ultra、Jetson AGX Orin、树莓派 5 和 Surface Book 3。查看数据表获取更多详情。
我们使用 T-MAC 2 位和 llama.cpp Q2_K 评估 BitNet-3B 和 Llama-2-7B (W2),使用 T-MAC 4 位和 llama.cpp Q4_0 评估 Llama-2-7B (W4)。
除了提供显著的加速外,T-MAC 还可以使用更少的 CPU 核心达到相同的性能。例如,要达到 40 tokens/秒(远超人类阅读速度的吞吐量),T-MAC 仅需要 2 个核心,而 llama.cpp 需要 8 个核心。在 Jetson AGX Orin 上,要达到 10 tokens/秒(已经满足人类阅读速度的吞吐量),T-MAC 仅需要 2 个核心,而 llama.cpp 使用了全部 12 个核心。T-MAC 可以在树莓派 5 等配备较少 CPU 核心的低功率设备上满足实时需求。通过使用更少的核心,T-MAC 可以为其他应用保留计算资源,并显著降低功耗和能耗,这对边缘设备至关重要。
<h3 align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/a90e99f9-04b2-42fa-9ed4-762226041f12.png"> <p>T-MAC 在单线程上实现显著加速,并消耗更少的 CPU 核心达到相同的吞吐量</p> </h3>T-MAC 的吞吐量是在不使用快速聚合的情况下获得的。用户可以通过
-fa开启快速聚合,以获得额外 10%~20% 的加速。
预填充加速
待办:添加更多结果
我们对比了 Surface Laptop 7 上 Llama-2-7b (W2) 的预填充吞吐量(input_len=256),基准为:
- llama.cpp:llama.cpp 优化的基于反量化的低比特内核
- llama.cpp (OpenBLAS):llama.cpp OpenBLAS 后端
| 模型 | 线程数 | 批次大小 | T-MAC (tokens/秒) | llama.cpp (OpenBLAS) | llama.cpp |
|---|---|---|---|---|---|
| llama-2-7b (W2) | 4 | 256 | 50.1 | 21.5 | 12.0 |
| llama-2-7b (W2) | 8 | 256 | 94.4 | 37.7 | 21.3 |
内核级加速
我们的 GEMM 内核在 CPU 上展示了优于最先进的低比特 GEMM 的性能。下图显示了 token 生成过程中 llama-7b 内核相比 llama.cpp 的加速比(单线程):
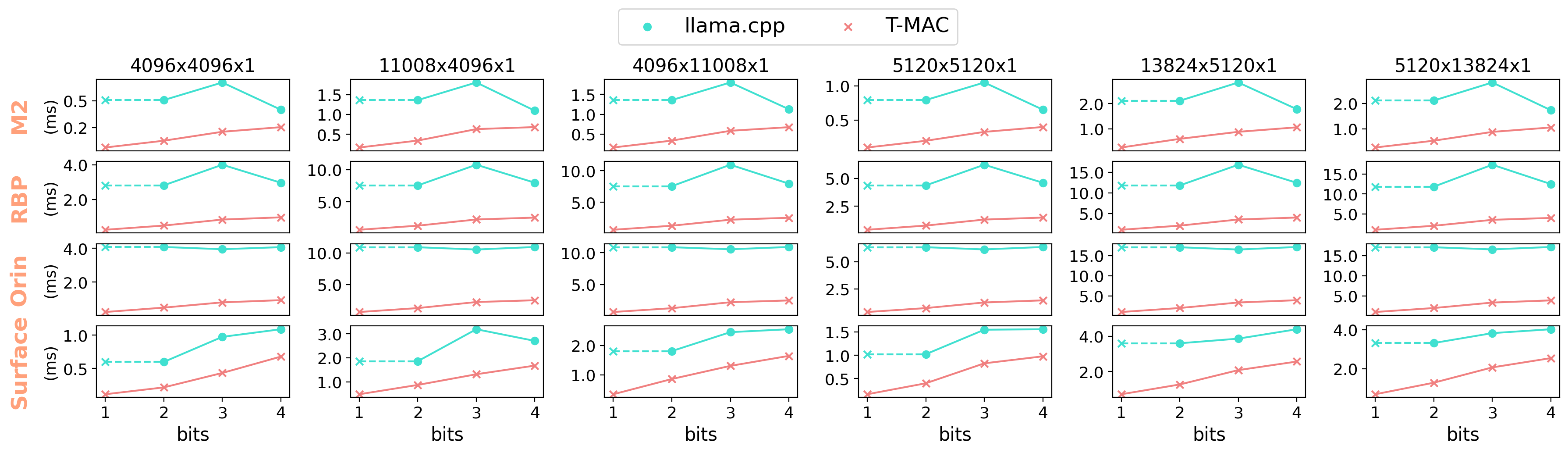
llama.cpp 没有提供 1 位内核实现,但我们可以从 2 位推断,因为根据 2/3/4 位的结果,它不会带来额外的加速。
由于计算成本的降低,T-MAC 可以在多批次(N>1)GEMM 中实现显著加速,这确保了在提示评估和多批次 token 生成方面的出色性能。下图显示了与使用 OpenBLAS 后端的 llama.cpp 相比的加速比(单线程):
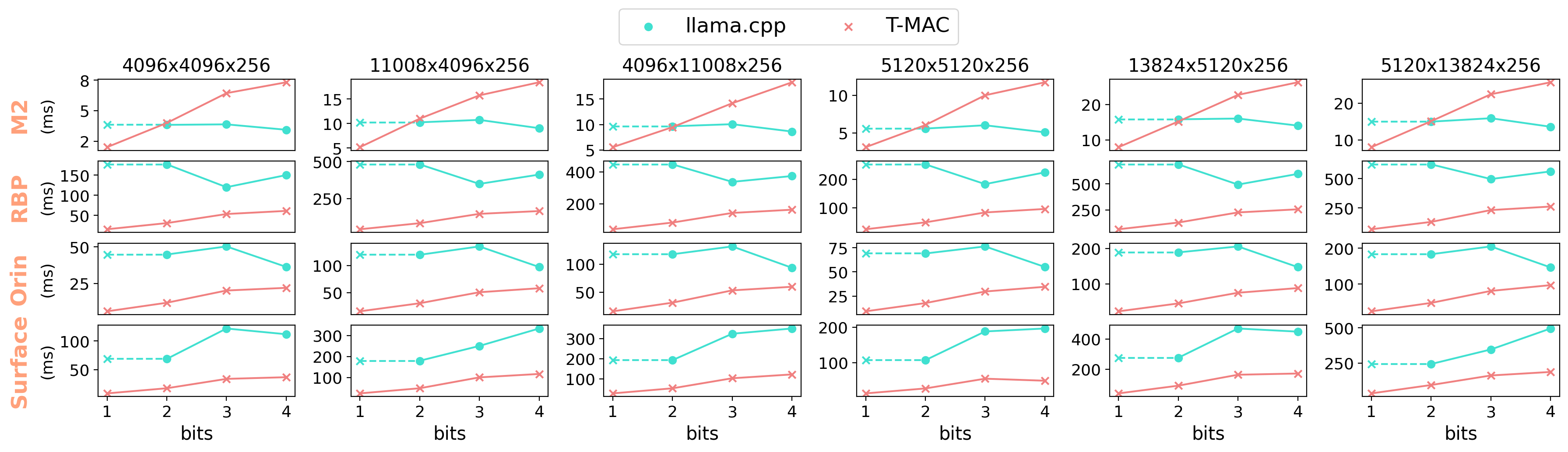
M2-Ultra 是个例外,因为它配备了专门设计的 AMX 协处理器 来加速多批次 GEMM。然而,T-MAC 在 2 位时仍然可以达到comparable的性能。
节能和降低功耗
通过用查表指令替代繁重的融合乘加指令,T-MAC 显著降低了功耗。结合加速效果,T-MAC 最终导致总能耗的大幅降低。
<p align="center"> <img src="https://yellow-cdn.veclightyear.com/835a84d5/678a1e83-02c2-4f35-b8b6-5f37812e57f9.png"> <p align="center">M2-Ultra 上三种模型的多线程功耗/能耗,M1: Llama-2-7B (W4),M2: Llama-2-7B (W2) 和 M3: BitNet-3B</p> </p>数据使用 powermetrics 采样。
与 NPU 比较
在最新的骁龙 X Elite 芯片组上,通过 T-MAC 的 CPU 相比通过高通骁龙神经处理引擎(NPE)的 NPU 实现了更好的性能。
在部署 llama-2-7b-4bit 模型时,NPU 只能生成 10.4 tokens/秒(根据此处发布的数据),而使用 T-MAC 的 CPU 可以用两个核心达到 12.6 tokens/秒,甚至高达 22 tokens/秒。考虑到 T-MAC 的计算性能可以随着比特数的减少而线性提升(这在基于反量化的 GPU 和 NPU 上无法观察到),T-MAC 甚至可以在 2 位时用单核 CPU 匹配 NPU 的性能。
| 框架 | 模型 | 线程数 | 吞吐量 (tokens/秒) |
|---|---|---|---|
| T-MAC (CPU) | llama-2-7b (W4) | 2 | <b>12.6</b> |
| T-MAC (CPU) | llama-2-7b (W4) | 4 | <b>18.7</b> |
| T-MAC (CPU) | llama-2-7b (W2) | 1 | 9.3 |
| T-MAC (CPU) | llama-2-7b (W2) | 4 | <b>28.4</b> |
| NPE (NPU) | llama-2-7b (W4) | - | 10.4 |
为了公平比较,我们将设置与NPU对齐,包括1024的输入长度和1024的输出长度。尽管Qualcomm部署了3.6GB的模型,由于我们的token嵌入保持未量化,我们部署的模型略大,为3.7GB。
与CUDA GPU比较
T-MAC在Jetson AGX Orin上实现了与CUDA GPU相当的2比特mpGEMM性能。虽然CUDA GPU在执行mpGEMM以外的内核时表现更佳,使得T-MAC (CPU)的端到端性能略慢,但T-MAC可以在功耗和能耗方面带来显著节省。
| 框架 | 吞吐量 (tokens/秒) | 功耗 (W) | 能耗 (J/token) |
|---|---|---|---|
| llama.cpp (CPU) | 7.08 | 15.0 | 2.12 |
| llama.cpp (GPU) | <b>20.03</b> | 30.8 | 1.54 |
| T-MAC (CPU) | 15.62 | <b>10.4</b> | <b>0.66</b> |
数据使用jetson-stats在MAXN功耗模式下采样。
安装
要求
- Python (TVM需要3.8版本)
- virtualenv
- cmake>=3.22
首先,安装cmake、zstd(llvm的依赖)和libomp(tvm的依赖)。推荐使用Homebrew:
brew install cmake zlib libomp
如果通过homebrew安装了
zstd,那么cmake也应该通过homebrew安装,以确保cmake能找到zstd。
从源代码安装t_mac(请在virtualenv中运行):
git clone --recursive https://github.com/microsoft/T-MAC.git # 在virtualenv中 pip install . -v # 或 pip install -e . -v source build/t-mac-envs.sh
该命令将下载clang+llvm并从源代码构建tvm。可能需要一些时间。
</details> <details> <summary><h3>Ubuntu (aarch64/x86_64)</h3></summary>从官方页面安装cmake>=3.22。
然后安装TVM构建依赖:
sudo apt install build-essential libtinfo-dev zlib1g-dev libzstd-dev libxml2-dev
从源代码安装t_mac(请在virtualenv中运行):
git clone --recursive https://github.com/microsoft/T-MAC.git # 在virtualenv中 pip install . -v # 或 pip install -e . -v source build/t-mac-envs.sh
该命令将下载clang+llvm并从源代码构建tvm。可能需要一些时间。
</details> <details> <summary><h3>Windows (x86_64)</h3></summary>由于Windows上缺乏稳定的clang+llvm预构建版本,建议使用Conda + Visual Studio来安装依赖。
首先,安装Visual Studio 2019并勾选"使用C++的桌面开发"和"适用于Windows的C++ Clang工具"。然后,在"Developer PowerShell for VS 2019"中创建conda环境:
git clone --recursive https://github.com/microsoft/T-MAC.git cd T-MAC conda env create --file conda\tvm-build-environment.yaml conda activate tvm-build
如果你使用Visual Studio 2022,请在yaml文件中将
llvmdev =14.0.6替换为llvmdev =17.0.6。
之后,构建TVM:
cd 3rdparty\tvm mkdir build cp cmake\config.cmake build
在build\config.cmake末尾添加set(USE_LLVM llvm-config)。
cd build cmake .. -A x64 cmake --build . --config Release -- /m
从源代码安装t_mac:
</details> <details> <summary><h3>Windows (ARM64)</h3></summary>cd ..\..\..\ # 回到项目根目录 $env:MANUAL_BUILD = "1" $env:PYTHONPATH = "$pwd\3rdparty\tvm\python" pip install . -v # 或 pip install -e . -v
以下过程可能比较复杂。如果你的部署场景不需要原生构建,可以使用WSL/docker并按照Ubuntu指南进行操作。
首先,安装Visual Studio 2022(/2019)并勾��选"使用C++的桌面开发"。然后,在"Developer PowerShell for VS 20XX"中创建conda环境。
git clone --recursive https://github.com/microsoft/T-MAC.git cd T-MAC conda env create --file conda\tvm-build-environment.yaml conda activate tvm-build
如果使用Visual Studio 2022(在ARM64上推荐使用以获得更好的性能),请记得在yaml文件中将llvmdev =14.0.6替换为llvmdev =17.0.6。
之后,构建TVM:
cd 3rdparty\tvm mkdir build cp cmake\config.cmake build
在build\config.cmake末尾添加set(USE_LLVM llvm-config)。
cd build cmake .. -A x64 # 以x64构建TVM,因为Python和依赖项是x64的 cmake --build . --config Release -- /m
如果在运行
cmake .. -A x64构建TVM时遇到类似string sub-command regex, mode replace: regex "$" matched an empty string.的错误,不用担心,只需再次运行cmake .. -A x64即可。详情请查看LLVM的这个问题。
由于Visual Studio中的clang工具实际上是模拟的x64工具,请手动安装原生arm64工具。
- 从官方Windows ARM安装程序安装CMake。
- 从发布页面下载Ninja并添加到Path。
- 从发布页面安装Clang。
在Developer Command Prompt/Powershell for VS之外启动以下命令,以��确保使用我们的原生clang工具。
从源代码安装t_mac:
</details>conda activate tvm-build conda uninstall cmake # 防止与原生ARM64 cmake潜在冲突 cd ..\..\..\ # 回到项目根目录 $env:MANUAL_BUILD = "1" $env:PYTHONPATH = "$pwd\3rdparty\tvm\python" pip install wmi # 用于在x86_64 python中检测原生ARM64 CPU pip install . -v # 或 pip install -e . -v
验证
之后,你可以通过以下方式验证安装:python -c "import t_mac; print(t_mac.__version__); from tvm.contrib.clang import find_clang; print(find_clang())"。
使用方法
目前,我们通过llama.cpp集成支持端到端推理。
我们提供了一个一体化脚本。使用以下命令调用:
pip install 3rdparty/llama.cpp/gguf-py huggingface-cli download 1bitLLM/bitnet_b1_58-3B --local-dir ${model_dir} python tools/run_pipeline.py -o ${model_dir}
我们还支持来自GPTQModel/EfficientQAT的GTPQ格式模型。尝试使用官方发布的EfficientQAT(GPTQ格式)Llama-3-8b-instruct-w2-g128:
huggingface-cli download ChenMnZ/Llama-3-8b-instruct-EfficientQAT-w2g128-GPTQ --local-dir ${model_dir} python tools/run_pipeline.py -o ${model_dir} -m llama-3-8b-2bit
使用
-p或-s参数选择要运行的步骤。使用-u参数来使用我们为ARM预构建的内核。
对于非对称量化,使用
--zero_point,这对大多数EfficientQAT模型是必需的(仅在Llama-3-8b-instruct-w4-g128/Llama-3-8b-instruct-w2-g128上验证过)。
输出示例:
运行步骤0:编译内核
在/Users/user/jianyu/T-MAC/deploy目录下运行命令:
python compile.py -o tuned -da -nt 4 -tb -gc -gs 128 -ags 64 -t -m hf-bitnet-3b -r
运行步骤1:构建T-MAC C++ CMakeFiles
在/Users/user/jianyu/T-MAC/build目录下运行命令:
cmake -DCMAKE_INSTALL_PREFIX=/Users/user/jianyu/T-MAC/install ..
运行步骤2:安装T-MAC C++
在/Users/user/jianyu/T-MAC/build目录下运行命令:
cmake --build . --target install --config Release
运行步骤3:将HF转换为GGUF
在/Users/user/jianyu/T-MAC/3rdparty/llama.cpp目录下运行命令:
python convert-hf-to-gguf-t-mac.py /Users/user/Downloads/test_models/hf-bitnet-3B --outtype i2 --outfile /Users/user/Downloads/test_models/hf-bitnet-3B/ggml-model.i2.gguf --kcfg /Users/user/jianyu/T-MAC/install/lib/kcfg.ini
运行步骤4:构建llama.cpp CMakeFiles
在/Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build目录下运行命令:
cmake .. -DLLAMA_TMAC=ON -DCMAKE_PREFIX_PATH=/Users/user/jianyu/T-MAC/install/lib/cmake/t-mac -DCMAKE_BUILD_TYPE=Release -DLLAMA_LLAMAFILE_DEFAULT=OFF -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++
运行步骤5:构建llama.cpp
在/Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build目录下运行命令:
cmake --build . --target main --config Release
运行步骤6:执行推理
在/Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build目录下运行命令:
/Users/user/jianyu/T-MAC/3rdparty/llama.cpp/build/bin/main -m /Users/user/Downloads/test_models/hf-bitnet-3B/ggml-model.i2.gguf -n 128 -t 4 -p Microsoft Corporation is an American multinational corporation and technology company headquartered in Redmond, Washington. -b 1 -ngl 0 -c 2048
查看logs/2024-07-15-17-10-11.log获取推理输出
即将推出的功能
我们即将:
- 添加
I4格式以简化4位模型的部署。 - 将T-MAC GEMM内核嵌入llama.cpp以加速预填充/提示。
- 通过LUTI4优化支持SME2的ARMv9 CPU
技术
LLM推理需要大量计算成本。低位量化是一种广泛采用的技术,但它引入了混合精度GEMM(mpGEMM)的挑战,硬件不直接支持这种运算,需要进行转换/反量化操作。
我们提出使用查找表(LUT)来支持mpGEMM。我们的方法包括以下关键技术:
- 鉴于权重的低精度,我们将一位权重分组(例如,分成4组),预计算所有可能的部分和,然后使用LUT存储它们。
- 我们采用移位和累加操作来支持从1到4的可扩展位数。
- 在CPU上,我们利用tbl/pshuf指令进行快速表查找。
- 我们将表大小从$2^n$减少到$2^{n-1}$,并结合符号位来加速LUT预计算。
我们的方法展现了几个显著特征:
- T-MAC显示了FLOPs和推理延迟相对于位数的线性缩放比例。这与传统的基于转换的方法形成对比,后者在从4位降低到更低位时无法实现额外的加速。
- T-MAC天然支持int1/2/3/4的按位计算,无需反量化。此外,它通过快速表查找和加法指令适应所有类型的激活(如fp8、fp16、int8),绕过了对支持不佳的融合乘加指令的需求。
引用
如果您觉得这个仓库有用,请使用以下BibTeX条目进行引用。
@misc{wei2024tmaccpurenaissancetable,
title={T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge},
author={Jianyu Wei and Shijie Cao and Ting Cao and Lingxiao Ma and Lei Wang and Yanyong Zhang and Mao Yang},
year={2024},
eprint={2407.00088},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2407.00088},
}
编辑推荐精选


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
�一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生成的项目。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。


飞书多维表格
飞书多维表格 ×DeepSeek R1 满血版
飞书多维表格联合 DeepSeek R1 模型,提供 AI 自动化解决方案,支持批量写作、数据分析、跨模态处理等功能,适用于电商、短视频、影视创作等场景,提升企业生产力与创作效率。关键词:飞书多维表格、DeepSeek R1、AI 自动化、批量处理、企业协同工具。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号