
table-transformer
基于深度学习的表格提取与�结构识别模型
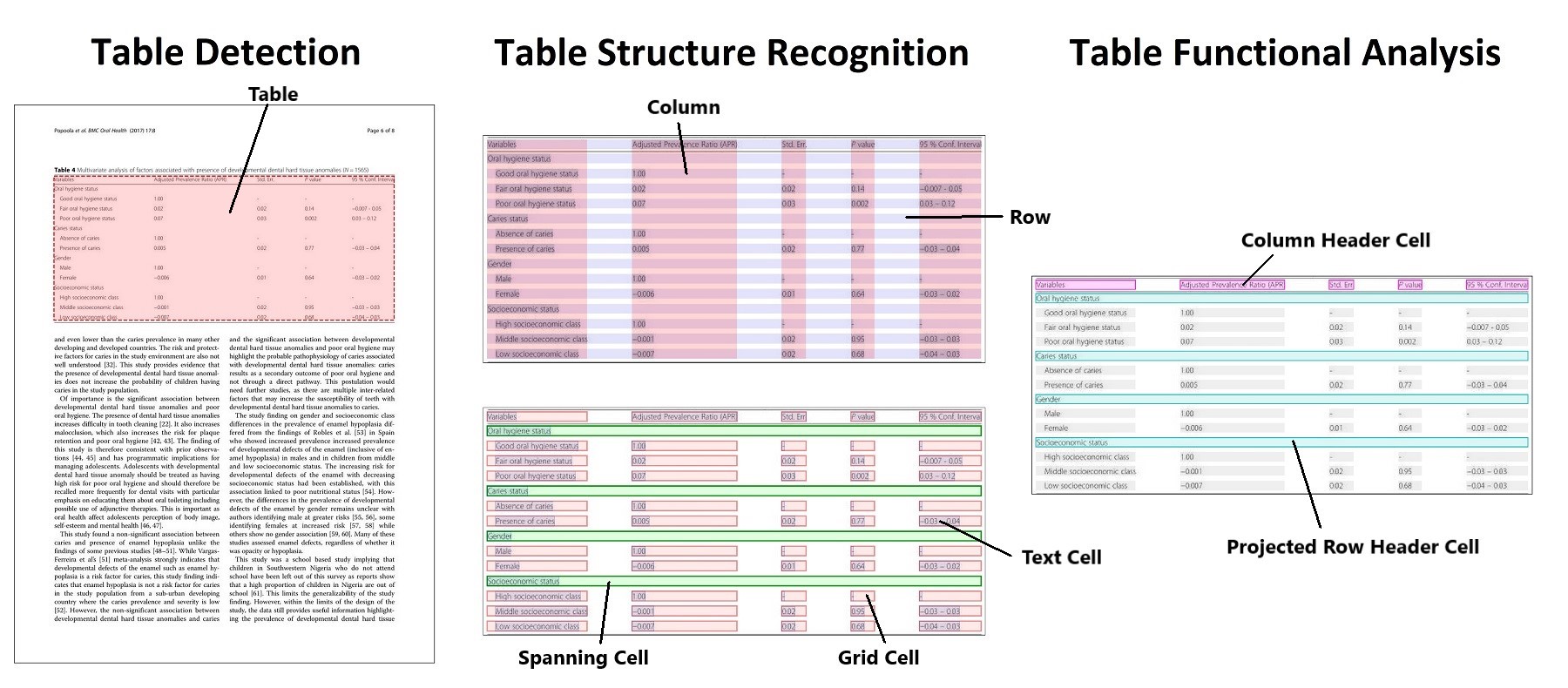
Table Transformer (TATR)是一种基于对象检测的深度学习模型,用于从PDF和图像中提取表格。该模型支持表格检测、结构识别和功能分析,并提供完整的训练和推理代码。TATR还发布了在PubTables-1M等大规模数据集上的预训练模型权重,有助于实现高精度的表格提取和分析。



表格转换器 (TATR)
一种基于目标检测的深度学习模型,用于从PDF和图像中提取表格。
首次提出于"PubTables-1M:面向非结构化文档的全面表格提取"。
本仓库还包含以下论文的官方代码:
注意:如果您想使用表格转换器提取自己的表格,以下是一些有用的信息:
- TATR可以训练以适用于多个文档领域,这里包含了训练自己模型所需的一切。但目前只提供了在PubTables-1M数据集上训练的TATR预训练模型权重。(有关如何训练自己的多领域模型,请参阅附加文档。)
- TATR是一个从图像输入识别表格的目标检测模型。基于TATR构建的推理代码需要文本提取(来自OCR或直接从PDF)作为单独输入,以便在其HTML或CSV输出中包含文本。
下面提供了有关该项目的更多信息,包括数据、训练、评估和推理代码,供用户和研究人员使用。
新闻
2023年8月22日:我们发布了3个新的TATR-v1.1预训练模型(分别在1. PubTables-1M、2. FinTabNet.c和3. 两个数据集合并上训练),详情请参阅我们的论文。
2023年4月19日:我们最新的论文(链接和链接)已被ICDAR 2023接受。
2023年3月9日:我们在官方训练脚本中增加了更多图像裁剪(与我们最新论文中的做法相同),并更新了代码和environment.yml,使用Python 3.10.9、PyTorch 1.13.1和Torchvision 0.14.1等。
2023年3月7日:我们发布了一个新的简单推理流程用于TATR。现在您可以轻松地从图像中检测和识别表格,并将它们转换为HTML或CSV。
2023年3月7日:我们发布了一个脚本集合,用于创建TATR的训练数据并规范化已有的数据集,如FinTabNet和SciTSR。
2023年3月1日:新论文"对齐表格结构识别的基准数据集"现已在arXiv上发布。
2022年11月25日:我们已将完整的PubTables-1M数据集另外提供在Hugging Face上下载。
2022年5月5日:我们发布了在PubTables-1M上训练的表格结构识别模型的预训练权重。
2022年3月23日:我们的论文"GriTS:用于表格结构识别的网格表格相似度度量"现已在arXiv上发布
2022年3月4日:我们发布了在PubTables-1M上训练的表格检测模型的预训练权重。
2022年3月3日:"PubTables-1M:面向非结构化文档的全面表格提取"已被CVPR 2022接受。
2021年11月21日:我们更新的论文"PubTables-1M:面向非结构化文档的全面表格提取"已在arXiv上发布。
2021年10月21日:完整的PubTables-1M数据集已在Microsoft Research Open Data上正式发布。
2021年6月8日:表格转换器(TATR)项目的初始版本发布。
PubTables-1M
PubTables-1M的目标是创建一个大型、详细、高质量的数据集,用于训练和评估各种用于表格检测、表格结构识别和功能分析任务的模型。
它包含:
- 575,305个包含表格的已注释文档页面,用于表格检测。
- 947,642个完全注释的表格,包括文本内容和完整位置(边界框)信息,用于表格结构识别和功能分析。
- 所有表格行、列和单元格(包括空白单元格)的完整边界框,以图像和PDF坐标表示,以及其他注释结构,如列标题和投影行标题。
- 所有表格和页面的渲染图像。
- 每个表格和页面图像中出现的所有单词的边界框和文本。
- 当前模型训练中未使用的其他单元格属性。
此外,标题中的单元格经过规范化处理,我们实施了多个质量控制步骤,以确保注释尽可能无噪声。更多详情,请参阅我们的论文。
预训练模型权重
我们为表格检测和表格结构识别提供了不同的预训练模型。 <b>表格检测:</b>
<table> <thead> <tr style="text-align: right;"> <th>模型</th> <th>训练数据</th> <th>模型卡片</th> <th>文件</th> <th>大小</th> </tr> </thead> <tbody> <tr style="text-align: right;"> <td>DETR R18</td> <td>PubTables-1M</td> <td><a href="https://huggingface.co/bsmock/tatr-pubtables1m-v1.0">模型卡片</a></td> <td><a href="https://huggingface.co/bsmock/tatr-pubtables1m-v1.0/resolve/main/pubtables1m_detection_detr_r18.pth">权重</a></td> <td>110 MB</td> </tr> </tbody> </table><b>表格结构识别:</b>
<table> <thead> <tr style="text-align: left;"> <th>模型</th> <th>训练数据</th> <th>模型卡片</th> <th>文件</th> <th>大小</th> </tr> </thead> <tbody> <tr style="text-align: left;"> <td>TATR-v1.0</td> <td>PubTables-1M</td> <td><a href="https://huggingface.co/bsmock/tatr-pubtables1m-v1.0">模型卡片</a></td> <td><a href="https://huggingface.co/bsmock/tatr-pubtables1m-v1.0/resolve/main/pubtables1m_structure_detr_r18.pth">权重</a></td> <td>110 MB</td> </tr> <tr style="text-align: left;"> <td>TATR-v1.1-Pub</td> <td>PubTables-1M</td> <td><a href="https://huggingface.co/bsmock/TATR-v1.1-Pub">模型卡片</a></td> <td><a href="https://huggingface.co/bsmock/TATR-v1.1-Pub/resolve/main/TATR-v1.1-Pub-msft.pth">权重</a></td> <td>110 MB</td> </tr> <tr style="text-align: left;"> <td>TATR-v1.1-Fin</td> <td>FinTabNet.c</td> <td><a href="https://huggingface.co/bsmock/TATR-v1.1-Fin">模型卡片</a></td> <td><a href="https://huggingface.co/bsmock/TATR-v1.1-Fin/resolve/main/TATR-v1.1-Fin-msft.pth">权重</a></td> <td>110 MB</td> </tr> <tr style="text-align: left;"> <td>TATR-v1.1-All</td> <td>PubTables-1M + FinTabNet.c</td> <td><a href="https://huggingface.co/bsmock/TATR-v1.1-All">模型卡片</a></td> <td><a href="https://huggingface.co/bsmock/TATR-v1.1-All/resolve/main/TATR-v1.1-All-msft.pth">权重</a></td> <td>110 MB</td> </tr> </tbody> </table>评估指标
<b>表格检测:</b>
<table> <thead> <tr style="text-align: right;"> <th>模型</th> <th>测试数据</th> <th>AP50</th> <th>AP75</th> <th>AP</th> <th>AR</th> </tr> </thead> <tbody> <tr style="text-align: right;"> <td>DETR R18</td> <td>PubTables-1M</td> <td>0.995</td> <td>0.989</td> <td>0.970</td> <td>0.985</td> </tr> </tbody> </table><b>表格结构识别:</b>
<table> <thead> <tr style="text-align: right;"> <th>模型</th> <th>测试数据</th> <th>AP50</th> <th>AP75</th> <th>AP</th> <th>AR</th> <th>GriTS<sub>Top</sub></th> <th>GriTS<sub>Con</sub></th> <th>GriTS<sub>Loc</sub></th> <th>Acc<sub>Con</sub></th> </tr> </thead> <tbody> <tr style="text-align: right;"> <td>TATR-v1.0</td> <td>PubTables-1M</td> <td>0.970</td> <td>0.941</td> <td>0.902</td> <td>0.935</td> <td>0.9849</td> <td>0.9850</td> <td>0.9786</td> <td>0.8243</td> </tr> </tbody> </table>训练和评估数据
PubTables-1M可从微软研究院开放数据下载。 我们还将完整的档案集上传到了Hugging Face。
Microsoft Research Open Data上的数据集包含5个tar.gz文件:
- PubTables-1M-Image_Page_Detection_PASCAL_VOC.tar.gz:用于检测模型的训练和评估数据
/images:575,305个JPG文件;每个页面图像对应一个文件/train:460,589个XML文件,包含PASCAL VOC格式的边界框/test:57,125个XML文件,包含PASCAL VOC格式的边界框/val:57,591个XML文件,包含PASCAL VOC格式的边界框
- PubTables-1M-Image_Page_Words_JSON.tar.gz:每个页面图像中所有单词的边界框和文本内容
- 每个页面图像对应一个JSON文件(外加一些未使用的额外文件)
- PubTables-1M-Image_Table_Structure_PASCAL_VOC.tar.gz:用于结构(和功能分析)模型的训练和评估数据
/images:947,642个JPG文件;每个页面图像对应一个文件/train:758,849个XML文件,包含PASCAL VOC格式的边界框/test:93,834个XML文件,包含PASCAL VOC格式的边界框/val:94,959个XML文件,包含PASCAL VOC格式的边界框
- PubTables-1M-Image_Table_Words_JSON.tar.gz:每个裁剪后的表格图像中所有单词的边界框和文本内容
- 每个裁剪后的表格图像对应一个JSON文件(外加一些未使用的额外文件)
- PubTables-1M-PDF_Annotations_JSON.tar.gz:源PubMed PDF中出现的所有表格的详细注释。所有注释都采用PDF坐标。
- 401,733个JSON文件;每个源PDF对应一个文件
从命令行下载:
- 用网络浏览器访问数据集主页,点击左上角的下载按钮。这将创建一个从Azure下载数据集的链接,其中包含为您生成的唯一访问令牌,链接形如
https://msropendataset01.blob.core.windows.net/pubtables1m?[SAS_TOKEN_HERE]。 - 然后,您可以使用命令行工具azcopy通过以下命令下载所有文件:
azcopy copy "https://msropendataset01.blob.core.windows.net/pubtables1m?[SAS_TOKEN_HERE]" "/path/to/your/download/folder/" --recursive
然后使用以下命令在命令行中解压每个压缩包:
tar -xzvf yourfile.tar.gz
代码安装
使用yml文件创建conda环境并激活,步骤如下:
conda env create -f environment.yml
conda activate tables-detr
模型训练
该代码为两组不同的表格提取任务训练模型:
- 表格检测
- 表格结构识别 + 功能分析
有关这些任务和模型的详细描述,请参阅论文。
要进行训练,您需要cd到src目录并指定:1. 数据集路径,2. 任务类型(检测或结构),3. 配置文件路径,其中包含架构和训练的超参数。
训练检测模型:
python main.py --data_type detection --config_file detection_config.json --data_root_dir /path/to/detection_data
训练结构识别模型:
python main.py --data_type structure --config_file structure_config.json --data_root_dir /path/to/structure_data
评估
评估代码计算检测模型和结构模型的标准目标检测指标(AP、AP50等)。 在�运行结构模型的评估时,它还计算表格结构识别的网格表格相似度(GriTS)指标。 GriTS是表格单元格正确性的度量,定义为所有表格中每个单元格的平均正确性。 GriTS可以基于以下几点衡量预测单元格的正确性:1. 仅考虑单元格拓扑结构,2. 单元格拓扑结构和每个单元格报告的边界框位置,3. 单元格拓扑结构和每个单元格报告的文本内容。 有关GriTS的更多详细信息,请参阅我们的论文。
计算检测模型的目标检测指标:
python main.py --mode eval --data_type detection --config_file detection_config.json --data_root_dir /path/to/pascal_voc_detection_data --model_load_path /path/to/detection_model
计算结构识别模型的目标检测和GriTS指标:
python main.py --mode eval --data_type structure --config_file structure_config.json --data_root_dir /path/to/pascal_voc_structure_data --model_load_path /path/to/structure_model --table_words_dir /path/to/json_table_words_data
可选地,您可以添加标志来控制并行化、保存详细指标和保存可视化:
--device cpu: 将默认设备从cuda更改为cpu。
--batch_size 4: 控制模型前向传播期间使用的批量大小。
--eval_pool_size 4: 控制GriTS指标计算期间CPU并行化的工作池大小。
--eval_step 2: 控制在将所有样本传递给并行化工作池进行GriTS指标计算之前,要累积的已处理输入数据批次数。
--debug: 创建并保存模型推理的可视化。对于每个输入图像"PMC1234567_table_0.jpg",这将保存两个可视化:"PMC1234567_table_0_bboxes.jpg"包含模型输出的边界框,"PMC1234567_table_0_cells.jpg"包含后处理后的最终表格单元格边界框。默认情况下,这些保存在当前目录下的新文件夹"debug"中。
--debug_save_dir /path/to/folder: 指定保存可视化的文件夹。
--test_max_size 500: 在随机抽样的数据子集上运行评估。适用于快速验证和检查。
微调和其他模型训练场景
如果模型训练中断,可以通过使用标志--model_load_path /path/to/model.pth并指定包含保存的优化器状态的字典文件的路径来轻松恢复。
如果您想通过微调保存的检查点(如model_20.pth)来重新开始训练,请使用标志--model_load_path /path/to/model_20.pth和标志--load_weights_only来表明恢复训练不需要之前的优化器状态。
无论是微调还是从头开始训练新模型,您都可以选择创建一个具有不同于我们使用的默认参数的新配置文件。使用以下方式指定新的配置文件:--config_file /path/to/new_structure_config.json。创建新的配置文件很有用,例如,如果您想在微调期间使用不同的学习率lr。
或者,配置文件中的许多参数都可以使用相关的标志作为命令行参数指定。作为命令行参数指定的任何参数都会覆盖配置文件中该参数的值。
引用
我们的工作可以使用以下方式引用:
[此处省略引用文献的BibTeX格式内容,因为它们不需要翻译]
贡献
本项目欢迎贡献和建议。大多数贡献要求您同意贡献者许可协议(CLA),声明您有权并且确实授予我们使用您贡献的权利。有关详细信息,请访问https://cla.opensource.microsoft.com。
当您提交拉取请求时,CLA机器人将自动确定您是否需要提供CLA,并相应地修饰PR(例如,状态检查、评论)。只需按照机器人提供的说明操作即可。您只需在所有使用我们CLA的仓库中执行一次此操作。
本项目已采用Microsoft�开源行为准则。 有关更多信息,请参阅行为准则常见问题解答或联系opencode@microsoft.com获取任何其他问题或意见。
商标
本项目可能包含项目、产品或服务的商标或标识。Microsoft商标或标识的授权使用必须遵循Microsoft商标和品牌指南。 在本项目的修改版本中使用Microsoft商标或标识不得引起混淆或暗示Microsoft赞助。 任何第三方商标或标识的使用均受这些第三方的政策约束。
编辑推荐精选


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言�模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。


HunyuanVideo
HunyuanVideo 是一个可基于文本生成高质量图像和视频的项目。
HunyuanVideo 是一个专注于文本到图像及视频生成的项目。它具备强大的视频生成能力,支持多种分辨率和视频长度选择,能根据用户输入的文本生成逼真的图像和视频。使用先进的技术架构和算法,可灵活调整生成参数,满足不同场景的需求,是文本生成图像视频领域的优质工具。


WebUI for Browser Use
一个基于 Gradio 构建的 WebUI,支持与浏览器智能体进行便捷交互。
WebUI for Browser Use 是一个强大的项目,它集成了多种大型语言模型,支持自定义浏览器使用,具备持久化浏览器会话等功能。用户可以通过简洁友好的界面轻松控制浏览器智能体完成各类任务,无论是数据提取、网页导航还是表单填写等操作都能高效实现,有利于提高工作��效率和获取信息的便捷性。该项目适合开发者、研究人员以及需要自动化浏览器操作的人群使用,在 SEO 优化方面,其关键词涵盖浏览器使用、WebUI、大型语言模型集成等,有助于提高网页在搜索引擎中的曝光度。


xiaozhi-esp32
基于 ESP32 的小智 AI 开发项目,支持多种网络连接与协议,实现语音交互等功能。
xiaozhi-esp32 是一个极具创新性的基于 ESP32 的开发项目,专注于人工智能语音交互领域。项目涵盖了丰富的功能,如网络连接、OTA 升级、设备激活等,同时支持多种语言。无论是开发爱好者还是专业开发者,都能借助该项目快速搭建起高效的 AI 语音交互系统,为智能设备开发提供强大助力。


olmocr
一个用于 OCR 的项目,支持多种模型和服务器进行 PDF 到 Markdown 的转换,并提供测试和报告功能。
olmocr 是一个专注于光学字符识别(OCR)的 Python 项目,由 Allen Institute for Artificial Intelligence 开发。它支持多种模型和服务器,如 vllm、sglang、OpenAI 等,可将 PDF 文件的页面转换为 Markdown 格式。项目还提供了测试框架和 HTML 报告生成功能,方便用户对 OCR 结果进行评估和分析。适用于科研、文档处理等领域,有助于提高工作效率和准确性。


飞书多维表格
飞书多维表格 ×DeepSeek R1 满血版
飞书多维表格联合 DeepSeek R1 模型,提供 AI 自动化解决方案,支持批量写作、数据分析、跨模态处理等功能,适用于电商、短视频、影视创作等场景,提升企业生产力与创作效率。关键词:飞书多维表格、DeepSeek R1、AI 自动化、批量处理、企业协同工具。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号