
 访问官网
访问官网 Github
Github 文档
文档 论文
论文




Merlion:时间序列机器学习库
目录
简介
Merlion 是一个用于时间序列智能的 Python 库。它提供了一个端到端的机器学习框架,包括数据加载和转换、模型构建和训练、模型输出后处理以及模型性能评估。它支持各种时间序列学习任务,包括单变量和多变量时间序列的预测、异常检测和变点检测。该库旨在为工程师和研究人员提供一站式解决方案,以快速开发适合其特定时间序列需求的模型,并在多个时间序列数据集上进行基准测试。
Merlion 的主要特点包括:
- 为广泛的预测和异常检测数据集提供标准化且易于扩展的数据加载和基准测试。这包括对自定义数据集的透明支持。
- 一个包含多种异常检测、预测和变点检测模型的库,所有模型都统一在共享接口下。模型包括经典统计方法、树集成和深度学习方法。高级用户可以根据需要完全配置每个模型。
- 抽象的
DefaultDetector和DefaultForecaster模型,它们高效、稳健地实现良好性能,并为新用户提供起点。 - 用于自动超参数调整和模型选择的 AutoML。
- 统一的 API,用于使用各种模型进行外生回归变量预测。
- 实用的、受行业启发的异常检测器后处理规则,使异常分数更具可解释性,同时减少误报数量。
- 易于使用的集成模型,结合多个模型的输出以实现更稳健的性能。
- 灵活的评估流程,模拟生产环境中模型的实时部署和再训练,并评估预测和异常检测的性能。
- 原生支持可视化模型预测,包括可点击的可视化界面。
- 使用 PySpark 的分布式计算后端,可用于大规模部署时间序列应用。
与相关库的比较
下表直观地概述了 Merlion 的主要特性与其他时间序列异常检测和/或预测库的比较。
| Merlion | Prophet | Alibi Detect | Kats | darts | statsmodels | nixtla | GluonTS | RRCF | STUMPY | Greykite | pmdarima | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 单变量预测 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 多变量预测 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||
| 单变量异常检测 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 多变量异常检测 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||
| 预处理 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||
| 后处理 | ✅ | ✅ | ||||||||||
| AutoML | ✅ | ✅ | ✅ | |||||||||
| 集成 | ✅ | ✅ | ✅ | ✅ | ||||||||
| 基准测试 | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||
| 可视化 | ✅ | ✅ | ✅ | ✅ | ✅ |
以下特性是 Merlion 2.0 的新增功能:
| Merlion | Prophet | Alibi Detect | Kats | darts | statsmodels | nixtla | GluonTS | RRCF | STUMPY | Greykite | pmdarima | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 外生回归变量 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||
| 变点检测 | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||
| 可点击的可视化界面 | ✅ | |||||||||||
| 分布式后端 | ✅ | ✅ |
安装
Merlion 由两个子仓库组成:merlion 实现了库的核心时间序列智能功能,而 ts_datasets 为多个时间序列数据集提供了标准化的数据加载器。这些加载器将时间序列加载为带有附加元数据的 pandas.DataFrame。
您可以通过调用 pip install salesforce-merlion 从 PyPI 安装 merlion。您也可以通过克隆此仓库并调用 pip install Merlion/ 来从源代码安装,或调用 pip install -e Merlion/ 以可编辑模式安装。您可以通过 pip install salesforce-merlion[all] 安装额外的依赖项,或者如果从源代码安装,则调用 pip install "Merlion/[all]"。单独的可选依赖项包括用于 GUI 仪表板的 dashboard,用于 PySpark 分布式计算后端的 spark,以及用于所有深度学习模型的 deep-learning。
要安装数据加载包 ts_datasets,请克隆此仓库并调用 pip install -e Merlion/ts_datasets/。如果您不想在初始化每个数据集的数据加载器时手动指定其根目录,则必须以可编辑模式(即使用 -e 标志)安装此包。
请注意以下外部依赖项:
-
我们的一些预测模型依赖于 OpenMP。如果使用
conda,请在安装我们的包之前执行conda install -c conda-forge lightgbm。这将确保 OpenMP 在您的conda环境中配置为与lightgbm包(我们的一个依赖项)一起工作。如果使用 Mac,请安装 Homebrew 并调用brew install libomp,以便 OpenMP 库可用于该模型。 -
我们的一些异常检测模型依赖于 Java 开发工具包(JDK)。对于 Ubuntu,调用
sudo apt-get install openjdk-11-jdk。对于 Mac OS,安装 Homebrew 并调用brew tap adoptopenjdk/openjdk && brew install --cask adoptopenjdk11。还要确保可以在您的PATH中找到java,并且设置了JAVA_HOME环境变量。
文档
有关示例代码和 Merlion 的介绍,请参阅 examples 中的 Jupyter 笔记本,以及这里的指导性演练。您可以在这里找到详细的 API 文档(包括示例代码)。技术报告概述了 Merlion 的整体架构,并展示了单变量和多变量时间序列异常检测和预测的实验结果。
入门
最简单的入门方式是使用基于 GUI 的网页仪表板。这个仪表板提供了一种快速在您自己的自定义数据集上试验多个模型的好方法。要使用它,请安装带有可选 dashboard 依赖项的 Merlion(即 pip install salesforce-merlion[dashboard]),并从命令行调用 python -m merlion.dashboard。您可以在 http://localhost:8050 查看仪表板。下面我们展示了异常检测和预测的仪表板截图。
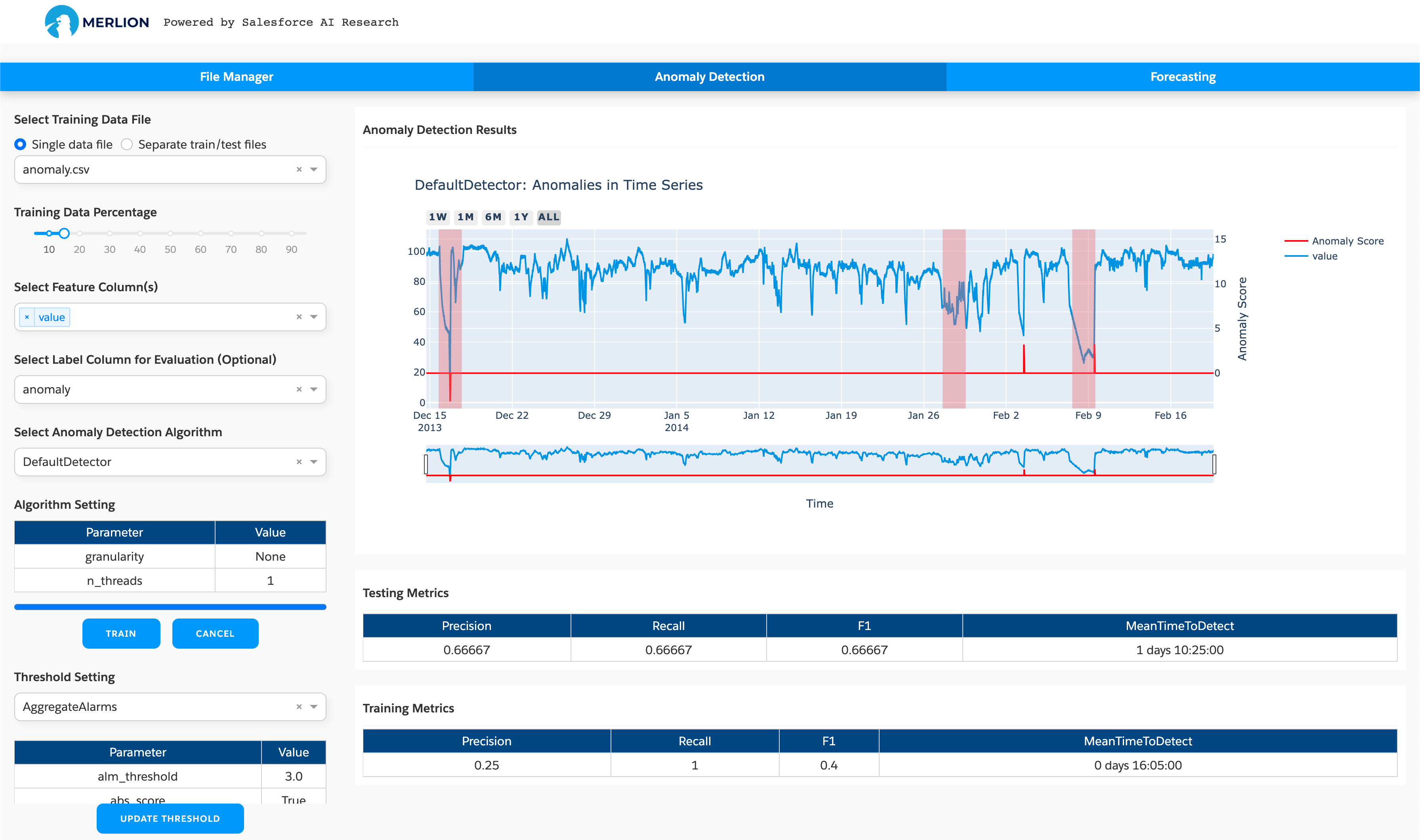
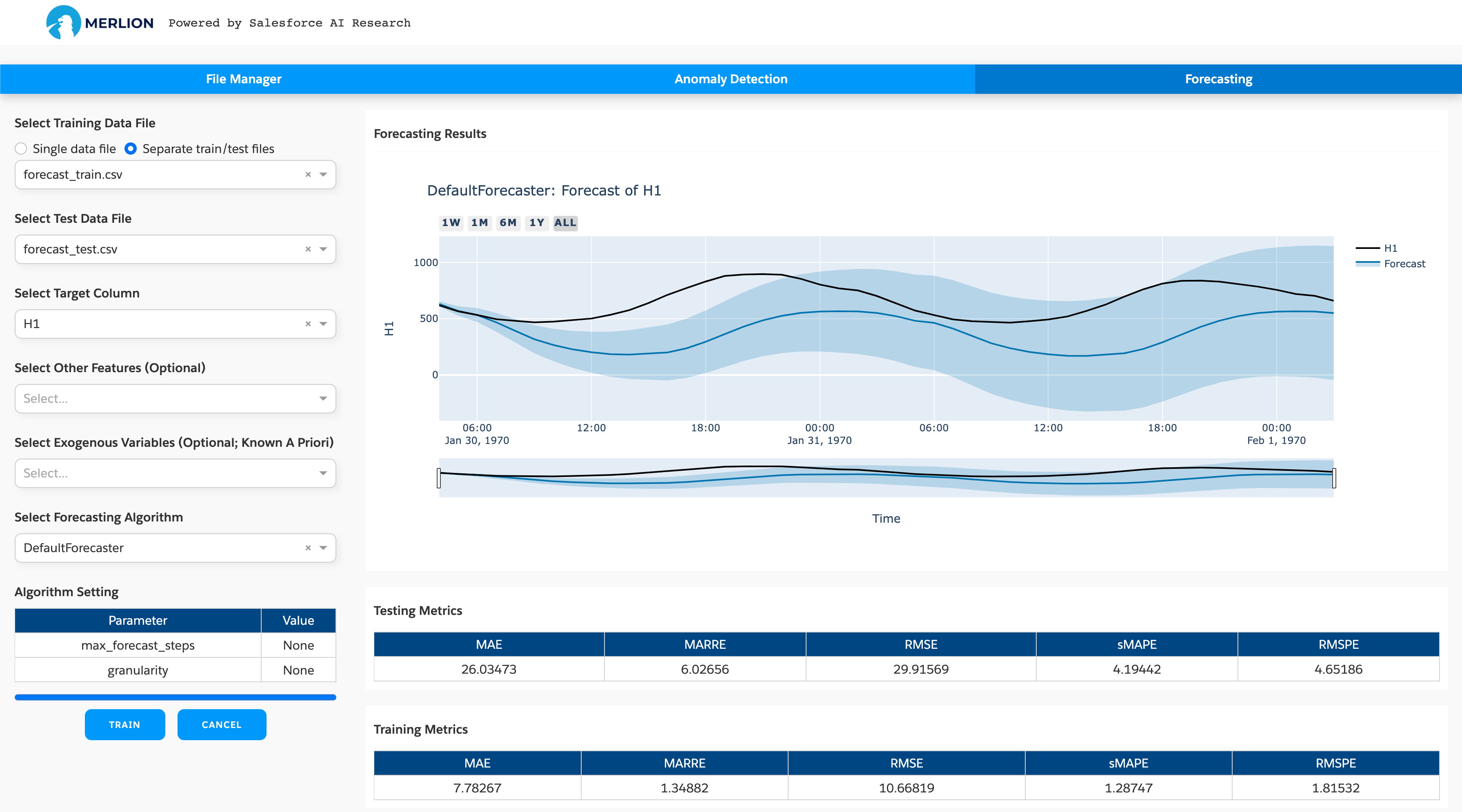
为了帮助您在自己的代码中开始使用 Merlion,我们在下面提供了使用 Merlion 默认模型进行异常检测和预测的最小示例。
异常检测
这里,我们展示了复现上面异常检测仪表板结果的代码。我们首先导入 Merlion 的 TimeSeries 类和 Numenta 异常基准 NAB 的数据加载器。然后,我们可以将该数据集中的特定时间序列划分为训练和测试部分。
from merlion.utils import TimeSeries
from ts_datasets.anomaly import NAB
# 数据加载器返回 pandas DataFrames,我们将其转换为 Merlion TimeSeries
time_series, metadata = NAB(subset="realKnownCause")[3]
train_data = TimeSeries.from_pd(time_series[metadata.trainval])
test_data = TimeSeries.from_pd(time_series[~metadata.trainval])
test_labels = TimeSeries.from_pd(metadata.anomaly[~metadata.trainval])
然后,我们可以初始化并训练 Merlion 的 DefaultDetector,这是一个平衡性能和效率的异常检测模型。我们还获取其在测试集上的预测。
from merlion.models.defaults import DefaultDetectorConfig, DefaultDetector
model = DefaultDetector(DefaultDetectorConfig())
model.train(train_data=train_data)
test_pred = model.get_anomaly_label(time_series=test_data)
接下来,我们可视化模型的预测。
from merlion.plot import plot_anoms
import matplotlib.pyplot as plt
fig, ax = model.plot_anomaly(time_series=test_data)
plot_anoms(ax=ax, anomaly_labels=test_labels)
plt.show()
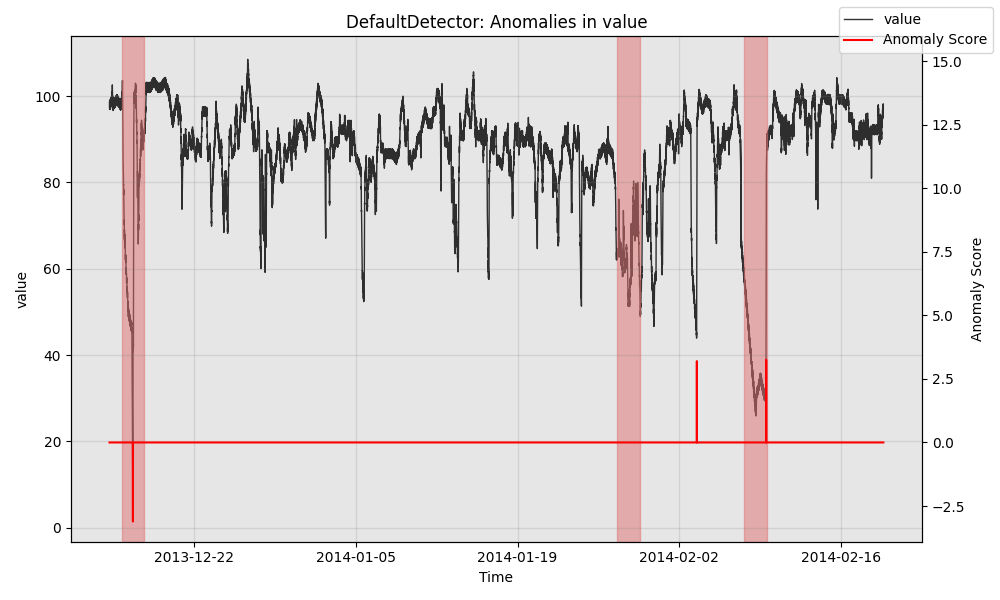 最后,我们可以定量评估模型。精确率和召回率来自于模型触发了3个警报,其中2个为真正例,1个为假负例,1个为假正例。我们还评估了模型正确检测到每个异常所需的平均时间。
最后,我们可以定量评估模型。精确率和召回率来自于模型触发了3个警报,其中2个为真正例,1个为假负例,1个为假正例。我们还评估了模型正确检测到每个异常所需的平均时间。
from merlion.evaluate.anomaly import TSADMetric
p = TSADMetric.Precision.value(ground_truth=test_labels, predict=test_pred)
r = TSADMetric.Recall.value(ground_truth=test_labels, predict=test_pred)
f1 = TSADMetric.F1.value(ground_truth=test_labels, predict=test_pred)
mttd = TSADMetric.MeanTimeToDetect.value(ground_truth=test_labels, predict=test_pred)
print(f"精确率: {p:.4f}, 召回率: {r:.4f}, F1值: {f1:.4f}\n"
f"平均检测时间: {mttd}")
精确率: 0.6667, 召回率: 0.6667, F1值: 0.6667
平均检测时间: 1天 10:22:30
预测
这里,我们展示了复现上述预测面板结果的代码。
首先,我们导入Merlion的TimeSeries类和M4数据集的数据加载器。然后我们可以将该数据集中的特定时间序列划分为训练集和测试集。
from merlion.utils import TimeSeries
from ts_datasets.forecast import M4
# 数据加载器返回pandas DataFrame,我们将其转换为Merlion TimeSeries
time_series, metadata = M4(subset="Hourly")[0]
train_data = TimeSeries.from_pd(time_series[metadata.trainval])
test_data = TimeSeries.from_pd(time_series[~metadata.trainval])
然后,我们可以初始化并训练Merlion的DefaultForecaster,这是一个平衡性能和效率的预测模型。我们还获取了它在测试集上的预测结果。
from merlion.models.defaults import DefaultForecasterConfig, DefaultForecaster
model = DefaultForecaster(DefaultForecasterConfig())
model.train(train_data=train_data)
test_pred, test_err = model.forecast(time_stamps=test_data.time_stamps)
接下来,我们可视化模型的预测结果。
import matplotlib.pyplot as plt
fig, ax = model.plot_forecast(time_series=test_data, plot_forecast_uncertainty=True)
plt.show()
最后,我们对模型进行定量评估。sMAPE衡量预测误差,范围从0到100(越低越好),而MSIS评估95%置信区间的质量,范围同样从0到100(越低越好)。
# 定量评估模型的预测结果
from scipy.stats import norm
from merlion.evaluate.forecast import ForecastMetric
# 计算预测的sMAPE(0到100,越小越好)
smape = ForecastMetric.sMAPE.value(ground_truth=test_data, predict=test_pred)
# 计算模型95%置信区间的MSIS(0到100,越小越好)
lb = TimeSeries.from_pd(test_pred.to_pd() + norm.ppf(0.025) * test_err.to_pd().values)
ub = TimeSeries.from_pd(test_pred.to_pd() + norm.ppf(0.975) * test_err.to_pd().values)
msis = ForecastMetric.MSIS.value(ground_truth=test_data, predict=test_pred,
insample=train_data, lb=lb, ub=ub)
print(f"sMAPE: {smape:.4f}, MSIS: {msis:.4f}")
sMAPE: 4.1944, MSIS: 18.9331
评估和基准测试
Merlion的一个关键特性是评估流程,它模拟了模型在历史数据上的实时部署。这使您能够在相关数据集上比较模型,模拟它们在生产环境中可能遇到的情况。我们的评估流程如下:
- 在最近的历史训练数据(指定为时间序列的训练分割)上训练初始模型
- 定期(例如每天一次)在最新数据上重新训练整个模型。这可以是时间序列的全部历史,或者是更有限的窗口(例如4周)
- 获取模型对重新训练之间发生的时间序列值的预测(异常分数或预测)。您可以自定义是批量进行(一次预测所有值),流式进行(每个数据点后更新模型的内部状态而不完全重新训练),或者某种中间频率
- 将模型的预测与真实情况(异常检测的标记异常,或预测的实际时间序列值)进行比较,并报告定量评估指标
我们提供了脚本,允许您使用这个流程在任意数据集上评估任意模型。例如,运行
python benchmark_anomaly.py --dataset NAB_realAWSCloudwatch --model IsolationForest --retrain_freq 1d
将评估IsolationForest(每天重新训练一次)在NAB数据集的"realAWSCloudwatch"子集上的异常检测性能。同样,运行
python benchmark_forecast.py --dataset M4_Hourly --model ETS
将评估ETS在M4数据集的"Hourly"子集上的批量预测性能(即不重新训练)。您可以在技术报告的实验部分找到运行这些脚本产生的结果。
技术报告和引用Merlion
您可以在我们的技术报告中找到更多详情:https://arxiv.org/abs/2109.09265 如果您在研究或应用中使用Merlion,请使用以下BibTeX进行引用:
@article{bhatnagar2021merlion,
title={Merlion: A Machine Learning Library for Time Series},
author={Aadyot Bhatnagar and Paul Kassianik and Chenghao Liu and Tian Lan and Wenzhuo Yang
and Rowan Cassius and Doyen Sahoo and Devansh Arpit and Sri Subramanian and Gerald Woo
and Amrita Saha and Arun Kumar Jagota and Gokulakrishnan Gopalakrishnan and Manpreet Singh
and K C Krithika and Sukumar Maddineni and Daeki Cho and Bo Zong and Yingbo Zhou
and Caiming Xiong and Silvio Savarese and Steven Hoi and Huan Wang},
year={2021},
eprint={2109.09265},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
待办事项
我们正在努力利用GPU进行时间序列建模,以进一步提高Merlion的速度和吞吐量。 敬请期待...











