
EDA-GPT
全方位数据分析工具 支持结构化与非结构化数据探索
EDA-GPT是一款开源数据分析工具,支持结构化和非结构化数据处理。该工具可分析CSV、XLSX、SQLite等格式的结构化数据,以及PDF和图像等非结构化数据。EDA-GPT提供直观界面,集成多种LLM模型,具备图表生成、数据清理和多模态搜索功能。它简化了数据分析流程,有助于用户快速探索数据并获取洞察。




EDA GPT:您的开源数据分析伙伴
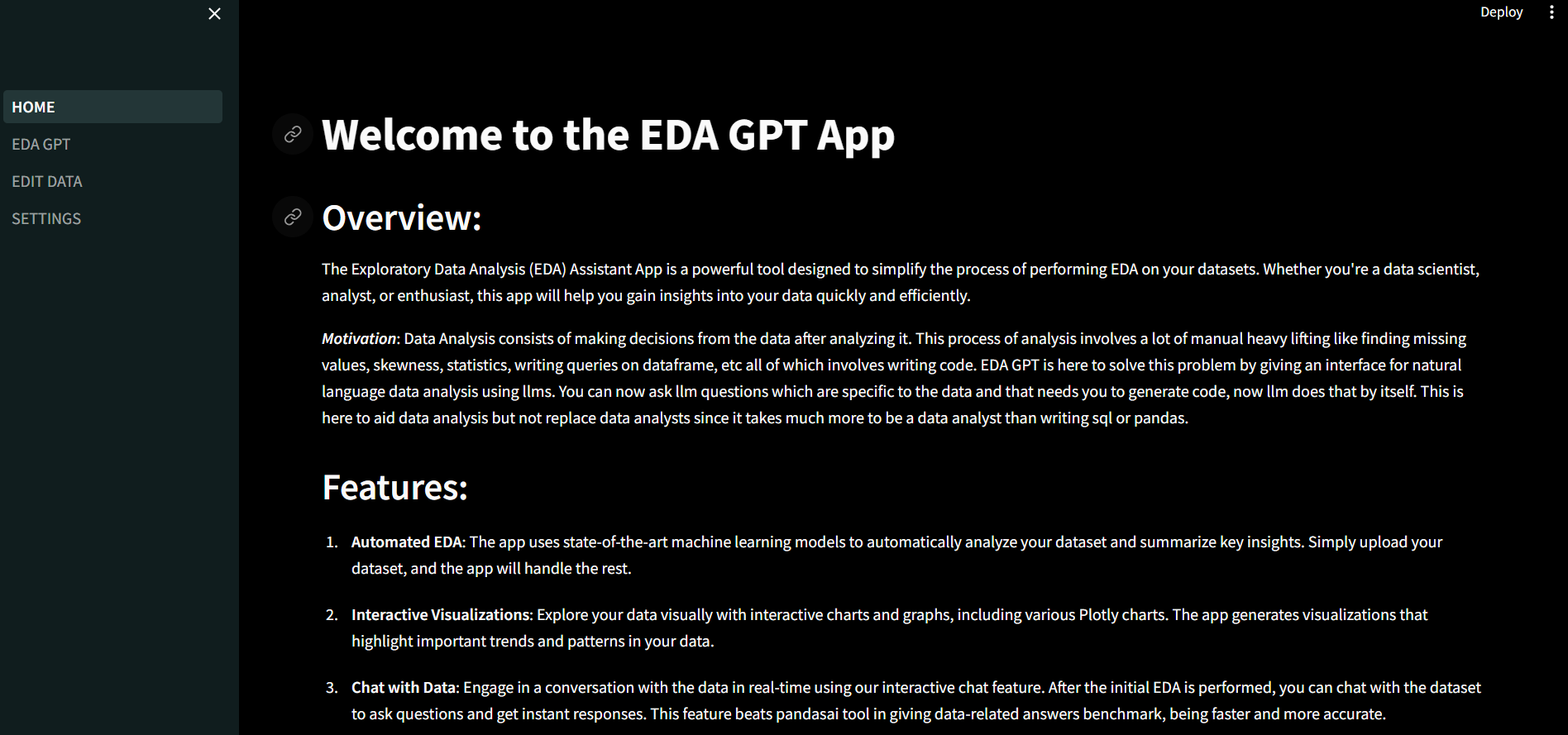
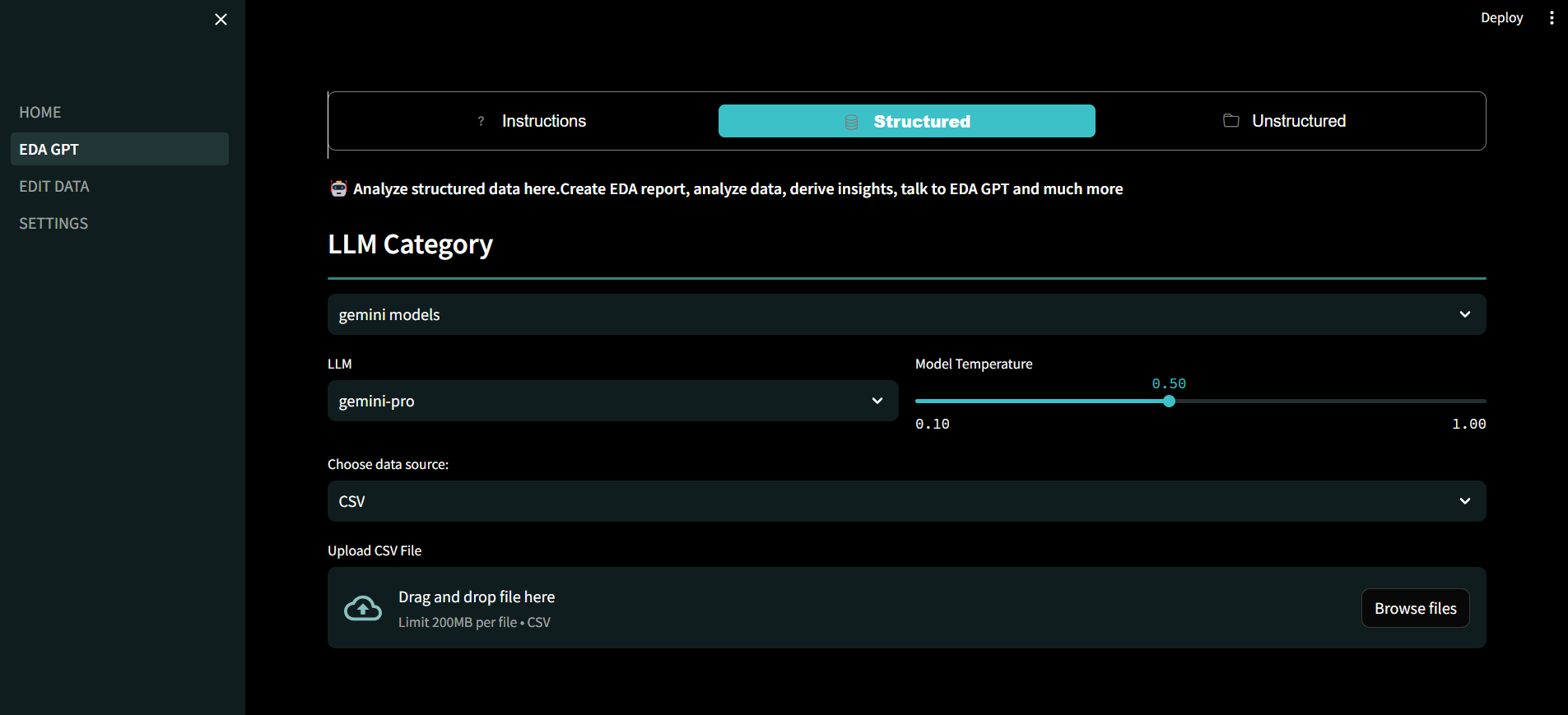
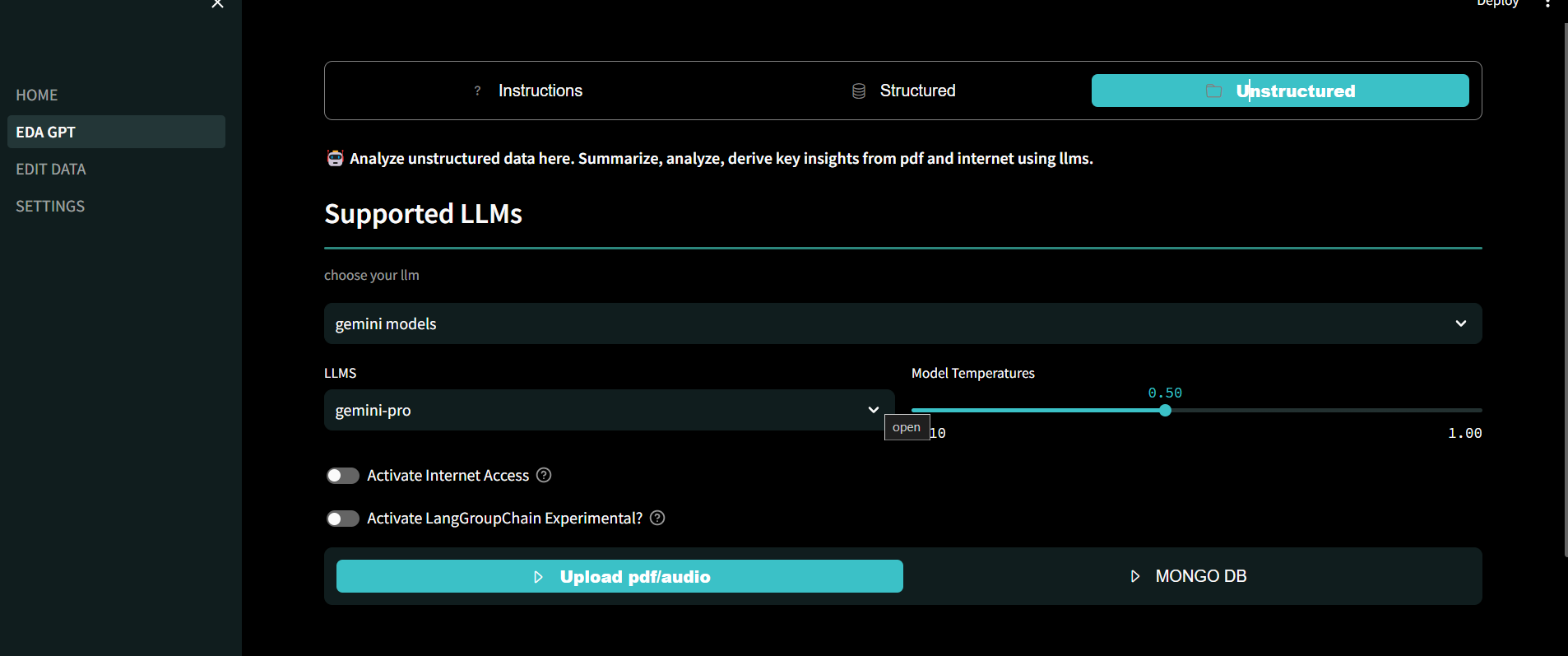
欢迎使用EDA GPT,这是满足您所有数据分析需求的综合解决方案。无论您是分析CSV、XLSX或SQLite格式的结构化数据,生成有洞察力的图表,还是对PDF和图像等非结构化数据进行深入分析,EDA GPT都能在每一步为您提供帮助。
介绍
EDA GPT简化了数据分析过程,使用户能够轻松探索、可视化并从数据中获得洞察。凭借用户友好的界面和强大的功能,EDA GPT使用户能够自信地做出数据驱动的决策。
演示视频:https://genny.lovo.ai/share/d6b58f0d-fc46-4aa7-a65e-fa0f9a684f01
入门
要开始使用EDA GPT,只需导航到应用程序并按照屏幕上的说明操作。上传您的数据,指定分析偏好,然后让EDA GPT处理剩下的工作。凭借其直观的界面和强大的功能,EDA GPT使各种技能水平的用户都能进行数据分析。
如何使用应用程序
-
结构化数据分析:
- 通过上传文件或连接到PostgreSQL等数据库来分析结构化数据。支持csv、xlxs和sqlite格式。
- 提供有关数据的额外背景信息,并详细说明所需结果,以获得更准确的分析。
-
图表生成:
- 通过指定清晰的指令轻松生成各种类型的图表。
- 访问生成的代码以进行微调和自定义。
-
分析问题:
- 在初始EDA之后,在生成的报告基础上提出分析问题。
- 通过Plotly图表和可视化报告获得洞察。
-
性能比较:
- 基于准确性、速度和处理复杂查询的能力比较EDA GPT和pandasai的性能。
xychart-beta title "EDA GPT(蓝色)和PandasAI性能(绿色)比较" x-axis ["准确性", "速度", "复杂查询"] y-axis "得分(满分100)" 0 --> 100 bar EDA_GPT [90, 92, 90] bar PandasAI [85, 90, 70] -
LLMs(大型语言模型):
- 根据数据集特征选择各种LLM。支持HuggingFace、Openai、Groq、Gemini模型。 付费会员可使用Claude3和GPT4。
- 选择LLM时考虑数据集大小和分析复杂性等因素。上下文长度较大的模型通常更适合处理较大的数据集。
-
非结构化数据分析:
- 高效分析非结构化PDF数据。从非结构化数据中推断表格结构和图像,以进行更好的分析。
- 提供详细描述以增强LLM的决策能力。
- 具有互联网访问能力,并遵循行动/观察/思考原则来解决复杂任务。
-
多模态搜索:
- 从包括维基百科、Arxiv、DuckDuckGo和网络爬虫在内的多种来源搜索答案。
- 使用集成的大型视觉模型分析图像。
-
数据清理和编辑:
- 使用EDA GPT提供的各种方法清理和编辑数据。
- 受益于自动化的数据清理过程,节省时间和精力。
主要特点:
-
能够分析大量结构化和非结构化数据。
-
可以分析音频文件、PDF、图像等非结构化数据。还可以分析YouTube视频以总结内容。
-
设计了一个名为Lang Group Chain的特殊类来处理复杂查询。目前它还不稳定,但其架构很有用,可以进一步改进。它本质上将一个主要问题分解为由节点表示的子问题。每个节点都有一些依赖或共同依赖关系。特殊的数据结构LangGroups存储这些Lang节点。这些节点按拓扑顺序排序,并根据相同的入度进行分组。每组都会与先前的上下文一起传递给LLM,以迭代地得出答案。 这种架构对于解决以下类型的问题很有用:求M/3 + 2,其中M是唐纳德·特朗普和乔·拜登的年龄差加上冥王星完成一次公转所需的年数。 注意,我们需要像人类那样形成一系列明确定义的步骤来解决这个问题。 这需要更多的LLM调用。
-
使用多查询和上下文过滤等高级RAG技术来获得更好的结果。在制作嵌入时会提取表格(如果有的话)。
-
在结构化EDA GPT部分,为您提供交互式可视化、pygwalker集成和富有上下文的分析报告。
-
您可以与EDA GPT对话,要求它生成可视化效果,对数据框执行复杂查询,得出洞察,查看特征之间的关系等。所有这些都可以通过自然语言完成。
-
支持多种LLM,考虑到隐私,可以使用ollama模型进行离线分析。
-
实现了自动清理功能,可以根据线性回归等各种参数清理数据。
-
在需要时使用分类模型进行更快的推理,而不是使用LLM进行显式分类。
注意:建议在分析完成后,手动向LLM提供丰富的上下文数据,以获得更好的结果。
建议:Gemini、OpenAI、Claude3和LLAMA 3模型比大多数其他模型效果更好。
系统架构
- 结构化数据EDA
[此处省略mermaid图表代码]
- 非结构化数据EDA
[此处省略mermaid图表代码] embeddings(创建向量嵌入)--|检查结构化数据|-->infer-structure([如果存在则推断表格结构])--同时保存-->docs(文档存储) docs(文档存储)--预处理-->preprocessing([拆分、分块、推断表格、文本数据中的结构]) preprocessing--嵌入-->embed&save(保存到向量存储)--保存-->vstore[(向量嵌入)] 结束
子图 EDAGPT-聊天界面 子图 聊天 chatinterface(与数据对话) -- 用户提问 --> Q&A[Q&A 接口运行] --> clf(分类模型)--|用户问题|-->models
子图 多分类模型
models(模型:随机森林、朴素贝叶斯)--分类-->analysis[分析]
models(模型:随机森林、朴素贝叶斯)--分类-->vision[视觉]
models(模型:随机森林、朴素贝叶斯)--分类-->search[搜索]
结束
结束
子图 分析
analysis[分析]-->datanalyst([从文档回答问题])
datanalyst--请求-->vstore-->docschain(创建stuff-docs链)
结束
子图 视觉
vision[视觉]-->multimodal-LLM(多模态大语言模型)-->result
结束
子图 搜索代理
search[搜索]-->multimodalsearch[多模态搜索代理]-->agents
结束
结束 子图 代理 agents-->funcs{能力}
子图 功能 funcs-->internet([搜索互联网])-->services([Duckduckgo、Tavily、Google]) funcs-->scrape([爬虫]) funcs-->findocs([利用文档])-->datanalyst funcs-->visioncapabilities([利用视觉])-->vision 结束
子图 合并 internet & scrape & findocs & visioncapabilities --> combine([合并结果]) combine([合并结果])-->working[基于思考/行动/观察使用各种工具的排列组合]-->result 结束
结束
为什么在结构化部分使用FAISS作为向量数据库?
- FAISS使用基于倒排文件的索引策略来索引嵌入,适用于10MB到约2GB范围的数据集。对于更高内存需求的数据集,可以使用基于图的索引、混合索引或磁盘索引。对于大多数日常用途,FAISS是一个不错的选择。
- Chroma数据库用于相对较大的文件,文本语料更多(例如:130页的PDF)。它使用层次可导航小世界算法进行索引,这对于执行相似度搜索时的knn算法很有效。
应用程序中的优化?
- EDA GPT针对最大并行处理进行了优化。它并行嵌入大量文档并将它们添加到Chroma中。
- 它针对搜索互联网、文档以及从结构化和非结构化数据创建分析报告进行了大量优化。
- 使用了高阈值的多查询检索、集成检索等先进的检索技术,结合相似度搜索,以获取有用的文档。
- 具有高上下文窗口的大型语言模型(如gemini-pro-1.5)最适合处理大量数据。由于LLM的上下文有限,不建议一次性输入海量数据。我们建议将大型PDF分成较小的PDF(如果可能),并在一个会话中处理独立数据。例如,一个包含超过500万字的1000页PDF应该被分割以提高效率。
- 数据在每个点都进行缓存,以加快推理速度。
EDA GPT结构化数据分析示例:
- 笔记本链接:https://colab.research.google.com/drive/1vqMTPWeSlF7iYG06PFkrYw9lxcnrrmaE?usp=sharing#scrollTo=9dzFcTeY53eG
要深入了解应用程序,请查看[低级设计文档(Markdown格式)](pages/src/Database/assets/LLD.md)和[高级设计PDF](pages/src/Database/assets/HLD.pdf)
如何启动应用程序
要使用此应用程序,请按以下步骤操作:
1. **克隆仓库**:
```bash
git clone https://github.com/shaunthecomputerscientist/EDA-GPT.git
cd EDA-GPT
2. **创建虚拟环境并安装依赖项**:
```bash
pip install -r requirements.txt
3. **在.streamlit文件夹内设置secrets.toml**:

### 您可以参考所有服务的文档来创建API密钥。
4. **启动应用程序**:
```bash
streamlit run Home.py
反馈和支持 我们重视您的反馈,并不断努力改进EDA GPT。如果您遇到任何问题或有改进建议,请随时联系我们的支持团队。开发者联系方式:mrpolymathematica@gmail.com
重要说明:本项目是作为ineuron实习项目的一部分在一个月内完成的。
编辑推荐精选


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效��工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。


TRELLIS
用于可扩展和多功能 3D 生成的结构化 3D 潜在表示
TRELLIS 是一个专注于 3D 生成的项目,它利用结构化 3D 潜在表示技术,实现了可扩展且多功能的 3D 生成。项目提供了多种 3D 生成的方法和工具,包括文本到 3D、图像到 3D 等,并且支持多种输出格式,如 3D 高斯、辐射场和网格等。通过 TRELLIS,用户可以根据文本描述或图像输入快速生成高质量的 3D 资产,适用于游戏开发、动画制作、虚拟现实等多个领域。


ai-agents-for-beginners
10 节课教你开启构建 AI 代理所需的一切知识
AI Agents for Beginners 是一个专为初学者打造的课程项目,提供 10 节课程,涵盖构建 AI 代理的必备知识,支持多种语言,包含规划设计、工具使用、多代理等丰富内容,助您快速入门 AI 代理领域。


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供��了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号