
 Github
Github 论文
论文用于图像复原的交叉聚合Transformer
Zheng Chen、Yulun Zhang、Jinjin Gu、Yongbing Zhang、Linghe Kong和Xin Yuan,"用于图像复原的交叉聚合Transformer",NeurIPS 2022(聚焦报告)
[论文] [arXiv] [补充材料] [可视化结果] [预训练模型]
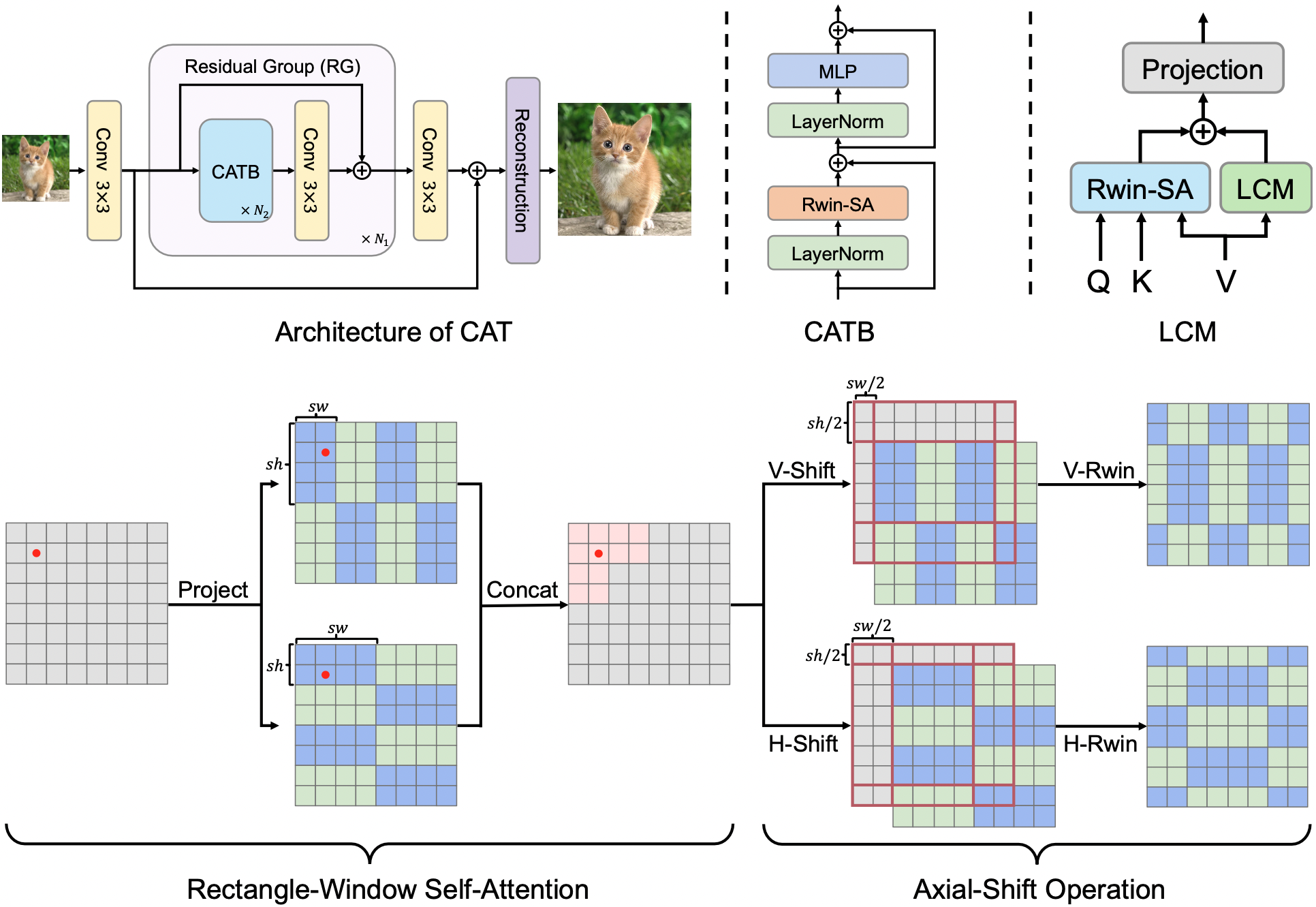
摘要: 近来,Transformer架构被引入图像复原领域,取代卷积神经网络(CNN)并取得了惊人的结果。考虑到Transformer全局注意力的高计算复杂度,一些方法使用局部方形窗口来限制自注意力的范围。然而,这些方法缺乏不同窗口之间的直接交互,限制了建立长程依赖关系。为解决上述问题,我们提出了一种新的图像复原模型,即交叉聚合Transformer(CAT)。我们CAT的核心是矩形窗口自注意力(Rwin-SA),它在不同的头部并行使用水平和垂直矩形窗口注意力来扩展注意力区域,并聚合跨不同窗口的特征。我们还引入了轴向移位操作以实现不同窗口之间的交互。此外,我们提出了局部互补模块来补充自注意力机制,该模块将CNN的归纳偏置(如平移不变性和局部性)融入Transformer,实现全局-局部耦合。大量实验表明,我们的CAT在多个图像复原应用上优于最近的最先进方法。
| 超分辨率 (x4) | 高质量 | 低质量 | SwinIR | CAT (我们的方法) |
|---|---|---|---|---|
 |  |  |  |  |
 |  |  |  |  |
依赖项
- Python 3.8
- PyTorch 1.8.0
- NVIDIA GPU + CUDA
# 克隆GitHub仓库并进入默认目录'CAT'。
git clone https://github.com/zhengchen1999/CAT.git
conda create -n CAT python=3.8
conda activate CAT
pip install -r requirements.txt
python setup.py develop
待办事项
- 图像超分辨率
- JPEG压缩伪影消除
- 图像去噪
- 其他任务
目录
数据集
可以按如下方式下载使用的训练和测试集:
| 任务 | 训练集 | 测试集 | 可视化结果 |
|---|---|---|---|
| 图像超分辨率 | DIV2K (800张训练图像,100张验证图像) + Flickr2K (2650张图像) [完整训练数据集 DF2K] | Set5 + Set14 + BSD100 + Urban100 + Manga109 [完整测试数据集 下载] | 点击这里 |
| 灰度JPEG压缩伪影去除 | DIV2K (800张训练图像) + Flickr2K (2650张图像) + WED(4744张图像) + BSD500 (400张训练和测试图像) [完整训练数据集 DFWB] | Classic5 + LIVE + Urban100 [完整测试数据集 下载] | 点击这里 |
| 真实图像去噪 | SIDD (320张训练图像) [完整训练数据集 SIDD] | SIDD + DND [完整测试数据集 下载] | 点击这里 |
这里的可视化结果是在超分辨率(x4)、JPEG压缩伪影去除(q10)和真实图像去噪条件下生成的。
下载训练和测试数据集并将它们放入datasets/和restormer/datasets对应的文件夹中。查看datasets了解详细的目录结构。
模型
| 任务 | 方法 | 参数量(M) | FLOPs(G) | 数据集 | PSNR(dB) | SSIM | 模型库 | 可视化结果 |
|---|---|---|---|---|---|---|---|---|
| 超分辨率 | CAT-R | 16.60 | 292.7 | Urban100 | 27.45 | 0.8254 | Google Drive | Google Drive |
| 超分辨率 | CAT-A | 16.60 | 360.7 | Urban100 | 27.89 | 0.8339 | Google Drive | Google Drive |
| 超分辨率 | CAT-R-2 | 11.93 | 216.3 | Urban100 | 27.59 | 0.8285 | Google Drive | Google Drive |
| 超分辨率 | CAT-A-2 | 16.60 | 387.9 | Urban100 | 27.99 | 0.8357 | Google Drive | Google Drive |
| 压缩伪影去除 | CAT | 16.20 | 346.4 | LIVE1 | 29.89 | 0.8295 | Google Drive | Google Drive |
| 真实图像去噪 | CAT | 25.77 | 53.2 | SIDD | 40.01 | 0.9600 | Google Drive | Google Drive |
| 性能报告基于Urban100(x4,超分辨率),LIVE1(q=10,压缩伪影去除)和SIDD(真实图像去噪)数据集。FLOPs测试的输入大小为128 x 128。 |
训练
图像超分辨率
-
进入'CAT'目录并运行安装脚本。
# 如果已在CAT目录并完成安装,请忽略 python setup.py develop -
下载训练集(DF2K,已预处理)和测试集(Set5、Set14、BSD100、Urban100、Manga109,已预处理),将它们放在
datasets/目录下。 -
运行以下脚本。训练配置在
options/train/目录中。# CAT-R,超分辨率,输入=64x64,4个GPU python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_R_sr_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_R_sr_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_R_sr_x4.yml --launcher pytorch # CAT-A,超分辨率,输入=64x64,4个GPU python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_A_sr_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_A_sr_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_A_sr_x4.yml --launcher pytorch # CAT-R-2,超分辨率,输入=64x64,4个GPU python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_R_2_sr_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_R_2_sr_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_R_2_sr_x4.yml --launcher pytorch # CAT-A-2,超分辨率,输入=64x64,4个GPU python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_A_2_sr_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_A_2_sr_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_A_2_sr_x4.yml --launcher pytorch -
训练实验结果保存在
experiments/目录中。
JPEG压缩伪影去除
-
进入'CAT'目录并运行安装脚本
# 如果已在CAT目录并完成安装,请忽略 python setup.py develop -
下载训练集(DFWB,已预处理)和测试集(Classic5、LIVE1、Urban100,已预处理),将它们放在
datasets/目录下。 -
运行以下脚本。训练配置在
options/train/目录中。# CAT,压缩伪影去除,输入=128x128,4个GPU python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_car_q10.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_car_q20.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_car_q30.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_CAT_car_q40.yml --launcher pytorch -
训练实验结果保存在
experiments/目录中。
真实图像去噪
-
进入'CAT/restormer'目录并运行安装脚本
# 如果已在restormer目录并完成安装,请忽略 python setup.py develop --no_cuda_ext -
下载训练集(SIDD-train,包含验证集,已预处理),将它们放在
datasets/(restormer/datasets/)目录下。 -
运行以下脚本。训练配置在
options/(restormer/options/)目录中。# CAT,真实图像去噪,渐进学习,8个GPU python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/train_RealDenoising_CAT.yml --launcher pytorch -
训练实验结果保存在
experiments/(restormer/experiments/)目录中。
测试
图像超分辨率
-
进入'CAT'目录并运行安装脚本
# 如果已在CAT目录并完成安装,请忽略 python setup.py develop -
下载预训练模型并将它们放在
experiments/pretrained_models/目录下。我们提供了图像超分辨率的预训练模型:CAT-R、CAT-A、CAT-A和CAT-R-2(x2、x3、x4)。
-
下载测试集(Set5、Set14、BSD100、Urban100、Manga109,已预处理),将它们放在
datasets/目录下。 -
运行以下脚本。测试配置在
options/test/目录中(例如,test_CAT_R_sr_x2.yml)。注1:您可以在YML文件中设置
use_chop: True(默认为False)以对图像进行分块测试。
# 无自集成
# CAT-R, SR, 复现主论文表2的结果
python basicsr/test.py -opt options/test/test_CAT_R_sr_x2.yml
python basicsr/test.py -opt options/test/test_CAT_R_sr_x3.yml
python basicsr/test.py -opt options/test/test_CAT_R_sr_x4.yml
# CAT-A, SR, 复现主论文表2的结果
python basicsr/test.py -opt options/test/test_CAT_A_sr_x2.yml
python basicsr/test.py -opt options/test/test_CAT_A_sr_x3.yml
python basicsr/test.py -opt options/test/test_CAT_A_sr_x4.yml
# CAT-R-2, SR, 复现补充材料表1的结果
python basicsr/test.py -opt options/test/test_CAT_R_2_sr_x2.yml
python basicsr/test.py -opt options/test/test_CAT_R_2_sr_x3.yml
python basicsr/test.py -opt options/test/test_CAT_R_2_sr_x4.yml
# CAT-A-2, SR, 复现补充材料表1的结果
python basicsr/test.py -opt options/test/test_CAT_A_2_sr_x2.yml
python basicsr/test.py -opt options/test/test_CAT_A_2_sr_x3.yml
python basicsr/test.py -opt options/test/test_CAT_A_2_sr_x4.yml
- 输出结果在
results/目录下。
JPEG压缩伪影消除
- 进入'CAT'目录并运行安装脚本
# 如果已经在CAT目录下并完成设置,请忽略此步骤
python setup.py develop
-
下载预训练模型并将其放在
experiments/pretrained_models/目录下。我们提供了用于JPEG压缩伪影消除的预训练模型:CAT (q10, q20, q30, q40)。
-
下载测试数据集(Classic5、LIVE、Urban100,已处理),将其放在
datasets/目录下。 -
运行以下脚本。测试配置文件在
options/test/目录下(例如,test_CAT_car_q10.yml)。
# 无自集成
# CAT-A, CAR, 复现主论文表3的结果
python basicsr/test.py -opt options/test/test_CAT_car_q10.yml
python basicsr/test.py -opt options/test/test_CAT_car_q20.yml
python basicsr/test.py -opt options/test/test_CAT_car_q30.yml
python basicsr/test.py -opt options/test/test_CAT_car_q40.yml
- 输出结果在
results/目录下。
真实图像去噪
- 进入'CAT'目录并运行安装脚本
# 如果已经在CAT目录下并完成设置,请忽略此步骤
python setup.py develop
-
下载预训练模型并将其放在
experiments/pretrained_models/目录下。 -
下载测试数据集(SIDD、DND),将其放在
datasets/目录下。 -
运行以下脚本。测试配置文件在
options/test/目录下。
# 无自集成
# CAT, 真实DN, 复现主论文表4的结果
# 在SIDD上测试
python test_real_denoising_sidd.py --save_images
evaluate_sidd.m
# 在DND上测试
python test_real_denoising_dnd.py --save_images
- 输出结果在
results/目录下。
结果
我们在图像超分辨率、JPEG压缩伪影消除和真实图像去噪方面取得了最先进的性能。详细结果可以在论文中找到。CAT的所有可视化结果可以在这里下载。
图像超分辨率(点击展开)
- 主论文表2的结果

- 补充材料表1的结果

- 主论文中的视觉对比(x4)

- 补充材料中的视觉对比(x4)



JPEG压缩伪影消除(点击展开)
- 主论文表3的结果

- 补充材料表3的结果(在Urban100上测试)

- 主论文中的视觉对比(q=10)

- 补充材料中的视觉对比(q=10)



真实图像去噪(点击展开)
- 主论文表4中的结果

*: 我们使用所有官方预训练模型重新测试了SIDD。
引用
如果您发现此代码对您的研究或工作有帮助,请引用以下论文。
@inproceedings{chen2022cross,
title={Cross Aggregation Transformer for Image Restoration},
author={Chen, Zheng and Zhang, Yulun and Gu, Jinjin and Zhang, Yongbing and Kong, Linghe and Yuan, Xin},
booktitle={NeurIPS},
year={2022}
}











