




🔒 PrivateGPT 📑




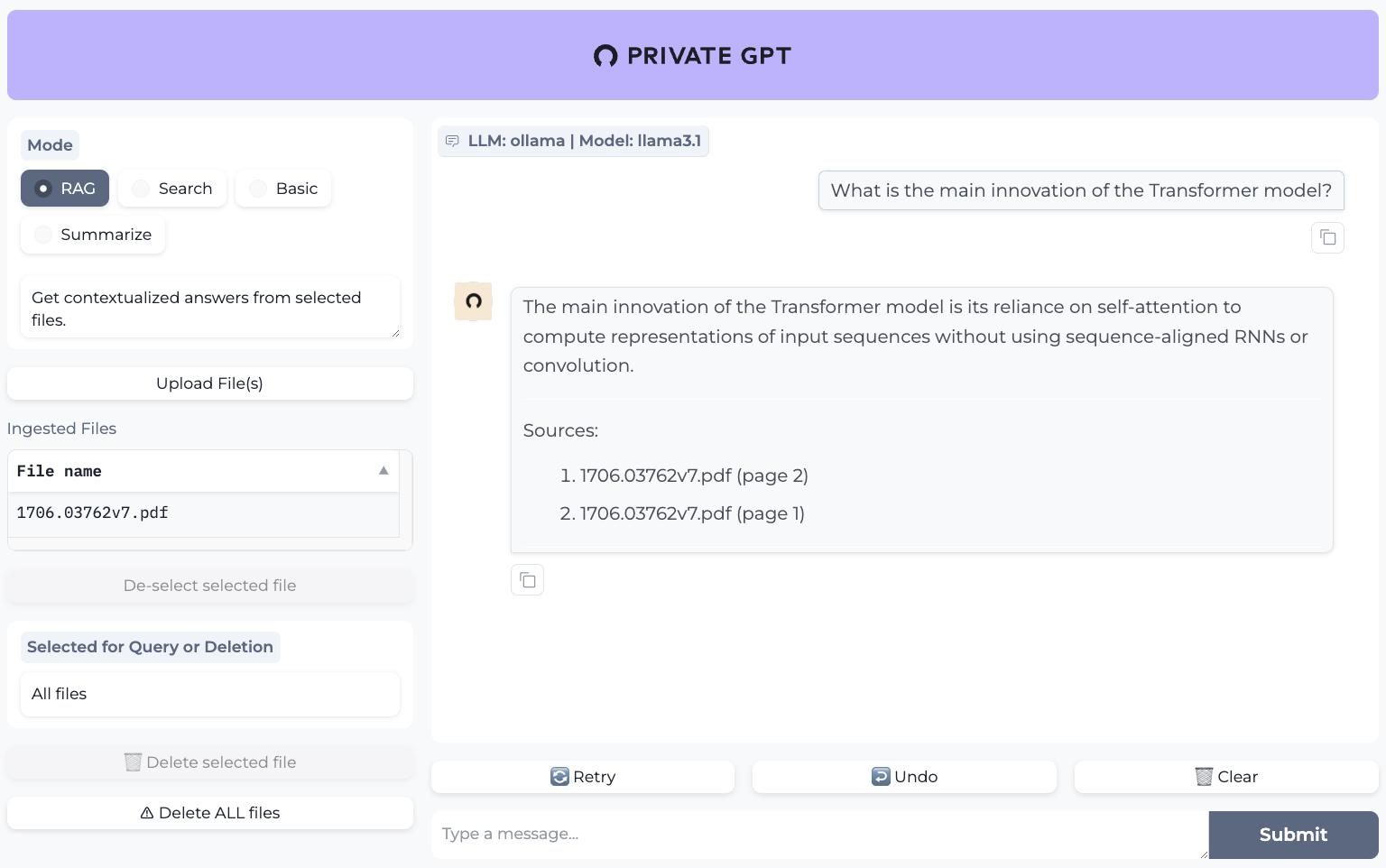
PrivateGPT是一个可用于生产环境的AI项目,它允许您利用大型语言模型(LLMs)的能力来询问有关您文档的问题,即使在没有互联网连接的情况下也能使用。100%私密,数据在任何时候都不会离开您的执行环境。
[!提示] 如果您正在寻找一个企业级、完全私密的AI工作空间, 请查看Zylon的网站或申请演示。 Zylon由PrivateGPT背后的团队精心打造,是一个一流的AI协作工作空间, 可以轻松部署在本地(数据中心、裸机等)或您的私有云(AWS、GCP、Azure等)上。
该项目提供了一个API,提供了构建私密、上下文感知的AI应用所需的所有基本功能。它遵循并扩展了OpenAI API标准,支持普通和流式响应。
API分为两个逻辑块:
高级API,抽象了RAG(检索增强生成)管道实现的所有复杂�性:
- 文档摄入:内部管理文档解析、分割、元数据提取、嵌入生成和存储。
- 使用摄入文档的上下文进行聊天和完成:抽象了上下文检索、提示工程和响应生成。
低级API,允许高级用户实现自己的复杂管道:
- 嵌入生成:基于一段文本。
- 上下文块检索:给定一个查询,返回摄入文档中最相关的文本块。
除此之外,还提供了一个可用的Gradio UI客户端来测试API,以及一套有用的工具,如批量模型下载脚本、摄入脚本、文档文件夹监视等。
🎞️ 概述
[!警告] 本README的更新频率不及文档。 请查看文档以获取最新更新!
PrivateGPT的动机
生成式AI对我们的社会来说是一个游戏规则改变者,但在各种规模的公司以及数据敏感领域(如医疗保健或法律)中的应用受到一个明确的担忧限制:隐私。 在使用第三方AI工具时无法确保您的数据完全在您的控制之下,这是那些行业无法承担的风险。
原始版本
PrivateGPT的第一个版本于2023年5月推出,是一种通过完全离线方式使用LLMs来解决隐私问题的新方法。
那个版本迅速成为隐私敏感设置的首选项目,并为数千个本地化的生成式AI项目提供了种子。它是PrivateGPT现在发展的基础;因此是一个更简单、更具教育意义的实现,用于理解构建完全本地化(因此是私密的)类似chatGPT工具所需的基本概念。
如果您想继续尝试它,我们已经将其保存在项目的primordial分支中。
如果您来自之前的原始版本,强烈建议您对PrivateGPT的这个新版本进行全新的克隆和安装。
PrivateGPT的现在和未来
PrivateGPT现在正在发展成为生成式AI模型和基本功能的网关,包括完成、文档摄入、RAG管道和其他低级构建块。我们希望让任何开发者更容易构建AI应用和体验,并为社区提供一个合适的可扩展架构以继续贡献。
请关注我们的发布以查看所有包含的新功能和变更。
📄 文档
有关安装、依赖、配置、运行服务器、部署选项、摄入本地文档、API详情和UI功能的完整文档可以在这里找到:https://docs.privategpt.dev/
🧩 架构
从概念上讲,PrivateGPT是一个封装RAG管道并公开其基本功能的API。
- API使用FastAPI构建,并遵循OpenAI的API方案。
- RAG管道基于LlamaIndex。
PrivateGPT的设计允许轻松扩展和适应API和RAG实现。一些关键的架构决策包括:
- 依赖注入,解耦不同的组件和层。
- 使用LlamaIndex的抽象,如
LLM、BaseEmbedding或VectorStore,使得更换这些抽象的实际实现变得简单。 - 简单性,尽可能少地添加新的层和抽象。
- 即用即取,提供API和RAG管道的完整实现。
主要构建块:
- API在
private_gpt:server:<api>中定义。每个包都包含一个<api>_router.py(FastAPI层)和一个<api>_service.py(服务实现)。每个Service使用LlamaIndex的基本抽象而不是特定实现,将实际实现与其使用解耦。 - 组件放置在
private_gpt:components:<component>中。每个Component负责为Service中使用的基本抽象提供实际实现 - 例如LLMComponent负责提供LLM的实际实现(例如LlamaCPP或OpenAI)。
💡 贡献
欢迎贡献!为确保代码质量,我们启用了多项格式和类型检查,只需在提交前运行make check以确保您的代码没有问题。
记得测试您的代码!您会在tests文件夹中找到帮助程序,并且可以使用make test命令运行测试。
不知道贡献什么?这里是公开的项目看板,其中有几个想法。
前往Discord的#contributors频道,申请对该GitHub项目的写入权限。
💬 社区
加入PrivateGPT的对话:
📖 引用
如果您在论文中使用PrivateGPT,请查看Citation文件以获取正确的引用方式。 您也可以使用此仓库中的"引用此仓库"按钮以获取不同格式的引用。
以下是几个例子:
BibTeX
@software{Zylon_PrivateGPT_2023, author = {Zylon by PrivateGPT}, license = {Apache-2.0}, month = may, title = {{PrivateGPT}}, url = {https://github.com/zylon-ai/private-gpt}, year = {2023} }
APA
Zylon by PrivateGPT (2023). PrivateGPT [Computer software]. https://github.com/zylon-ai/private-gpt
🤗 合作伙伴与支持者
PrivateGPT得到以下团队的积极支持:
- Qdrant,提供默认的向量数据库
- Fern,提供文档和SDK
- LlamaIndex,提供基础RAG框架和抽象
这个项目受到其他优秀项目的强烈影响和支持,如 LangChain、 GPT4All、 LlamaCpp、 Chroma 和SentenceTransformers。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音�的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的�事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号