
3D变形注意力机制:提升2D到3D特征映射效果的新方法
近年来,自动驾驶等领域对3D目标检测的需求日益增长。然而,如何从2D图像特征有效地提取3D信息仍然是一个具有挑战性的问题。为此,来自IDEA研究院的研究人员提出了一种新的算子 - 3D变形注意力(DFA3D),用于2D到3D特征映射,以提升3D目标检测的性能。
DFA3D的创新之处
传统的2D到3D特征映射方法主要有两类:
-
基于Lift-Splat的方法:利用估计的深度生成伪激光雷达特征,然后将其映射到3D空间。这类方法是单向操作,无法对特征进行进一步细化。
-
基于2D注意力的方法:忽略深度信息,直接通过2D注意力机制进行特征映射。虽然可以获得更精细的语义信息,但存在深度歧义问题。
相比之下,DFA3D结合了上述两种方法的优点:
- 首先利用估计的深度将每个视图的2D特征图扩展到3D空间
- 然后使用DFA3D从扩展的3D特征图中聚合特征
这种设计有两个主要优势:
- 从根本上缓解了深度歧义问题
- 借助类似Transformer的架构,可以逐层细化提取的特征
DFA3D的工作原理
DFA3D的核心思想是将2D注意力机制扩展到3D空间。具体来说:
- 对每个查询位置,DFA3D会在3D空间中采样多个参考点
- 这些参考点被投影回多视图2D图像,以获取相应的图像特征
- 通过注意力机制对这些特征进行加权聚合,得到最终的3D特征
此外,研究人员还提出了DFA3D的等效实现,可以显著提高其内存效率和计算速度。
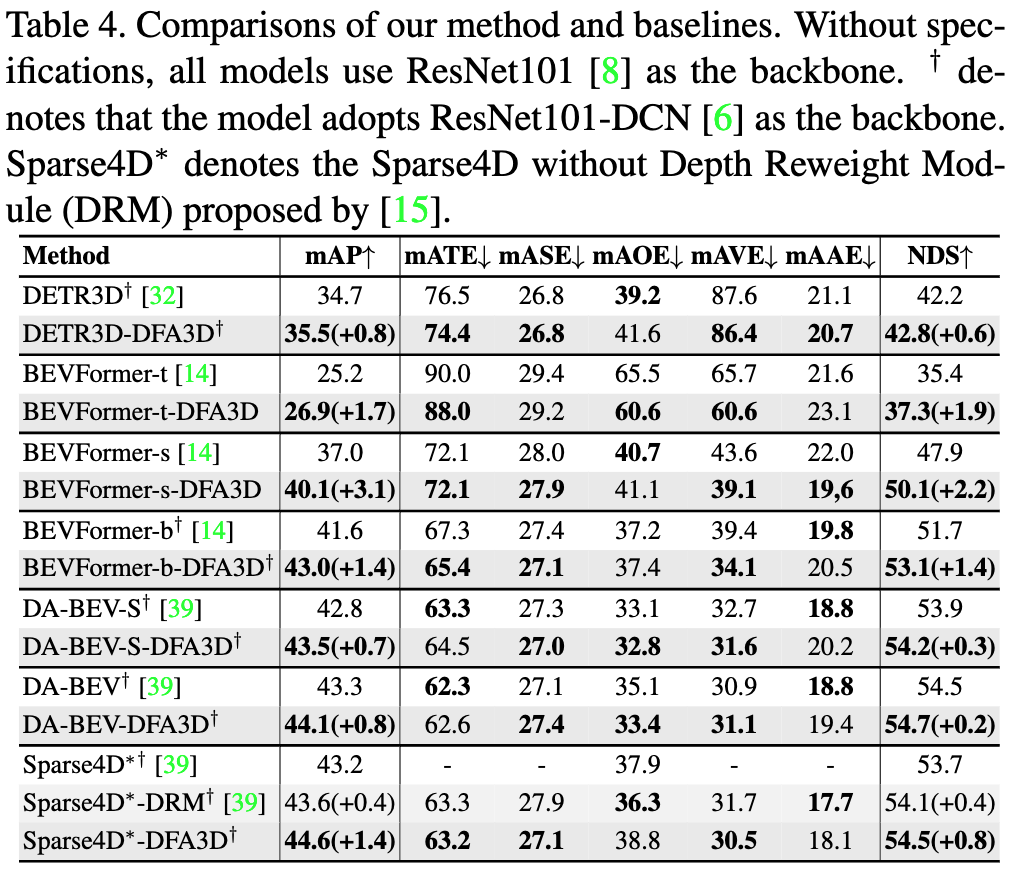
实验结果
研究人员将DFA3D集成到多个使用2D注意力进行特征映射的方法中,并在nuScenes数据集上进行了评估。实验结果表明:
- DFA3D在平均mAP指标上带来了+1.41的一致性提升
- 当有高质量深度信息可用时,提升幅度可达+15.1 mAP
这充分证明了DFA3D的优越性、适用性和巨大潜力。
应用示例:BEVFormer-DFA3D
为了展示DFA3D的实际效果,研究人员基于BEVFormer开发了DFA3D增强版本。相比原版BEVFormer,BEVFormer-DFA3D在多个指标上都有显著提升:
- BEVFormer-base: mAP从41.6提升到43.2 (+1.6), NDS从51.7提升到53.2 (+1.5)
- BEVFormer-small: mAP从37.0提升到40.3 (+3.3), NDS从47.9提升到50.9 (+3.0)
特别是当使用地面真实深度信息时,BEVFormer-base-DFA3D-GTDepth可以将mAP和NDS分别提升16.0和11.9个百分点,达到57.6和63.6的高性能。
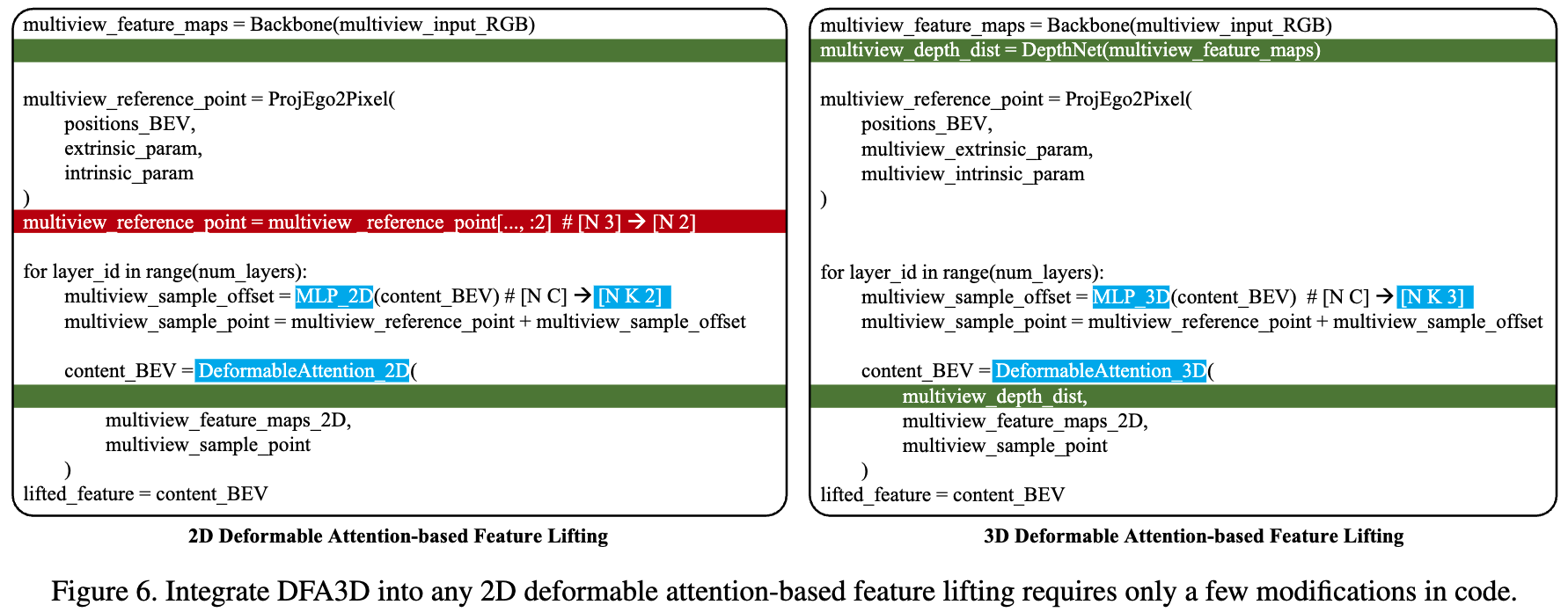
实现细节
将现有的2D注意力特征映射方法转换为基于DFA3D的方法只需要少量代码修改。以2D可变形注意力为例,主要修改包括:
- 将2D参考点坐标扩展为3D坐标
- 修改采样偏移量的计算方式
- 调整注意力权重的计算
总结与展望
3D变形注意力(DFA3D)为2D到3D特征映射提供了一种新的范式。通过结合深度估计和特征聚合,DFA3D有效缓解了深度歧义问题,并能逐层细化提取的特征。实验结果表明,DFA3D在多个基线方法上都带来了显著性能提升,尤其是在高质量深度信息可用时提升更为明显。
未来,研究人员计划进一步完善DFA3D,包括:
- 发布更多DFA3D增强的模型,如BEVFormer-DFA3D-PredDepth等
- 开发3D注意力可视化工具
- 改进深度图准备流程
DFA3D的出现为3D目标检测等任务开辟了新的可能性。随着进一步的优化和应用,相信这项技术将在自动驾驶、机器人视觉等领域发挥重要作用。
参考资料
- DFA3D项目GitHub: https://github.com/IDEA-Research/3D-deformable-attention
- 论文: DFA3D: 3D Deformable Attention For 2D-to-3D Feature Lifting
- BEVFormer项目: https://github.com/fundamentalvision/BEVFormer
如果您对3D变形注意力机制感兴趣,欢迎访问项目GitHub页面获取更多信息,并尝试将其应用到您自己的项目中。DFA3D为2D到3D特征映射带来了新的可能,相信随着进一步的发展,它将在计算机视觉领域发挥越来越重要的作用。









