
AgentBench简介
AgentBench是由清华大学等机构开发的首个系统评估LLM作为Agent能力的基准测试。它包含8个不同的环境,覆盖了操作系统、数据库、知识图谱、卡牌游戏等多个领域,全面评估LLM在各种场景下作为智能体的表现。
主要特点
- 多样化环境:包含8个不同任务环境,全面评估LLM能力
- 开源代码:在GitHub上开源,方便研究者使用和扩展
- 详细文档:提供了完整的使用说明和扩展指南
- 排行榜:展示了各种LLM模型在AgentBench上的表现
快速上手
要开始使用AgentBench,可以按照以下步骤操作:
-
克隆GitHub仓库:
git clone https://github.com/THUDM/AgentBench.git -
安装依赖:
cd AgentBench pip install -r requirements.txt -
配置模型和任务
-
运行评估
详细的配置和运行说明可以参考官方文档。
学习资源
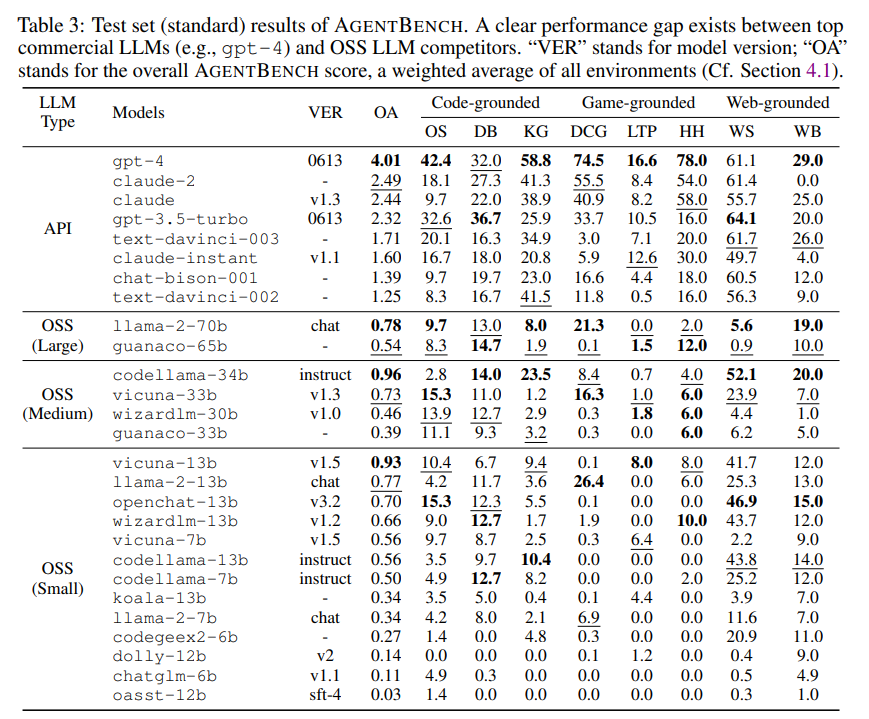
扩展AgentBench
如果你想为AgentBench添加新的任务或环境,可以参考扩展指南。这为研究者提供了很大的灵活性,可以根据自己的需求定制评估环境。
总结
AgentBench为评估LLM作为智能体的能力提供了一个全面而强大的工具。通过学习和使用AgentBench,研究者和开发者可以更好地理解和改进LLM在实际应用场景中的表现。随着更多模型被评估和新的任务环境被添加,AgentBench将继续推动LLM作为Agent领域的发展。










