
引言
随着人工智能和机器学习技术的迅速发展,图像处理领域正经历着革命性的变革。传统的图像处理方法正逐步被基于深度学习的智能算法所取代,为图像分析和处理带来了前所未有的可能性。本文将探讨人工智能和机器学习在图像处理中的融合应用,涵盖从基础的图像增强到复杂的目标检测等多个方面。
图像增强
图像增强是图像处理中最基本也是最常用的技术之一,目的是改善图像质量,突出图像中的重要信息。传统的图像增强方法主要依赖于对比度调整、亮度调整等基本操作,而基于深度学习的方法则能够实现更加智能和高效的图像增强。
对比度和亮度调整
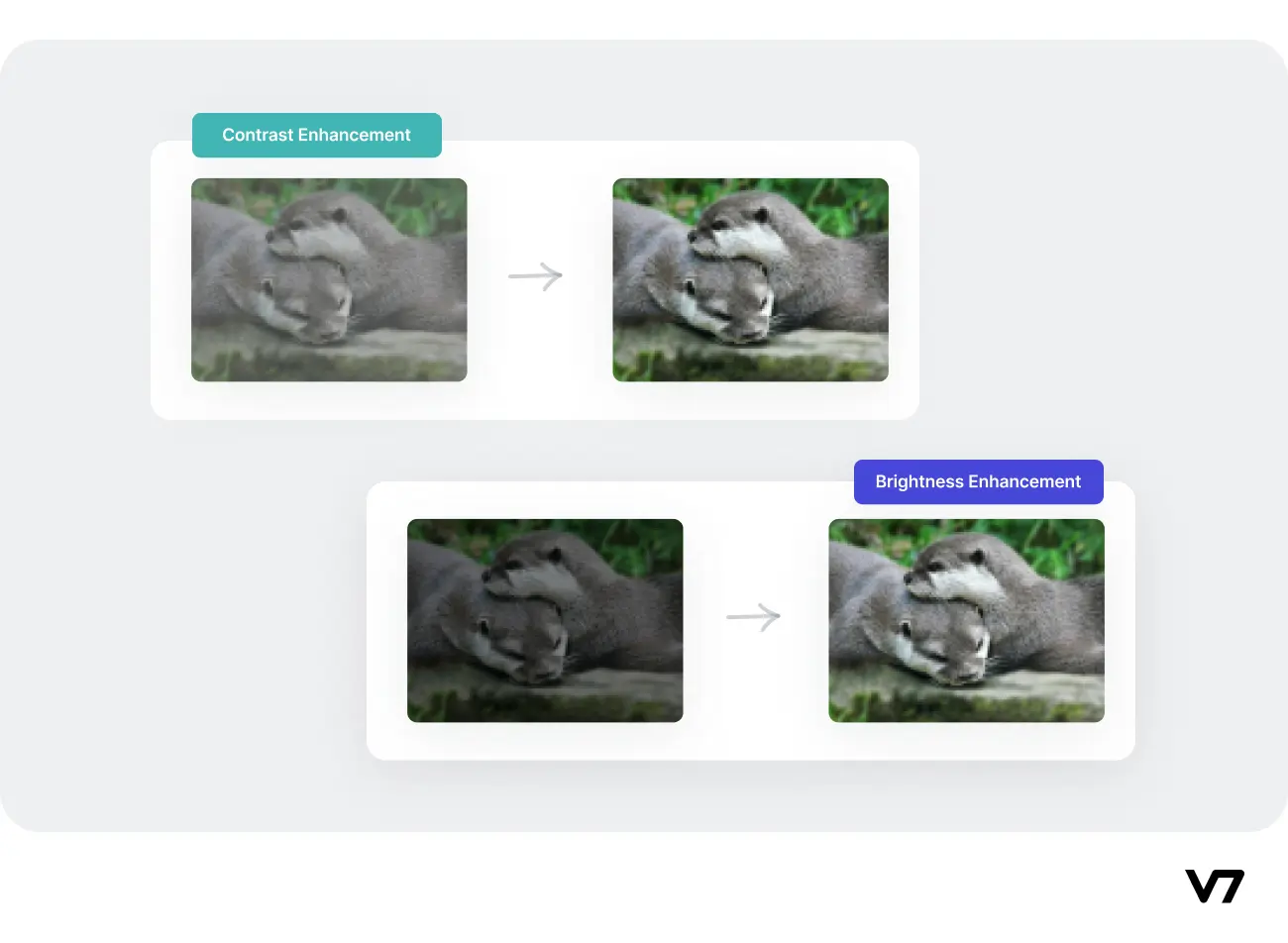
对比度是指图像最亮和最暗区域之间的亮度差异。通过增加对比度,可以提高图像的整体亮度,使图像更容易被观察。亮度则是指图像的整体明暗程度。大多数图像编辑软件都提供了自动或手动调整对比度和亮度的功能。
超分辨率重建
超分辨率重建是一种更为先进的图像增强技术,旨在从低分辨率图像中重建高分辨率图像。这项技术在处理像素密度较低的图像时特别有用。深度学习模型,如SRCNN (Super-Resolution Convolutional Neural Network),在这一领域取得了显著成果。
SRCNN模型的工作流程如下:
- 首先使用传统的双三次插值法对低分辨率图像进行上采样
- 将上采样后的图像输入CNN模型
- CNN模型通过非线性映射提取图像特征
- 最后通过卷积层重建高分辨率图像
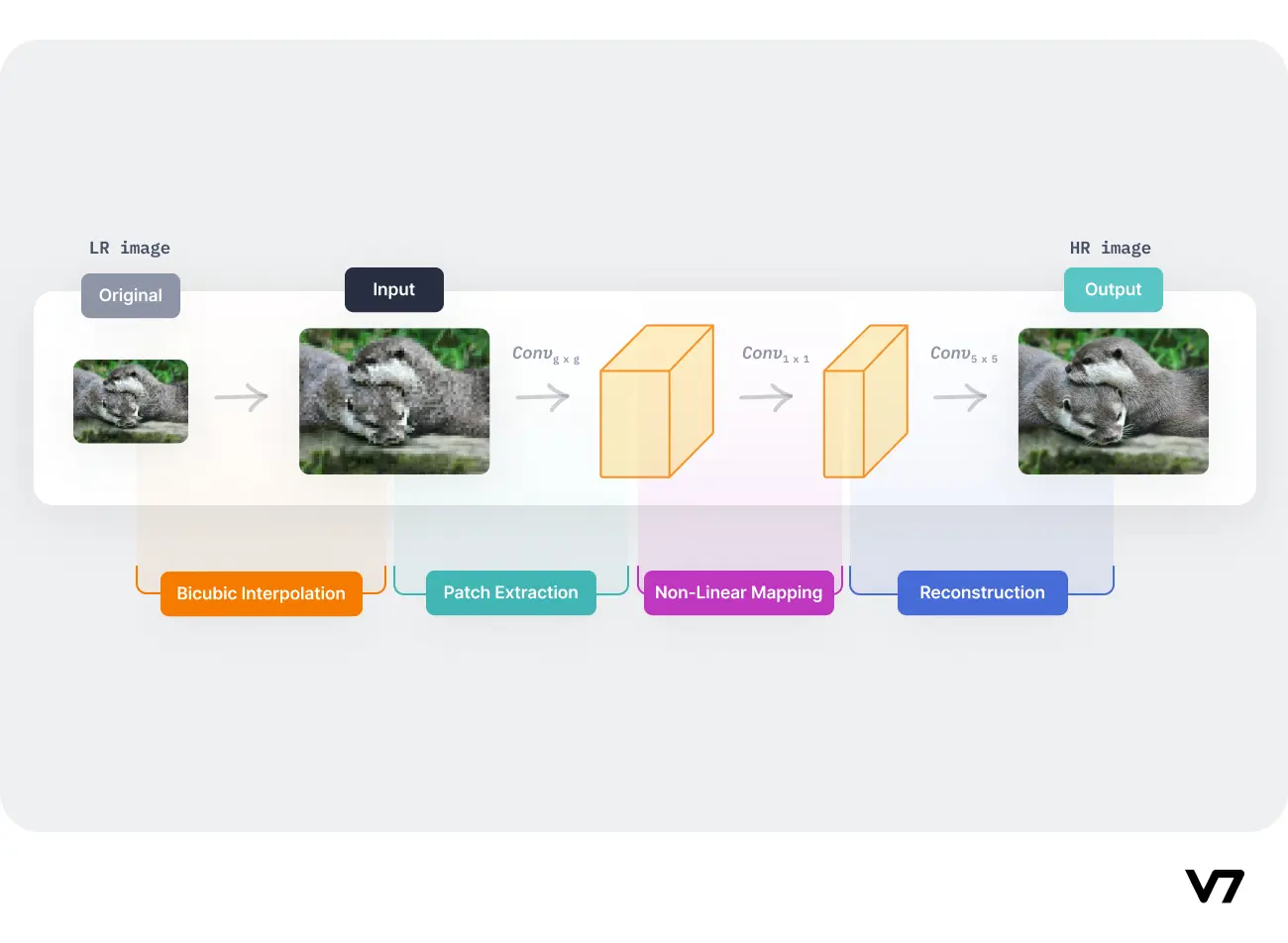
SRCNN模型相比传统方法在图像质量上有明显提升,为超分辨率重建开辟了新的研究方向。
图像复原
图像复原技术旨在修复受损或退化的图像,如去除噪声、修复老照片等。随着深度学习的发展,图像复原技术也取得了长足的进步。
图像修复
图像修复(Image Inpainting)是一种填补图像缺失部分的技术。传统方法主要依赖纹理合成算法,而深度学习方法则能够通过学习图像的语义信息来实现更自然的修复效果。

一个典型的深度学习图像修复框架是基于U-Net自编码器的模型。该模型采用两步方法:粗略估计和细化。其中,关键的创新点是引入了一个称为"连贯语义注意力"(CSA)的层,通过迭代优化来填充被遮挡的区域。
图像分割
图像分割是将图像划分为多个语义区域的过程,是目标检测和图像理解的基础。深度学习模型在图像分割任务中表现出色,能够实现像素级的精确分割。
二值化分割
二值化是最简单的图像分割方法,将图像转换为黑白两色。通过选择合适的阈值,可以将图像中的目标与背景分离。

多级分割
多级分割是二值化的扩展,可以将图像分割为多个灰度级别。这种方法在医学图像处理中特别有用,如脑MRI分割。
深度学习分割
现代图像分割技术主要基于深度学习模型。例如,PFNet (Positioning and Focus Network)是一个专门用于伪装目标分割的CNN模型。它包含两个关键模块:
- 定位模块(PM):用于粗略定位目标位置
- 聚焦模块(FM):通过关注模糊区域来细化初步分割结果
PFNet模型在伪装目标分割任务中取得了优异的性能,超越了当时的最先进模型。
目标检测
目标检测是计算机视觉中的一个核心任务,目的是识别图像中的物体并定位它们的位置。深度学习,特别是卷积神经网络(CNN)的应用,极大地推动了目标检测技术的发展。

Faster R-CNN是一个广受欢迎的目标检测模型。它是一个端到端的全卷积网络,能够同时进行区域提议(预测可能包含目标的区域)和目标检测(识别区域中的目标)。Faster R-CNN的创新之处在于引入了区域提议网络(RPN),大大提高了检测速度和准确性。
图像压缩
图像压缩在数据存储和传输中扮演着重要角色。传统的压缩算法如JPEG主要基于离散余弦变换,而深度学习方法则开辟了新的可能性。
自编码器压缩
基于深度学习的图像压缩方法通常使用自编码器架构。自编码器由编码器和解码器两部分组成:
- 编码器:将输入图像压缩为低维特征表示
- 解码器:尝试从压缩特征中无损地恢复原始图像
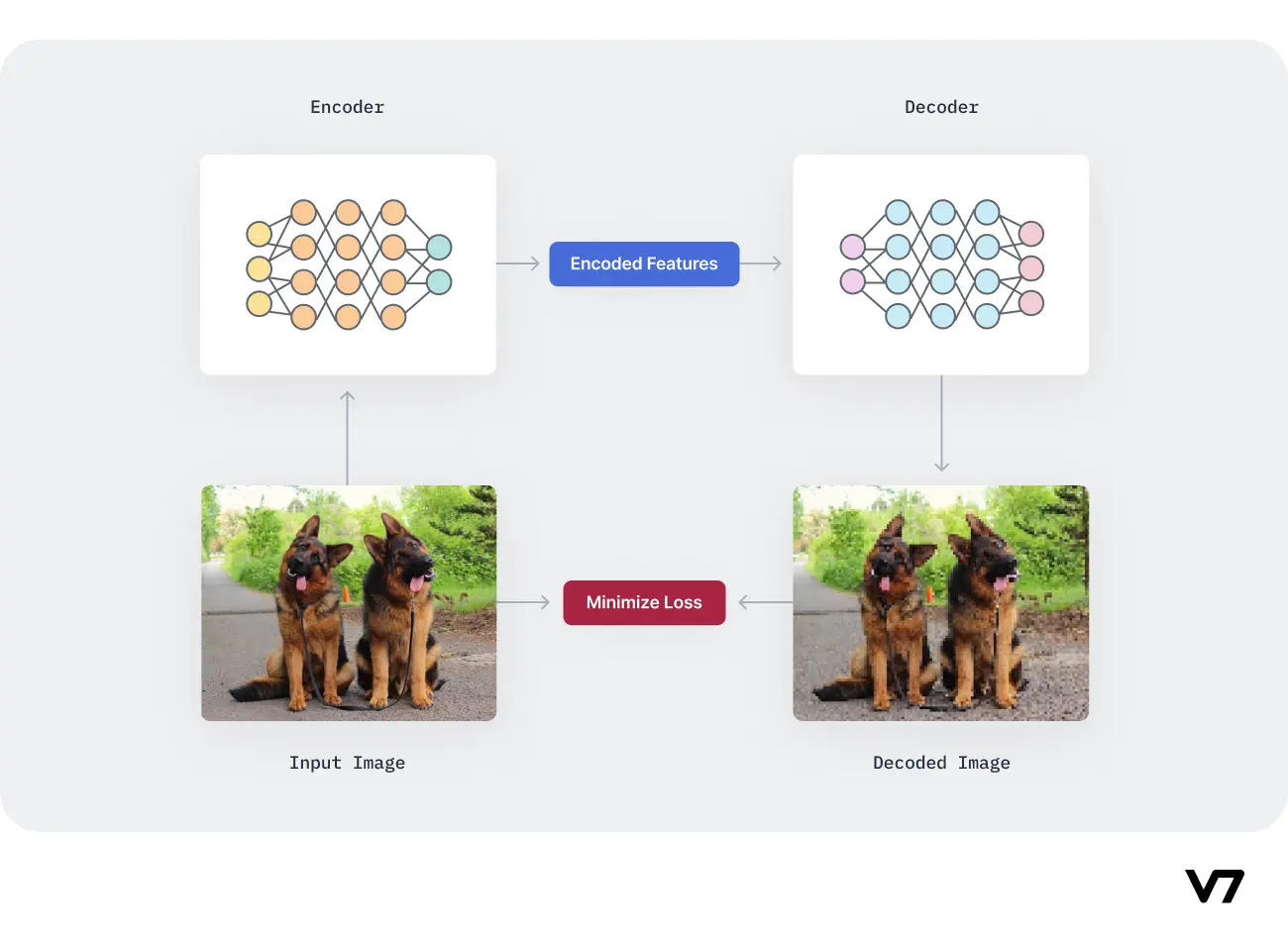
一些研究提出了可变比特率的图像压缩框架,通过条件自编码器实现。这种方法可以根据需求灵活调整压缩率,在压缩效率和图像质量之间取得更好的平衡。
图像生成与风格迁移
深度学习不仅能够分析和处理现有图像,还能够生成全新的图像或改变图像的风格。这为图像处理和计算机图形学带来了革命性的变化。
生成对抗网络(GAN)
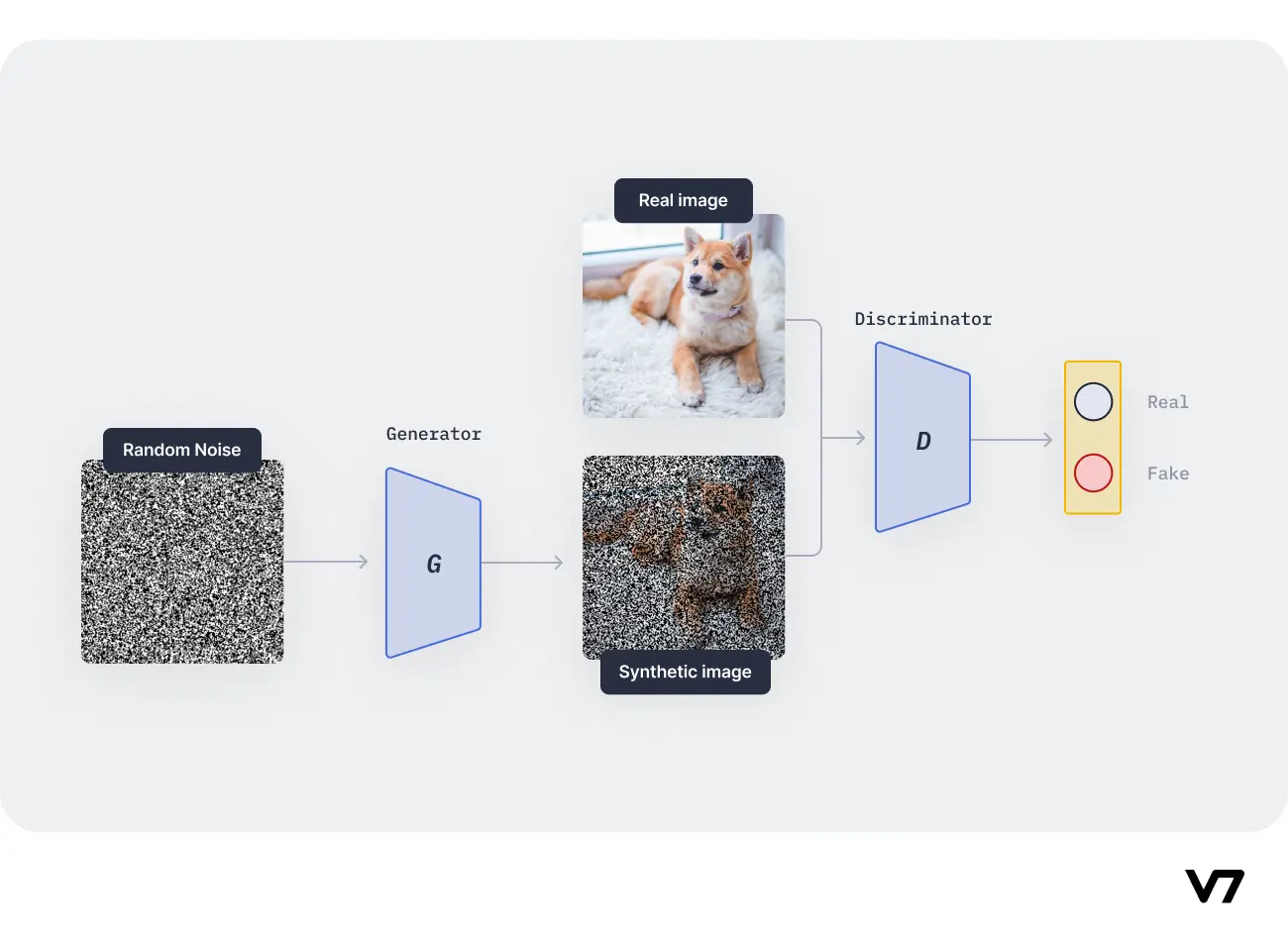
生成对抗网络(GAN)是一种强大的图像生成模型。GAN由生成器和判别器两个网络组成:
- 生成器:尝试生成逼真的合成图像
- 判别器:尝试区分真实图像和合成图像
通过这种对抗训练,GAN能够生成高度逼真的图像,在图像合成、数据增强等领域有广泛应用。
神经风格迁移
神经风格迁移是一种将一幅图像的风格应用到另一幅图像上的技术。例如,可以将梵高的"星夜"风格应用到一张普通照片上。

一些创新的方法,如自适应实例归一化(AdaIN),能够实现实时的任意风格迁移,大大提高了风格迁移的灵活性和效率。
图像到图像的转换
图像到图像的转换旨在学习输入图像和输出图像之间的映射关系。这包括诸如草图到真实图像、语义分割到真实图像等多种任务。
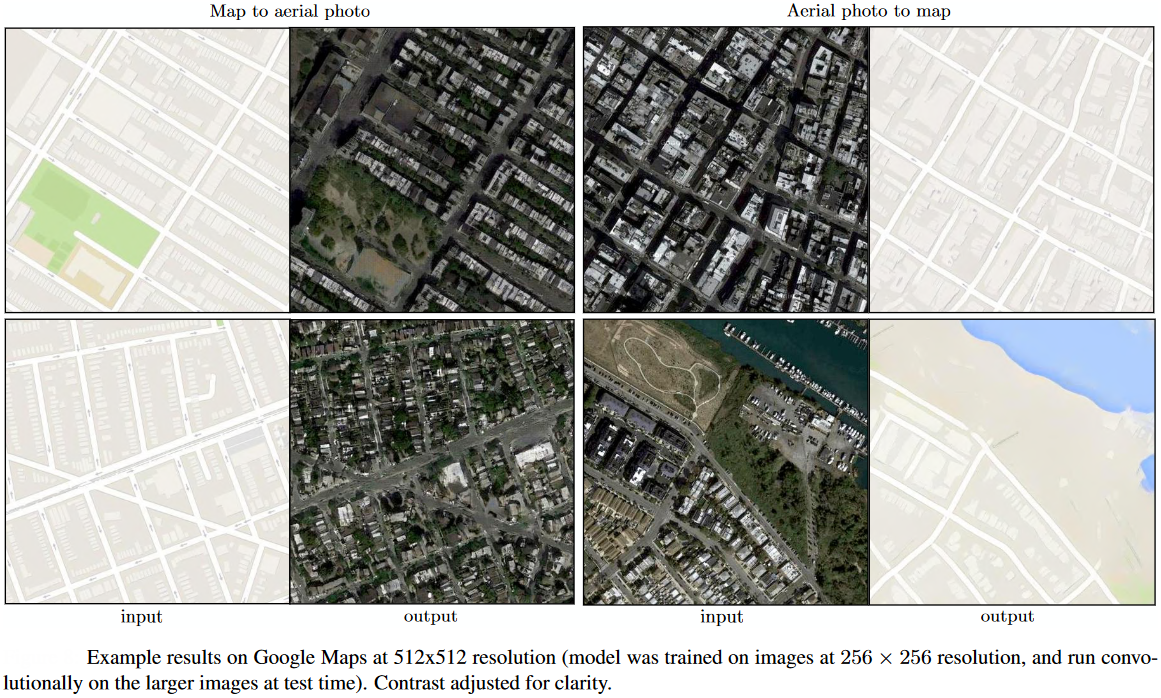
Pix2pix是这一领域的代表性模型,它使用条件生成对抗网络(cGAN)来实现通用的图像到图像转换。Pix2pix的创新之处在于使用PatchGAN判别器,这种判别器不是对整个图像进行判别,而是对图像的局部patch进行判别,从而能够更好地保持图像的高频细节。
结语
人工智能和机器学习技术在图像处理领域的应用正在不断深化和扩展。从基础的图像增强到复杂的图像生成,深度学习模型展现出了强大的能力和潜力。然而,这一领域仍然面临着诸多挑战,如如何减少对大量标注数据的依赖、如何提高模型的可解释性等。未来的研究方向可能会更多地聚焦于半监督学习、自监督学习等技术,以及如何将这些先进的图像处理技术更好地应用到实际场景中。
随着技术的不断进步,我们可以期待看到更多创新的图像处理应用,为计算机视觉、医学影像、娱乐产业等多个领域带来革命性的变革。🖼️🧠🚀


















