
aiXcoder-7B: 代码大语言模型的新里程碑
在人工智能和软件开发的交叉领域,代码大语言模型(Code Large Language Model)正在迅速崛起,成为提升开发效率和代码质量的重要工具。近日,aiXcoder团队推出的aiXcoder-7B模型在这一领域取得了突破性进展,为开发者带来了更加智能和高效的编程体验。
模型概述与创新特点
aiXcoder-7B是一个专门为代码理解和生成而设计的大规模语言模型,它在1.2T的独特代码token上进行了广泛训练。与其他同类模型相比,aiXcoder-7B在以下几个方面展现出独特的创新:
-
结构化预训练任务: aiXcoder-7B采用了创新的结构化Fill-In-the-Middle (FIM)预训练任务,这种方法结合了传统FIM和语法分析技术。在构建训练数据时,模型会将代码解析为抽象语法树(AST),并随机选择完整的节点来构建FIM任务。这种方法确保了输入数据的完整性,同时也使模型能够生成具有完整层次结构的代码。
-
多语言支持: aiXcoder-7B支持近百种主流编程语言,包括C++、Python、Java和JavaScript等。这种广泛的语言覆盖使其成为一个真正通用的代码辅助工具。
-
上下文理解能力: 通过创新的批处理方法,aiXcoder-7B展现出优秀的跨文件代码理解能力。这对于大型项目的开发尤为重要,因为开发者经常需要考虑其他文件中的信息。
-
高效的代码补全: 在代码补全任务中,aiXcoder-7B展现出卓越的性能,超越了同等参数规模的其他模型,甚至在某些方面超过了如codellama 34B和StarCoder2 15B等更大规模的模型。
数据处理的精益求精
aiXcoder-7B的成功很大程度上归功于其严谨的数据处理流程。团队采用了一系列复杂的步骤来确保训练数据的质量和多样性:
-
原始数据选择: 排除了copyleft许可证下的项目,并对来自各种代码托管平台和开源数据集的项目进行了去重。
-
项目级综合排名: 计算项目指标,包括Star数、Git提交次数和测试文件数量,并基于综合得分排除最低10%的数据。
-
代码文件级过滤: 移除自动生成的代码,并使用近似去重技术去除冗余。
-
敏感信息处理: 使用命名实体识别模型识别并删除敏感信息,如姓名、IP地址、账户密码和URL等。
-
注释代码清理: 随机删除大段注释代码。
-
语法分析: 删除前50种语言中存在语法解析错误或语法错误的代码。
-
静态分析: 使用静态分析工具扫描并定位161种影响代码可靠性和可维护性的Bug,以及197种影响代码安全性的漏洞。
这种严格的数据处理流程确保了aiXcoder-7B在训练过程中接触到的是高质量、多样化且安全的代码样本,从而为模型的优秀性能奠定了基础。
模型架构与训练细节
aioXcoder-7B的模型架构融合了多项先进技术:
- 分词器: 基于字节码的Byte Pair Encoding (BPE),词汇表大小为49,152。
- 位置编码: 采用RoPE (Rotary Positional Embedding)进行相对位置编码。
- 中间层: 使用SwiGLU作为中间层。
- 注意力机制: 实现了Grouped Query Attention。
在训练参数方面:
- 70%的训练任务是结构化FIM,30%是自回归训练任务。
- 预训练序列长度达到了32,768。
这些精心设计的架构和训练策略使aiXcoder-7B能够更好地理解和生成代码,特别是在处理长序列和复杂结构时表现出色。
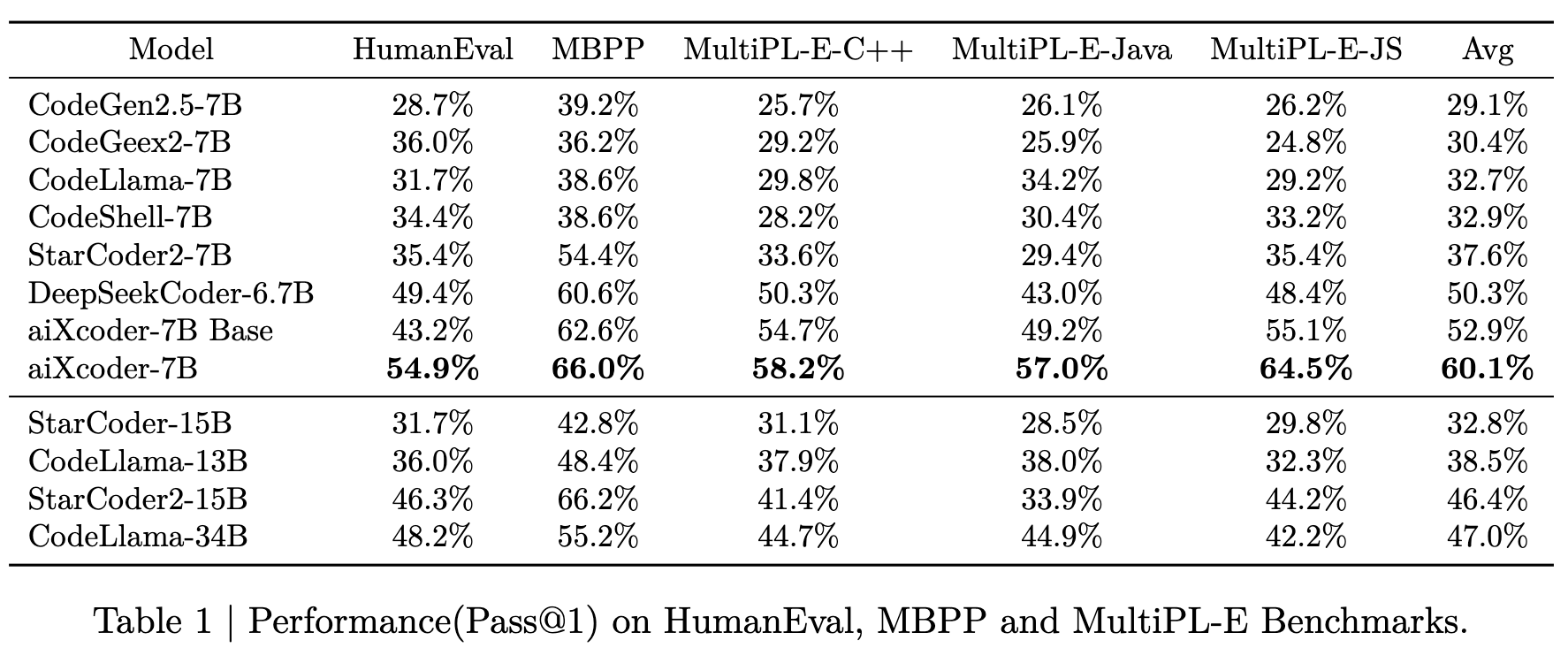
实验结果与性能评估
aiXcoder-7B在多项基准测试中展现出卓越的性能:
-
NL2Code基准测试: 在独立方法生成基准测试中,aiXcoder-7B Base模型在百亿参数规模的大型预训练基础模型中取得了当前最佳结果。
-
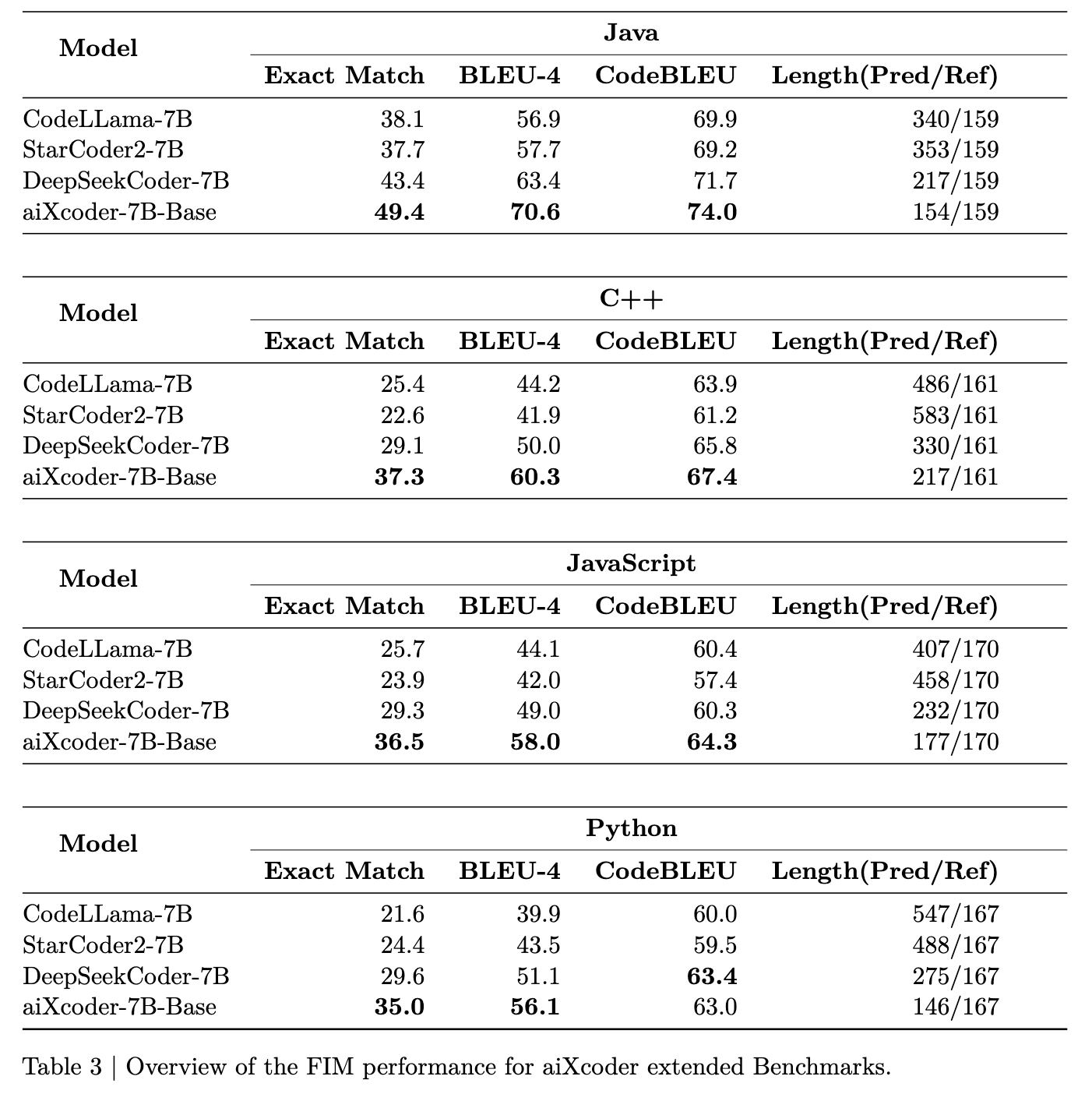
代码补全(Fill in the Middle): 在真实编程场景中的代码补全能力评估中,aiXcoder-7B Base模型在主要编程语言和各种评估标准上都取得了最佳表现。这表明aiXcoder-7B Base在同等规模的开源模型中具有最佳的基础代码补全能力,是提供实际编程场景代码补全能力的最合适基础模型。
-
跨文件代码评估: 使用CrossCodeEval数据集评估模型提取跨文件上下文信息的能力,aiXcoder-7B在所有语言中都表现出色,展示了模型提取上下文信息,特别是跨文件上下文信息的能力。
应用前景与未来展望
aioXcoder-7B的出现为软件开发领域带来了新的可能性:
-
提高开发效率: 通过精确的代码补全和生成功能,开发者可以更快速地编写代码,减少重复工作。
-
降低入门门槛: 对于新手开发者,aiXcoder-7B可以提供智能建议和代码示例,加速学习曲线。
-
跨语言开发支持: 多语言支持使得开发者在切换不同编程语言时能够获得一致的辅助体验。
-
大型项目协作: 优秀的跨文件代码理解能力有助于开发者在处理大型项目时更好地把握整体结构和上下文关系。
-
代码质量提升: 通过静态分析和最佳实践建议,aiXcoder-7B可以帮助开发者编写更安全、更可维护的代码。
展望未来,aiXcoder团队计划进一步发展aiXcoder模型系列。他们的目标是发布经过精心指令微调的新版本模型,以支持更广泛的编程任务,包括但不限于测试用例生成和代码调试。通过这些经过指令微调的模型,aiXcoder希望为开发者提供更全面、更深入的编程支持,帮助他们在软件开发的各个阶段最大化效率。
结语
aioXcoder-7B的发布标志着代码大语言模型进入了一个新的发展阶段。通过创新的预训练任务、严格的数据处理流程和先进的模型架构,aiXcoder-7B在代码理解和生成方面展现出了卓越的性能。这不仅为当前的软件开发带来了革命性的变革,也为未来人工智能辅助编程的发展指明了方向。随着技术的不断进步和模型的持续优化,我们可以期待aiXcoder-7B及其后续版本将在提升开发效率、改善代码质量和推动软件工程创新等方面发挥越来越重要的作用。









