
Anomaly Transformer:时间序列异常检测的突破性进展
在现代工业和互联网应用中,时间序列数据的异常检测一直是一个具有挑战性的问题。准确及时地识别异常点对于系统监控、故障预警和维护优化等方面都具有重要意义。近日,来自清华大学的研究团队提出了一种新颖的异常检测方法——Anomaly Transformer,在多个公开基准数据集上取得了突破性进展,为时间序列异常检测领域带来了新的解决思路。
Anomaly Transformer的核心创新
Anomaly Transformer的核心创新主要体现在以下三个方面:
-
提出了一种内在的可区分准则——关联差异(Association Discrepancy),用于异常检测。
-
设计了新的**异常注意力(Anomaly-Attention)**机制来计算关联差异。
-
采用极小极大策略来放大关联差异的正常-异常可区分性。
通过这些创新设计,Anomaly Transformer能够有效学习时间序列数据的信息表示,并推导出可靠的异常判别标准,从而实现高精度的异常检测。
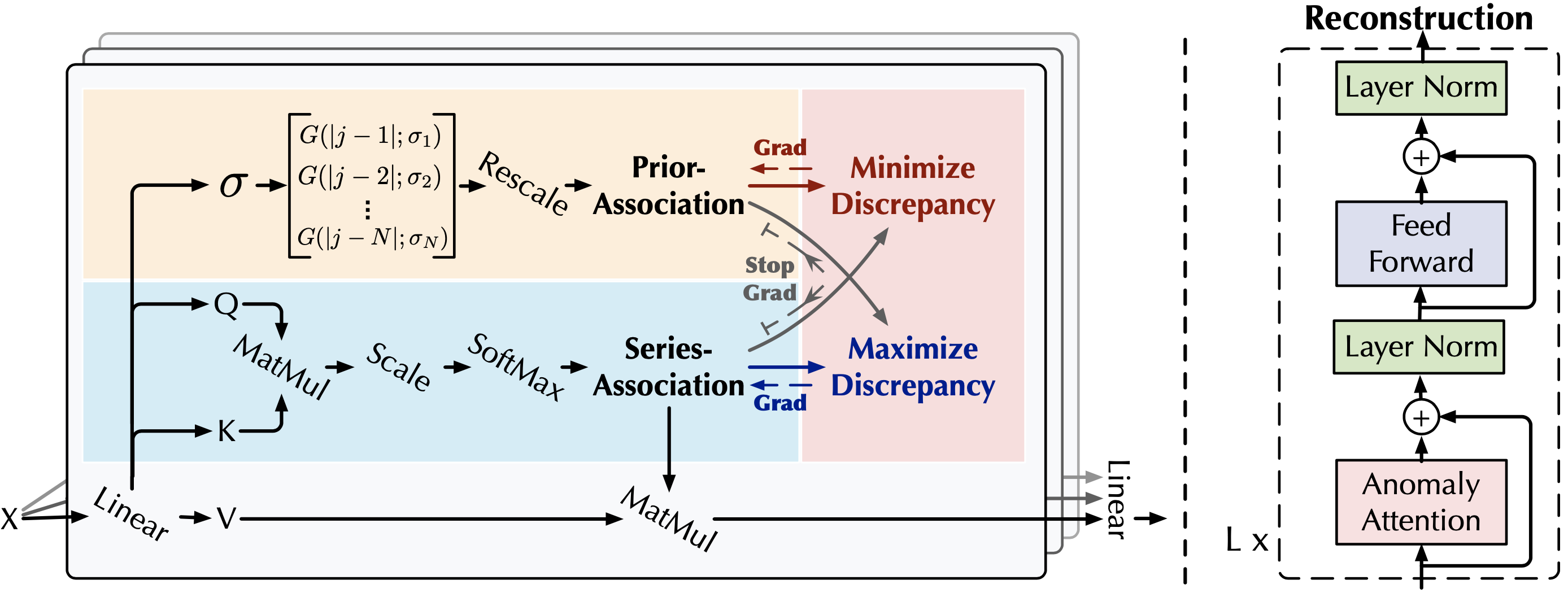
模型的工作原理
Anomaly Transformer的工作原理可以概括为以下几个步骤:
-
输入时间序列数据经过多层Transformer编码器进行特征提取和表示学习。
-
在自注意力机制的基础上,引入异常注意力机制,计算每个时间点与整个序列的关联差异。
-
通过极小极大策略训练模型,使正常样本的关联差异最小化,而异常样本的关联差异最大化。
-
在推理阶段,根据学习到的关联差异阈值判断每个时间点是否为异常。
这种基于关联差异的方法,相比传统的重构误差或预测误差方法,能够更好地捕捉时间序列数据的全局依赖关系,从而提高异常检测的准确性。
在基准数据集上的出色表现
研究团队在多个公开的时间序列异常检测基准数据集上对Anomaly Transformer进行了评估,包括SMD、MSL、SMAP和PSM等。实验结果表明,Anomaly Transformer在检测性能上全面超越了包括THOC、InterFusion在内的15种baseline方法,展现出了显著的优势。
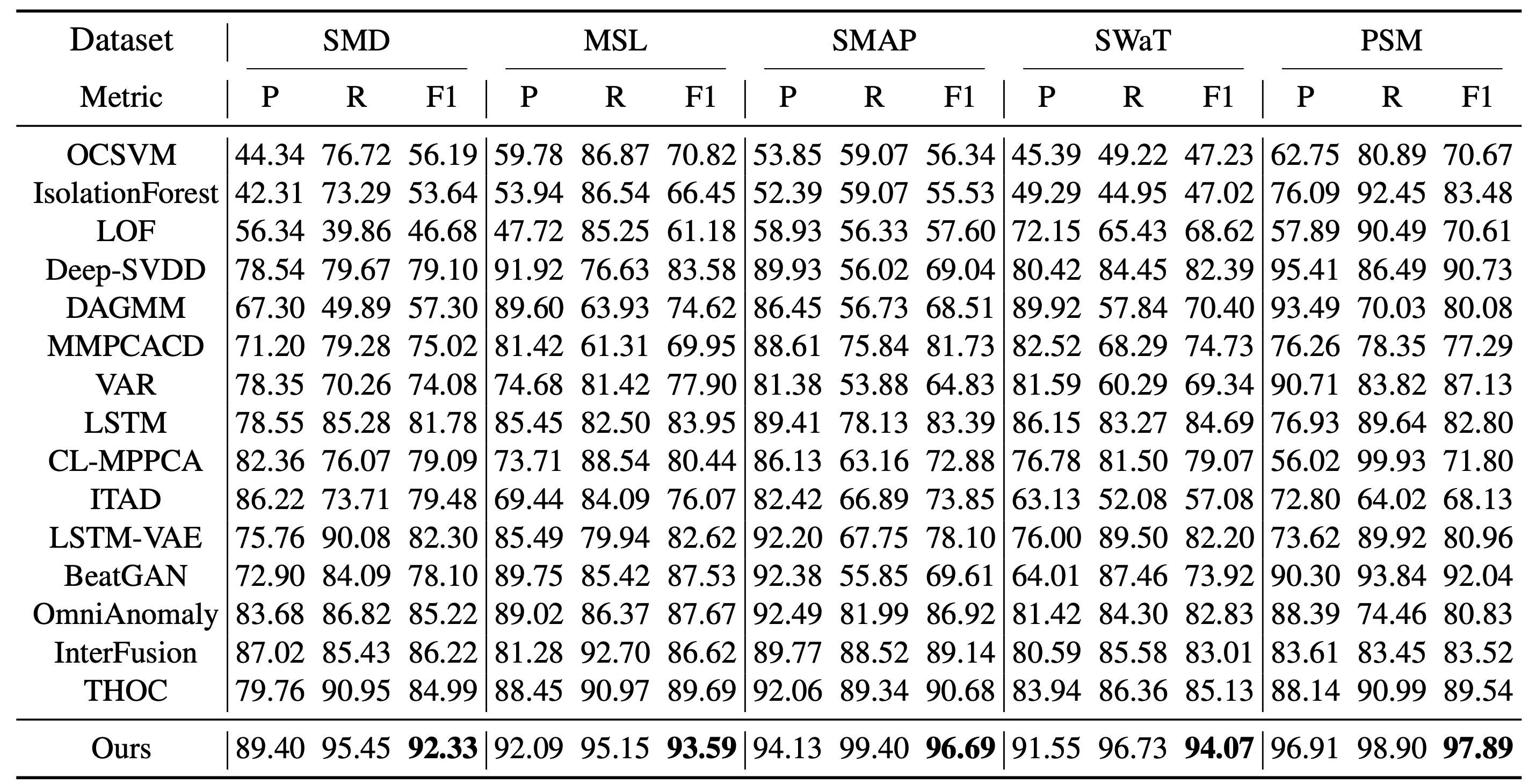
从上图可以看出,Anomaly Transformer在F1-score、Precision和Recall等关键指标上都取得了最佳成绩,体现了该方法在异常检测任务中的强大能力。
开源代码促进技术传播
为了促进该技术的传播和应用,研究团队已经在GitHub上开源了Anomaly Transformer的代码实现(https://github.com/thuml/Anomaly-Transformer)。感兴趣的研究者和工程师可以直接使用该代码进行实验复现或在实际应用中进行尝试。
使用Anomaly Transformer进行异常检测的主要步骤包括:
-
环境配置:安装Python 3.6和PyTorch 1.4.0或更高版本。
-
数据准备:从Google Cloud下载预处理好的benchmark数据集。
-
模型训练与评估:使用提供的脚本进行训练和评估,例如:
bash ./scripts/SMD.sh
bash ./scripts/MSL.sh
bash ./scripts/SMAP.sh
bash ./scripts/PSM.sh
值得注意的是,模型评估采用了Xu et al, 2018提出的调整操作,以确保评估结果的公平性和可比性。
未来研究方向
尽管Anomaly Transformer在时间序列异常检测任务上取得了显著成果,但仍有一些值得进一步探索的方向:
-
模型的可解释性:如何更好地解释模型的决策过程,提高异常检测结果的可信度。
-
实时处理能力:优化模型结构和推理速度,以满足实时异常检测的需求。
-
跨域泛化性:研究模型在不同领域和数据分布下的泛化能力,提高其实用价值。
-
与专家知识的结合:探索如何将领域专家知识融入模型,提高异常检测的准确性和可靠性。
结语
Anomaly Transformer的提出为时间序列异常检测领域带来了新的思路和方法。通过创新的关联差异和注意力机制,该方法在多个基准数据集上实现了领先的性能。随着开源代码的发布,我们期待看到更多研究者和工程师在此基础上进行改进和应用,推动时间序列异常检测技术的进一步发展。
如果您对Anomaly Transformer有任何疑问或建议,可以联系论文作者:wuhx23@mails.tsinghua.edu.cn。让我们共同期待这项技术在工业监控、金融风控、医疗诊断等领域带来的创新应用!









