
引言:LLMs与多模态生成的碰撞
随着人工智能技术的飞速发展,大型语言模型(Large Language Models, LLMs)在自然语言处理领域取得了突破性进展。从GPT系列到BERT,再到最新的ChatGPT,LLMs展现出了惊人的语言理解和生成能力。然而,人类的交互和认知并不局限于纯文本,而是涉及多种感官模态。因此,将LLMs的强大能力扩展到多模态生成领域成为了一个极具吸引力的研究方向。
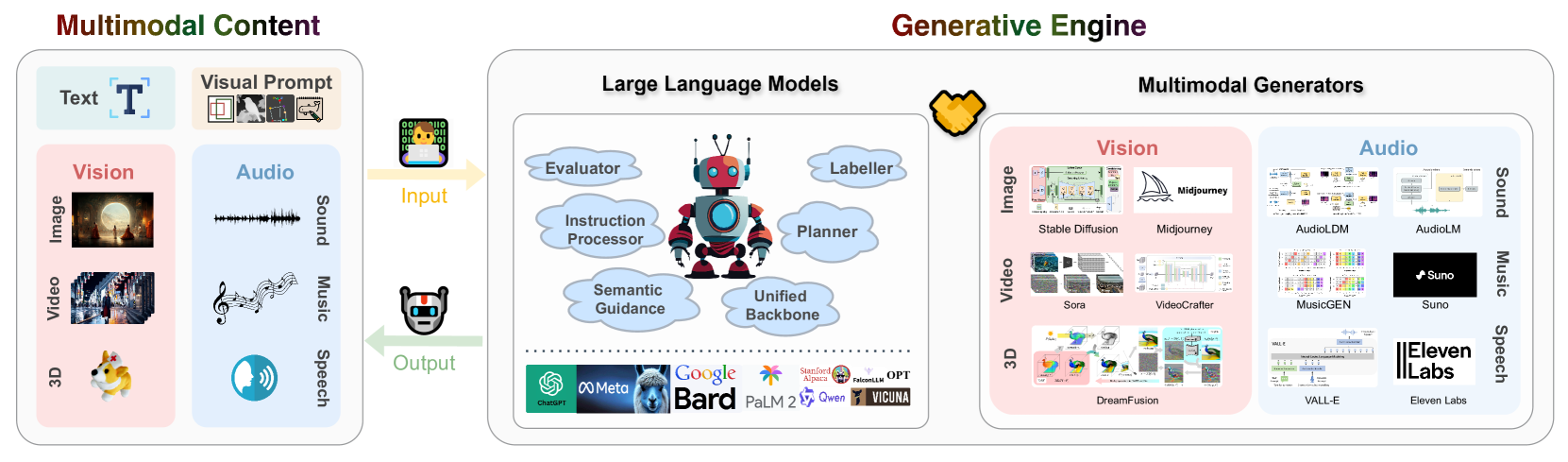
Awesome-LLMs-meet-Multimodal-Generation项目正是在这样的背景下应运而生。该项目旨在汇集和整理LLMs在多模态生成领域的最新研究成果,为研究人员和开发者提供一个全面的资源库。本文将深入探讨这个项目的内容、意义以及未来展望。
Awesome-LLMs-meet-Multimodal-Generation项目概述
Awesome-LLMs-meet-Multimodal-Generation是一个GitHub上的开源项目,由来自香港科技大学的研究团队发起和维护。该项目的核心目标是提供一个精心策划的论文列表,涵盖了基于LLMs的多模态生成研究,包括图像、视频、3D和音频等领域。
项目特点
-
全面性:项目涵盖了多个模态,不仅包括常见的图像和视频生成,还包括3D和音频生成,为研究人员提供了广泛的参考资料。
-
及时性:维护团队定期更新项目内容,确保收录的论文和研究成果始终保持最新。
-
分类清晰:项目将论文按照不同的模态和研究方向进行分类,便于用户快速找到感兴趣的内容。
-
开源协作:作为一个GitHub项目,Awesome-LLMs-meet-Multimodal-Generation鼓励社区贡献,促进了知识的共享和交流。
LLMs在多模态生成中的应用
图像生成与编辑
在图像生成领域,LLMs的引入为文本到图像(Text-to-Image, T2I)生成任务带来了新的可能性。研究人员探索了将LLMs作为条件输入、提示生成器或质量评估器的多种方法。例如,一些工作尝试使用LLMs来优化文本提示,从而生成更高质量、更符合用户意图的图像。
在图像编辑方面,LLMs被用于理解复杂的编辑指令,并将其转化为具体的图像操作。这使得用户可以通过自然语言来描述他们希望对图像进行的修改,大大提高了图像编辑的灵活性和易用性。
视频生成与编辑
视频生成是一个更具挑战性的任务,因为它需要在时间维度上保持一致性。LLMs在这一领域的应用主要集中在以下几个方面:
-
剧本生成:LLMs可以根据用户的简短描述生成详细的视频剧本,为后续的视频生成提供指导。
-
时序规划:利用LLMs的序列建模能力,研究人员探索了如何更好地规划视频中的时间变化和动作序列。
-
多模态融合:LLMs被用于协调视频中的视觉、音频和文本信息,确保生成的视频在多个模态上保持一致。
3D生成
3D生成是一个相对新兴的研究方向,LLMs在这一领域的应用正在快速发展。研究人员探索了将LLMs与3D表示(如网格、点云、神经辐射场(NeRF)等)结合的方法,以实现更精确和语义丰富的3D内容生成。
一个典型的应用是文本到3D生成,其中LLMs被用于理解复杂的3D场景描述,并指导3D模型的生成过程。这种方法有潜力彻底改变3D设计和虚拟现实内容创作的流程。
音频生成
在音频生成领域,LLMs的应用涵盖了语音合成、音乐生成和声音效果创作等多个方面。研究人员探索了如何利用LLMs的语言理解能力来生成更加自然、富有表现力的语音,或者创作符合特定风格和情感的音乐。
一个有趣的研究方向是多模态音频生成,即根据文本和图像等多模态输入生成相应的音频。这种技术在电影配音、游戏音效制作等领域有广阔的应用前景。
LLMs在多模态生成中的角色
通过对Awesome-LLMs-meet-Multimodal-Generation项目收录的研究进行分析,我们可以总结出LLMs在多模态生成中扮演的几个关键角色:
-
内容规划器:LLMs可以根据用户的高级描述生成详细的内容计划,为后续的多模态生成提供结构化的指导。
-
语义解释器:利用LLMs强大的语言理解能力,将用户的自然语言指令转化为多模态生成模型可以理解和执行的形式。
-
跨模态桥梁:LLMs可以作为不同模态之间的桥梁,协调和统一多个模态的信息,确保生成内容的一致性。
-
质量评估器:利用LLMs的推理能力,对生成的多模态内容进行评估和反馈,指导生成过程的优化。
-
交互式助手:LLMs可以与用户进行自然语言对话,帮助用户更好地表达创作意图,并提供创作建议。
技术挑战与未来展望
尽管LLMs在多模态生成领域展现出了巨大的潜力,但仍然存在一些技术挑战需要克服:
-
模态对齐:如何更好地对齐LLMs的语言表示与其他模态(如视觉、音频)的表示,是提高多模态生成质量的关键。
-
计算效率:大型LLMs的计算开销较大,如何在保证生成质量的同时提高效率,是实际应用中需要解决的问题。
-
可控性:增强对生成过程的精细控制,使用户能够更准确地表达和实现其创作意图。
-
伦理和安全性:随着多模态生成技术的发展,如何防止生成有害或具有误导性的内容成为一个重要议题。
展望未来,LLMs与多模态生成的结合将继续推动人工智能创作的边界。我们可以期待以下几个方向的发展:
-
更加智能的创作助手:融合LLMs和多模态生成的系统将能够理解更复杂的创作意图,提供更加个性化和专业的创作建议。
-
实时交互式生成:随着技术的进步,用户将能够通过自然语言实时指导和调整多模态内容的生成过程。
-
跨模态内容理解与生成:系统将能够更好地理解和生成跨越多个模态的复杂内容,如根据文本和音乐生成配套的视频。
-
个性化和定制化生成:LLMs将能够学习和适应个人或特定领域的风格和偏好,生成更加符合特定需求的内容。
结语
Awesome-LLMs-meet-Multimodal-Generation项目为我们展示了LLMs在多模态生成领域的巨大潜力和快速发展。通过整合语言模型的强大能力与多模态生成技术,我们正在向着更加智能、自然和创新的人工智能创作工具迈进。这一领域的进展不仅将改变内容创作的方式,还将为虚拟现实、增强现实、智能助理等多个领域带来革命性的变革。
作为一个开放的社区项目,Awesome-LLMs-meet-Multimodal-Generation欢迎研究者和开发者的贡献。无论你是该领域的专家还是刚刚入门的学习者,都可以通过关注、分享或直接参与项目来推动这一激动人心的研究方向的发展。让我们共同期待LLMs与多模态生成技术碰撞出更多精彩的火花,为人工智能的未来描绘更加绚丽的蓝图。











