
BIG-bench: 探索人工智能语言能力的新边界
在人工智能快速发展的今天,大规模语言模型的能力不断突破人们的想象。为了更好地理解和评估这些模型的潜力,Google牵头发起了一项名为"超越模仿游戏基准"(Beyond the Imitation Game Benchmark,简称BIG-bench)的协作性研究项目。这个项目汇聚了全球450多位研究者的智慧,共同设计了200多个具有挑战性的任务,旨在全方位地测试语言模型的能力极限。
BIG-bench的起源与目标
BIG-bench项目的名称源自著名计算机科学家图灵提出的"模仿游戏",也就是后来被称为"图灵测试"的人工智能能力评估方法。但BIG-bench的目标不仅仅是测试AI是否能模仿人类,而是要探索AI在各种复杂任务中的表现,并推测其未来可能达到的能力水平。
这个基准测试的主要特点包括:
- 协作性:来自132个机构的450多位研究者共同贡献了任务设计。
- 多样性:包含204个涵盖不同领域的任务。
- 挑战性:许多任务都具有较高难度,能够测试模型的极限。
- 开放性:项目代码和数据集在GitHub上开源,鼓励更多研究者参与。
BIG-bench的任务设计
BIG-bench中的任务覆盖了广泛的领域,包括但不限于:
- 语言学:语法、语义、语用等各个层面
- 常识推理:需要运用日常生活知识解决问题
- 数学:从基础算术到高等数学
- 编程:代码理解与生成
- 伦理:探讨AI系统的伦理判断能力
- 多语言:包含1000多种语言的任务
这些任务被精心设计,以测试语言模型在不同方面的能力,如:
- 上下文理解
- 逻辑推理
- 知识应用
- 创造性思维
- 多步骤问题解决
例如,其中一个名为"emoji_movie"的任务要求模型根据一系列emoji表情猜测电影名称,这不仅考验模型的常识,还需要一定的创造性思维。
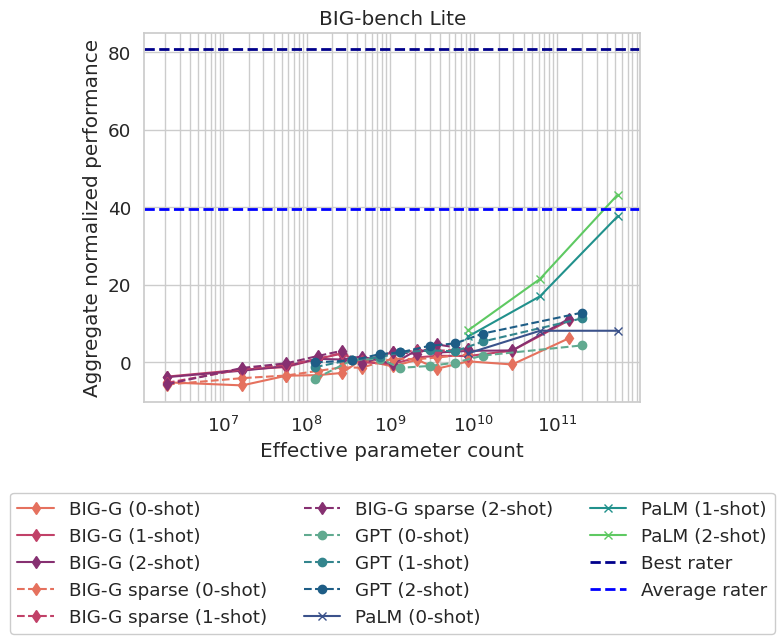
BIG-bench Lite: 轻量级评估工具
考虑到完整的BIG-bench测试耗时较长,研究者还开发了一个名为"BIG-bench Lite"(BBL)的子集。BBL包含24个精选任务,可以在较短时间内对模型进行初步评估。上图展示了一些知名语言模型在BBL上的表现排行。
参与BIG-bench项目
BIG-bench是一个开放的项目,欢迎更多研究者参与其中。主要参与方式包括:
- 贡献新任务:研究者可以设计新的挑战性任务并提交。
- 评估模型:使用BIG-bench对自己开发的语言模型进行测试,并分享结果。
- 改进基准:对现有任务提出改进建议或修复问题。
参与流程大致如下:
- 在GitHub上fork BIG-bench仓库
- 创建新分支,开发任务或改进
- 提交pull request,等待审核
- 通过审核后,贡献将被合并到主仓库
BIG-bench的影响与未来
作为一个全面而开放的语言模型评估基准,BIG-bench正在产生广泛的影响:
- 为研究者提供了统一的评估标准,便于比较不同模型的性能。
- 揭示了当前语言模型的优势和局限性,指明了未来研究方向。
- 促进了AI社区的合作,汇聚了全球研究者的智慧。
- 推动了语言模型在各个领域的应用探索。
未来,BIG-bench项目还将继续发展,可能的方向包括:
- 增加更多challenging的任务
- 开发针对特定应用场景的子集
- 探索如何评估模型的安全性和伦理性
- 结合其他评估方法,如人机交互评估
结语
BIG-bench项目为我们提供了一个窗口,让我们得以窥见大规模语言模型的能力边界。它不仅是一个技术基准,更是AI研究社区协作的典范。随着项目的不断发展和完善,相信它将继续推动语言AI技术向着更高水平迈进。
无论你是AI研究者、开发者还是对这一领域感兴趣的学习者,都可以从BIG-bench项目中获得启发。让我们共同期待AI语言能力的下一个突破!

(图片:Alan Turing纪念雕像,位于英国曼彻斯特Sackville公园)









