
BigVGAN: 革命性的通用神经声码器
在语音合成和音频生成领域,一直存在着一个巨大的挑战 - 如何创建一个能够适应各种不同场景的通用声码器。传统的声码器往往在特定数据集上表现出色,但在面对未见过的场景时却表现不佳。然而,NVIDIA研究团队最近发布的BigVGAN项目为这一难题提供了一个突破性的解决方案。
BigVGAN简介
BigVGAN是一种基于生成对抗网络(GAN)的通用神经声码器,由NVIDIA研究团队开发。它的最大特点是具有卓越的跨分布泛化能力,能够在多种未见过的场景中生成高质量的音频。
BigVGAN的核心创新在于以下几个方面:
-
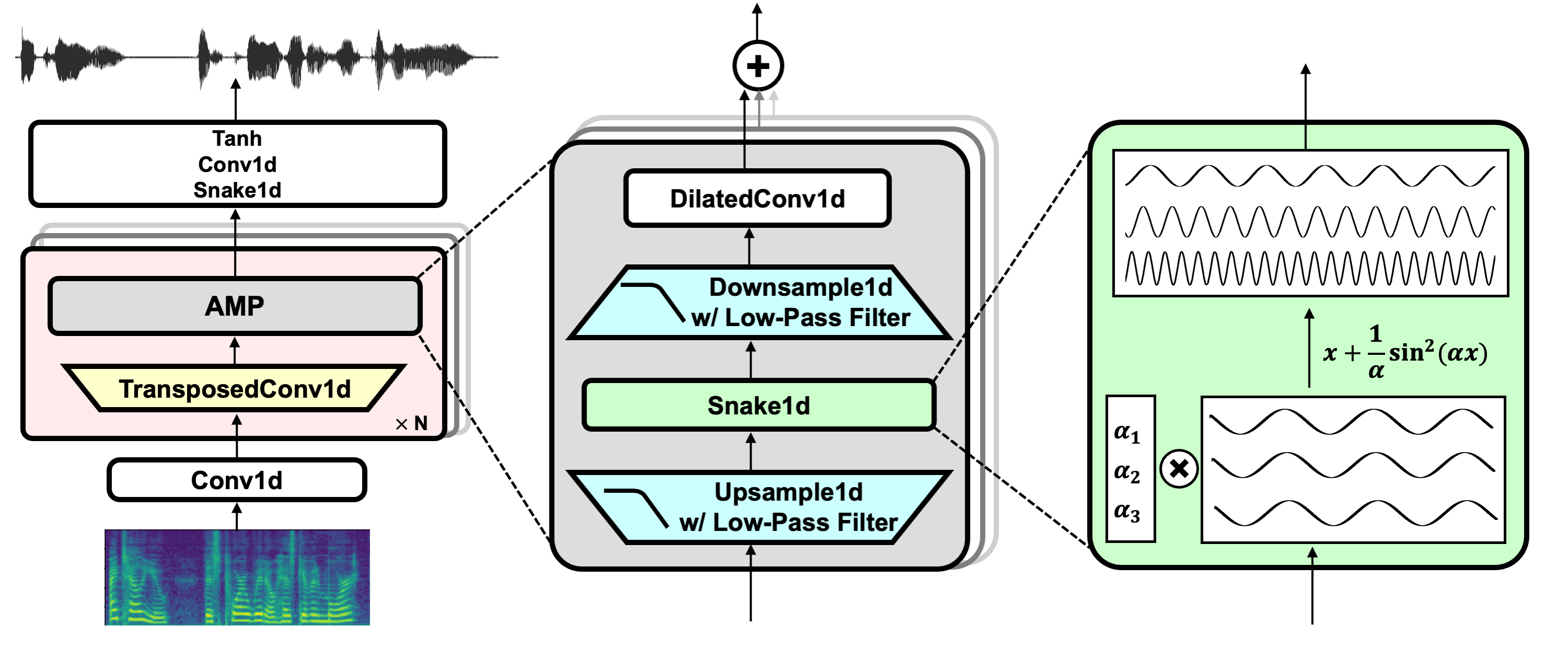
引入了周期性激活函数和抗混叠表示,为音频合成带来了所需的归纳偏置,显著提高了音频质量。
-
将GAN声码器的规模扩大到前所未有的1.12亿参数,并解决了大规模GAN训练中的不稳定性问题。
-
仅使用清晰语音(LibriTTS数据集)进行训练,却能在各种零样本(跨分布)场景下实现最先进的性能。
卓越的跨分布泛化能力
BigVGAN最令人印象深刻的特点是其卓越的跨分布泛化能力。尽管仅在LibriTTS清晰语音数据集上进行训练,BigVGAN却能够在以下多种未见过的场景中表现出色:
- 未见过的说话人
- 不同的语言
- 各种录音环境
- 歌声合成
- 音乐生成
- 乐器音频合成
这种强大的泛化能力使BigVGAN成为一个真正的通用声码器,能够适应各种音频生成任务。
技术创新
BigVGAN的成功依赖于几项关键的技术创新:
-
周期性激活函数: 引入Snake激活函数,为音频波形合成提供周期性的归纳偏置。
-
抗混叠表示: 采用低通滤波器和重采样技术,有效减少了高频伪影。
-
大规模训练: 将模型规模扩大到1.12亿参数,同时解决了大规模GAN训练中的不稳定性问题。
-
多尺度判别器: 采用多周期判别器和多分辨率判别器,提高了生成音频的质量和细节。
性能评估
BigVGAN在多项客观指标上都展现出了卓越的性能:
| 模型 | 数据集 | 步骤 | PESQ(↑) | M-STFT(↓) | MCD(↓) | 周期性(↓) | V/UV F1(↑) |
|---|---|---|---|---|---|---|---|
| BigVGAN | LibriTTS | 1M | 4.027 | 0.7997 | 0.3745 | 0.1018 | 0.9598 |
| BigVGAN | LibriTTS | 5M | 4.256 | 0.7409 | 0.2988 | 0.0809 | 0.9698 |
| BigVGAN-v2 | 大规模混合 | 3M | 4.359 | 0.7134 | 0.3060 | 0.0621 | 0.9777 |
这些数据清楚地表明,BigVGAN不仅在传统的语音合成任务上表现出色,还在各种跨分布场景中展现了强大的泛化能力。
实际应用
BigVGAN的通用性使其在多个领域都有潜在的应用:
-
文本转语音(TTS)系统: 作为后端声码器,提高TTS系统的音质和自然度。
-
语音转换: 在保持音色特征的同时,提高转换后语音的质量。
-
音乐生成: 用于创作AI音乐或辅助音乐创作。
-
音频修复: 修复和增强低质量或受损的音频。
-
虚拟助手和聊天机器人: 提供更自然、更富表现力的语音输出。
未来展望
尽管BigVGAN已经取得了令人瞩目的成就,但研究团队仍在不断推动其发展:
-
进一步提高音质: 探索新的网络结构和训练技巧,以生成更高质量的音频。
-
降低计算复杂度: 优化模型,使其能在更多设备上实时运行。
-
多模态集成: 将BigVGAN与其他模态(如视觉)结合,创建更全面的生成系统。
-
个性化定制: 开发方法使BigVGAN能够更容易地适应特定领域或风格。
结论
BigVGAN代表了神经声码器领域的一个重大突破。它不仅在传统的语音合成任务上表现出色,更重要的是,它展示了跨越多个音频领域的强大泛化能力。这种通用性使BigVGAN成为未来音频生成技术的重要基石,有望在语音合成、音乐创作、音频处理等多个领域产生深远影响。
随着BigVGAN的不断发展和完善,我们可以期待看到更多令人兴奋的应用和创新。无论是提高虚拟助手的自然度,还是为音乐创作者提供新的工具,BigVGAN都有潜力彻底改变我们与音频技术互动的方式。
BigVGAN的出现无疑为音频生成领域注入了新的活力。它不仅展示了当前深度学习技术的强大能力,也为未来的研究指明了方向。我们有理由相信,在不久的将来,基于BigVGAN的技术将为我们带来更多令人惊叹的音频体验。











