
BK-SDM:轻量高效的下一代文本生成图像模型
近年来,基于扩散模型的文本生成图像技术取得了巨大进展,其中Stable Diffusion(SD)模型以其出色的生成效果和开放性受到广泛关注。然而,SD模型动辄数十亿的参数量也带来了巨大的计算成本,限制了其在资源受限场景下的应用。为了解决这一问题,来自Nota公司的研究团队提出了Block-removed Knowledge-distilled Stable Diffusion Model(BK-SDM),这是一种经过架构压缩和知识蒸馏的轻量级SD模型,在大幅减少参数量的同时,仍保持了接近原始模型的生成效果。
创新的模型压缩方法
BK-SDM的核心创新在于其独特的模型压缩方法。研究团队采用了两个主要策略来压缩SD模型:
-
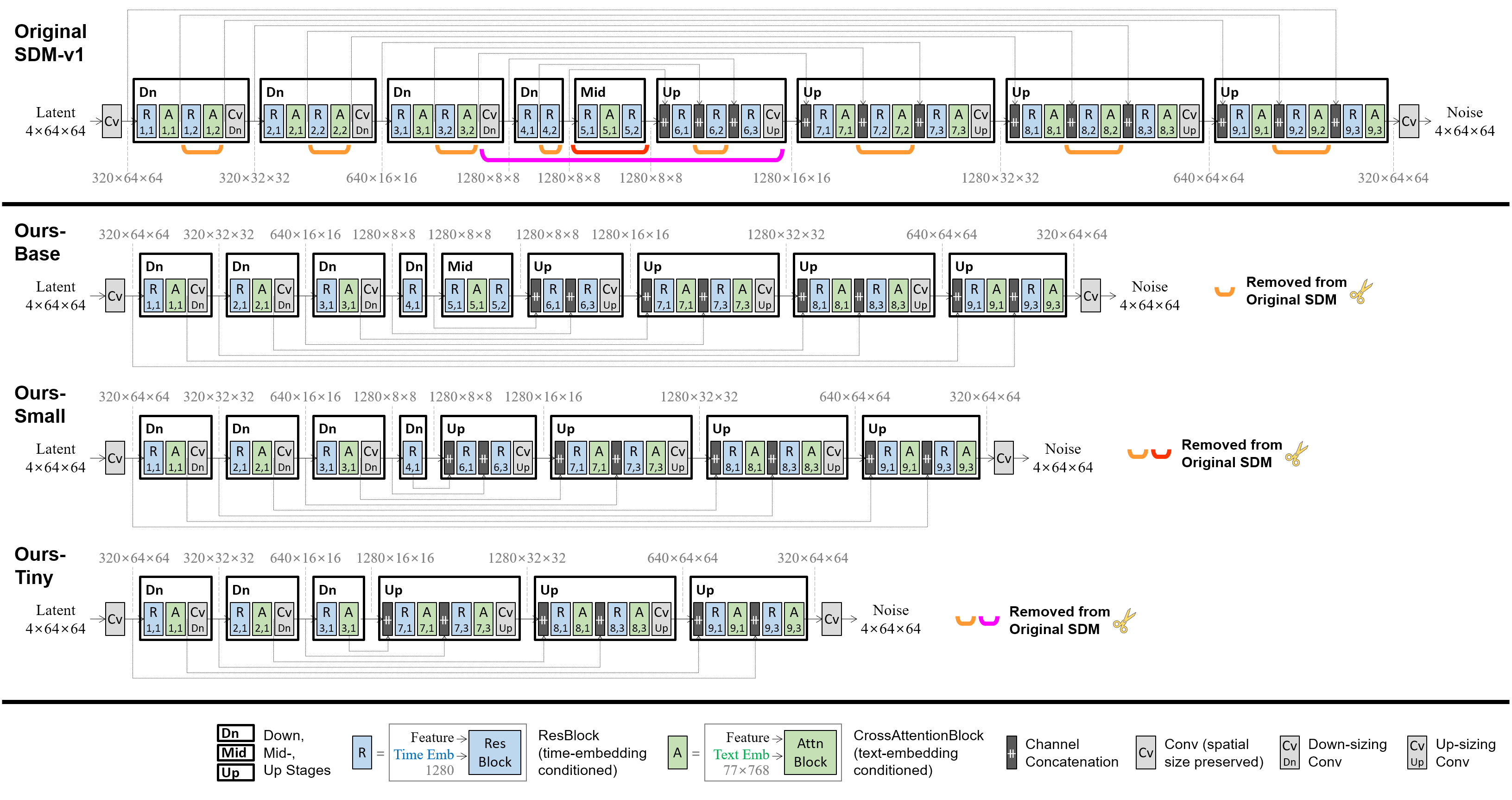
块移除(Block Removal):从SD模型的U-Net架构中移除特定的残差块和注意力块,显著减少了模型参数量。
-
知识蒸馏(Knowledge Distillation):通过蒸馏预训练,将原始SD模型的知识转移到压缩后的小模型中。
这种方法允许研究人员在保持生成质量的同时,大幅降低模型的计算复杂度。例如,BK-SDM-Tiny版本相比原始SD-v1.4模型,参数量减少了52%,每次采样步骤的MAC(乘加运算)数减少了51%,推理延迟减少了43%.
出色的生成效果
尽管模型规模大幅缩小,BK-SDM在生成效果上仍表现出色。在MS-COCO数据集上的零样本评估中,BK-SDM系列模型与原始SD模型以及其他大规模多十亿参数模型相比,仍能达到具有竞争力的FID、IS和CLIP得分。这证明了BK-SDM成功保留了原始模型的大部分生成能力。
以下是一些由BK-SDM生成的示例图像,展示了其在不同场景下的生成效果:

高效的训练方法
BK-SDM的另一大亮点在于其高效的训练方法。研究团队仅使用了LAION数据集中的22万图文对(约占完整训练集的0.1%)进行蒸馏预训练,整个训练过程仅需一张A100 GPU运行13天左右。这种高效的训练方式大大降低了模型开发和迭代的成本,为未来更多研究者和开发者参与SD模型的改进提供了可能。
广泛的应用潜力
BK-SDM不仅在通用文本生成图像任务上表现出色,还展示了在个性化生成等场景下的应用潜力。研究团队通过DreamBooth技术对BK-SDM进行微调,成功实现了对特定主题的个性化生成。这表明BK-SDM作为一个轻量级backbone,可以灵活地应用于各种下游任务。

此外,BK-SDM还被成功部署到移动设备上。研究团队将模型转换为Core ML格式,在iPhone 14上实现了4秒内完成一次推理的性能,为SD技术在边缘设备上的应用开辟了新的可能。
开源与社区影响
BK-SDM项目采用开源方式发布,获得了广泛关注。截至目前,项目在GitHub上已获得238颗星标,16次分叉。研究团队不仅开源了模型权重和训练代码,还提供了详细的文档和使用示例,大大降低了其他研究者和开发者使用和改进BK-SDM的门槛。
项目还得到了AI社区的认可。华为的Segmind团队基于BK-SDM的思想提出了自己的实现版本,进一步验证了这一技术路线的可行性。同时,BK-SDM的在线演示也被Hugging Face评选为"每周精选空间",反映出社区对这一轻量高效SD模型的浓厚兴趣。
未来展望
BK-SDM的成功为高效文本生成图像技术的发展指明了方向。未来,我们可以期待在以下几个方面看到更多进展:
-
进一步的模型压缩:探索更先进的压缩技术,如量化、剪枝等,进一步减小模型体积。
-
特定领域优化:针对特定应用场景(如医疗影像、工业设计等)优化BK-SDM,提高其在垂直领域的性能。
-
多模态融合:将BK-SDM与其他模态(如语音、视频)结合,拓展其应用范围。
-
边缘AI落地:进一步优化BK-SDM在移动设备和边缘计算平台上的性能,推动生成式AI技术的普及。
-
伦理和安全:研究如何在保证模型轻量高效的同时,增强其对有害内容的过滤能力,确保技术的负责任使用。
总的来说,BK-SDM为解决大规模生成模型的计算资源瓶颈提供了一种富有前景的方案。随着技术的不断完善和应用场景的拓展,我们有理由相信,这种轻量高效的文本生成图像模型将在未来的AI生态系统中发挥越来越重要的作用。


















