
BookNLP:为长文本分析而生的NLP工具
在自然语言处理(NLP)领域,处理长文本一直是一个挑战。大多数现有的NLP模型和工具主要针对短文本设计,在分析书籍等长篇文档时往往力不从心。为了解决这一问题,研究人员开发了BookNLP - 一个专门用于处理书籍和长文档的NLP工具包。
BookNLP的主要功能
BookNLP提供了丰富的文本分析功能,包括:
- 词性标注和依存句法分析
- 命名实体识别
- 人物名称聚类和指代消解
- 引语说话人识别
- 超义标注
- 事件标注
- 指代性别推断
这些功能使BookNLP能够深入分析长文本的语言结构和语义内容,为文学研究和数字人文等领域提供了强大支持。
针对长文本的优化
与传统NLP工具相比,BookNLP在以下几个方面做了针对性优化:
-
扩展性:能够处理书籍长度的文档,而不受内存限制。
-
人物分析:通过人物名称聚类和指代消解,可以准确追踪整本书中的人物。
-
上下文理解:利用长距离上下文信息进行更准确的语义分析。
-
文学特征:针对文学作品的特点(如对话、隐喻等)进行了优化。
BookNLP的工作流程
使用BookNLP分析一本书的典型工作流程如下:
- 输入原始文本文件
- BookNLP处理文本,生成多个输出文件
- 输出文件包含tokens、实体、引语、超义等信息
- 研究人员可以进一步分析这些结构化数据
以《巴特比》为例,BookNLP会生成如下输出文件:
- bartleby.tokens:包含词级别的核心信息
- bartleby.entities:包含文档中的实体及其指代关系
- bartleby.supersense:包含超义标注信息
- bartleby.quotes:包含引语及说话人信息
- bartleby.book:包含书中人物的详细信息JSON
- bartleby.book.html:包含全文及注释的HTML文件
BookNLP的应用
BookNLP为文学研究和数字人文领域带来了新的分析可能:
-
人物网络分析:通过人物共现、对话等信息构建小说人物关系网络。
-
叙事结构研究:分析事件序列、场景转换等揭示叙事模式。
-
文体分析:对比不同作者、流派的语言特征。
-
主题演变:追踪长篇作品中主题的变化和发展。
-
性别研究:分析作品中的性别刻画和代表。
BookNLP的局限性
尽管功能强大,BookNLP也存在一些局限:
- 目前仅支持英语文本
- 对非标准英语(如方言)的支持有限
- 某些任务(如指代消解)的准确率仍有提升空间
- 处理速度较慢,尤其是对大型文集
研究人员正在不断改进BookNLP,未来有望支持更多语言和提高性能。
使用BookNLP
BookNLP可通过pip安装:
pip install booknlp
使用时,需先定义模型参数:
model_params = {
"pipeline":"entity,quote,supersense,event,coref",
"model":"big"
}
booknlp = BookNLP("en", model_params)
然后就可以处理输入文本:
booknlp.process(input_file, output_directory, book_id)
总结
BookNLP为长文本NLP带来了新的可能,它不仅是一个强大的文本分析工具,更是连接计算机科学和人文研究的桥梁。随着技术的不断进步,BookNLP必将在数字人文和文学计算研究中发挥越来越重要的作用。
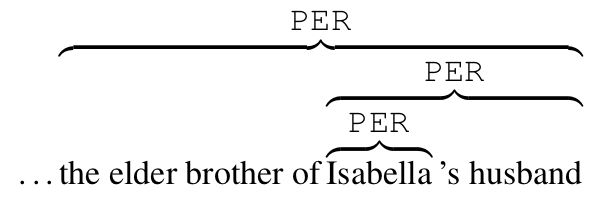
图1: BookNLP的嵌套实体结构示例
对于研究者来说,BookNLP开启了文本分析的新篇章。它让我们能以前所未有的规模和深度探索文学作品,揭示隐藏在文本中的模式和洞见。未来,随着更多语言的支持和性能的提升,BookNLP有望成为数字人文研究的标准工具之一。



















