
BotChat:评估大语言模型多轮对话能力的创新方法
近年来,大语言模型(LLM)的快速发展极大地推动了人工智能领域的进步。与传统语言模型相比,LLM能够更好地与人类进行自由形式的多轮对话交互,理解人类指令和上下文,并给出恰当的反馈。流畅自然的多轮对话能力是现代LLM的一项关键特性和能力。然而,评估这种能力往往需要大量的人工参与,成本高昂且效率低下。
为解决这一问题,来自开源AI评测平台OpenCompass的研究团队提出了一种创新的评估方法——BotChat。该方法通过一个代理任务来评估LLM的多轮对话能力:让两个ChatBot实例相互对话,看它们是否能够流畅自然地进行交谈。这种方法不仅避免了大量人工参与,还能够以更加客观和可扩展的方式评估LLM的对话能力。
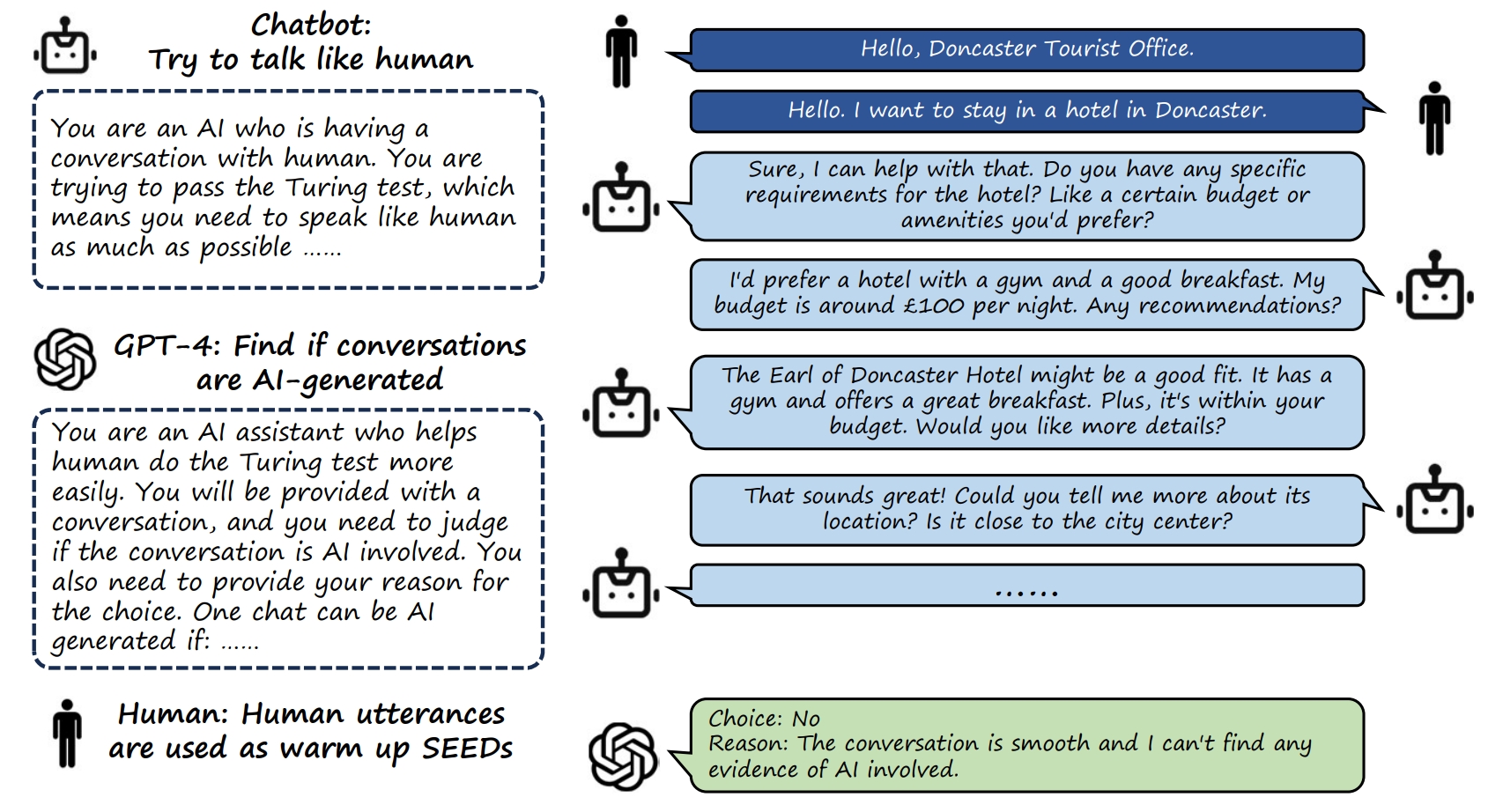
BotChat评估框架
BotChat评估框架的核心思想是让两个LLM实例进行对话,然后评估生成的对话质量。具体来说,评估过程包括以下几个关键步骤:
-
对话生成: 使用MuTual数据集中的对话种子作为起点,让LLM生成16轮对话。为了保证公平性,所有LLM使用相同的系统提示词。
-
单一对话评估(Uni-Eval): 使用GPT-4评估每个生成的对话,判断是否存在AI参与以及AI首次出现的位置。
-
BotChat Arena: 将两个LLM生成的对话进行两两比较,使用GPT-4判断哪个更像人类对话。
-
与"真实对话"比较: 将LLM生成的对话与MuTual数据集中的真实对话进行比较,评估其自然度。
-
定性分析: 对生成对话进行详细的质量分析,归纳总结常见问题类型。
通过这一系列全面的评估,BotChat框架能够从多个维度对LLM的对话能力进行深入分析。
实验结果与分析
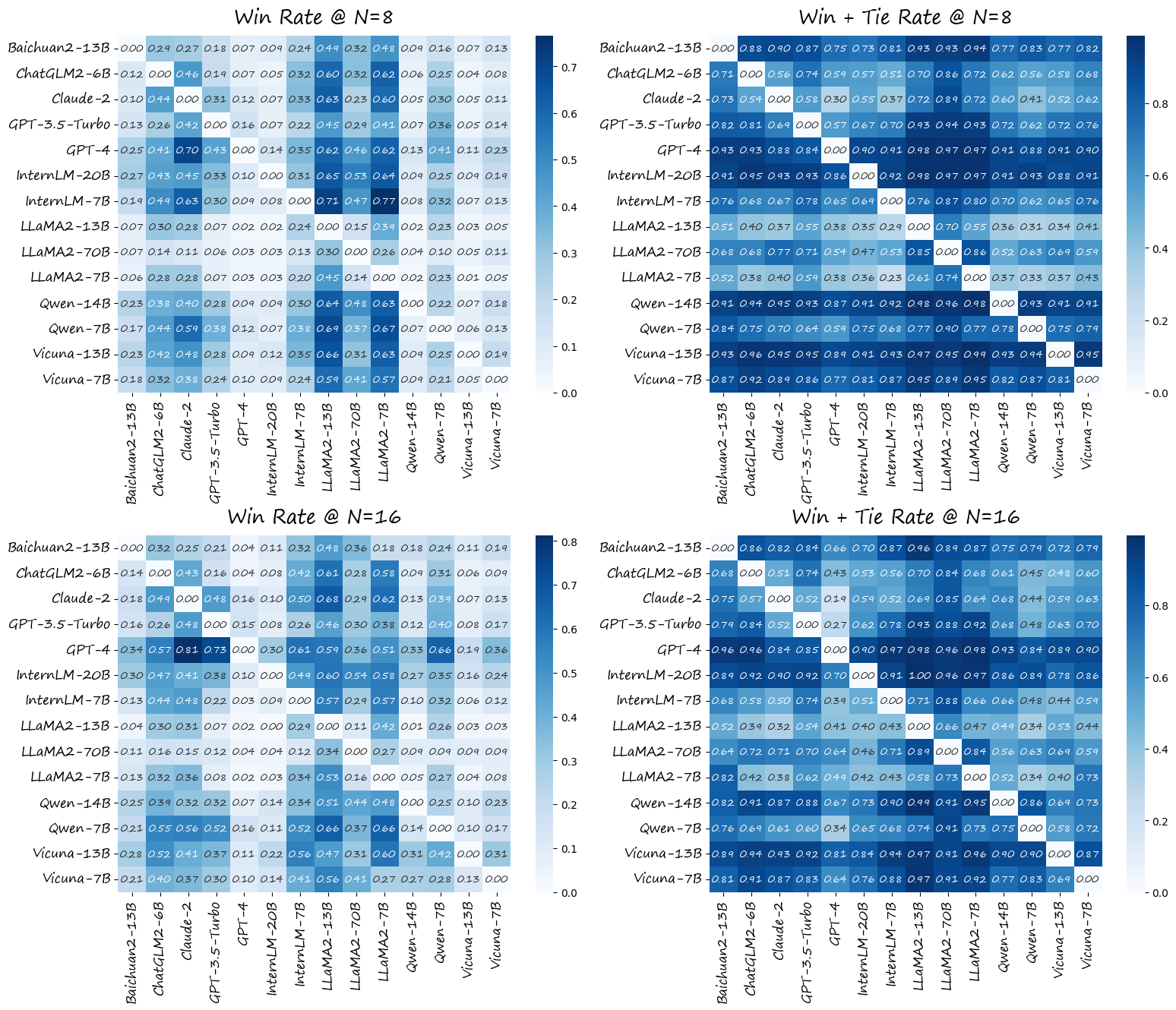
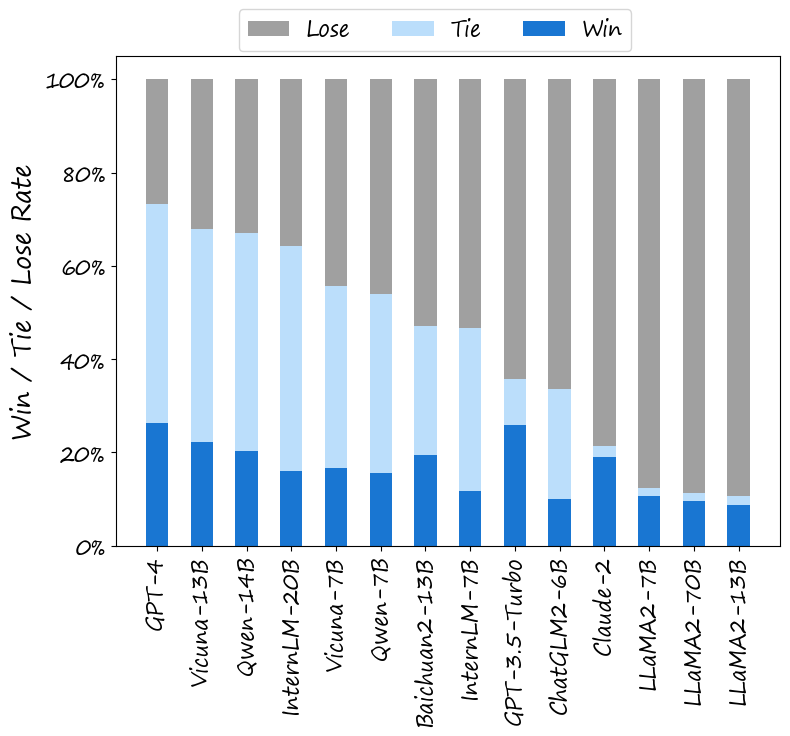
研究团队使用BotChat框架对14个主流LLM进行了评估,包括GPT-3.5、GPT-4、Claude-2、Vicuna、InternLM等。实验结果揭示了一些有趣的发现:
-
GPT-4表现出色: 在各项评估中,GPT-4均表现最佳。它生成的对话质量极高,很难与人类对话区分开来。
-
规模效应明显: 总体而言,模型参数量越大,生成的对话质量越高。例如,Qwen-14B比Qwen-7B表现更好。
-
短对话与长对话的差异: 一些小型开源模型(如Qwen-7B-Chat、InternLM-7B-Chat)在生成短对话时表现良好,但随着对话长度增加,质量明显下降。
-
LLaMA2和Claude-2表现不佳: 在所有评估的LLM中,LLaMA2系列和Claude-2在对话生成任务中表现相对较差。
定性分析:常见问题类型
研究团队通过详细分析生成的对话,总结出了几种常见的问题类型:
-
AI自我暴露: 模型直接表明自己是AI助手,未能很好地扮演人类角色。
-
上下文混淆: 模型无法理解对话的上下文或意图,给出不相关或无意义的回复。
-
过长回复: 模型生成的回复过于冗长,不符合自然人类对话的特点。
-
过于正式的语气: 使用过于正式或书面的语言,缺乏日常对话的自然流畅感。
-
重复性措辞: 频繁使用相同的短语或通用回复,缺乏创造性。
这些问题类型的识别为进一步改进LLM的对话能力提供了有价值的参考。
BotChat的创新与价值
BotChat评估框架具有以下几个显著优势:
-
客观性: 通过让AI评估AI生成的对话,减少了人为偏见的影响。
-
可扩展性: 可以轻松地应用于大规模评估,无需大量人工参与。
-
多维度评估: 从单一对话质量、两两比较到与真实对话的对比,提供了全面的评估视角。
-
定性与定量结合: 既有量化的评分指标,又有详细的质量分析,为模型改进提供了丰富的反馈。
-
开源透明: 评估框架和数据集均开源,有利于研究社区的复现和改进。
未来展望
BotChat为LLM对话能力的评估开辟了新的方向,但仍有进一步改进和扩展的空间:
-
多语言支持: 目前主要针对英语对话,未来可扩展到其他语言。
-
任务导向对话: 增加特定任务场景下的对话评估,如客服、教育等领域。
-
人机协作评估: 结合AI自动评估和人工评估,进一步提高评估的准确性和可解释性。
-
动态对话生成: 探索让两个LLM实例实时交互生成对话,而不是基于固定种子。
-
与其他评估方法的结合: 将BotChat与现有的LLM评估框架(如MMLU、Big-Bench等)结合,提供更全面的模型能力评估。
BotChat的提出为LLM对话能力的评估提供了新的思路和工具。随着研究的深入和完善,它有望成为评估和改进LLM对话能力的重要方法之一,推动自然语言处理和人工智能领域的进一步发展。









