
Chat-UniVi:图像与视频理解的统一视觉表征模型
近年来,大语言模型(LLM)在自然语言处理领域取得了巨大的进展。然而,在多模态理解方面,尤其是同时处理图像和视频的能力上,仍存在很大的挑战。为了解决这一问题,来自北京大学的研究团队提出了一个创新的模型 - Chat-UniVi。
统一的视觉表征框架
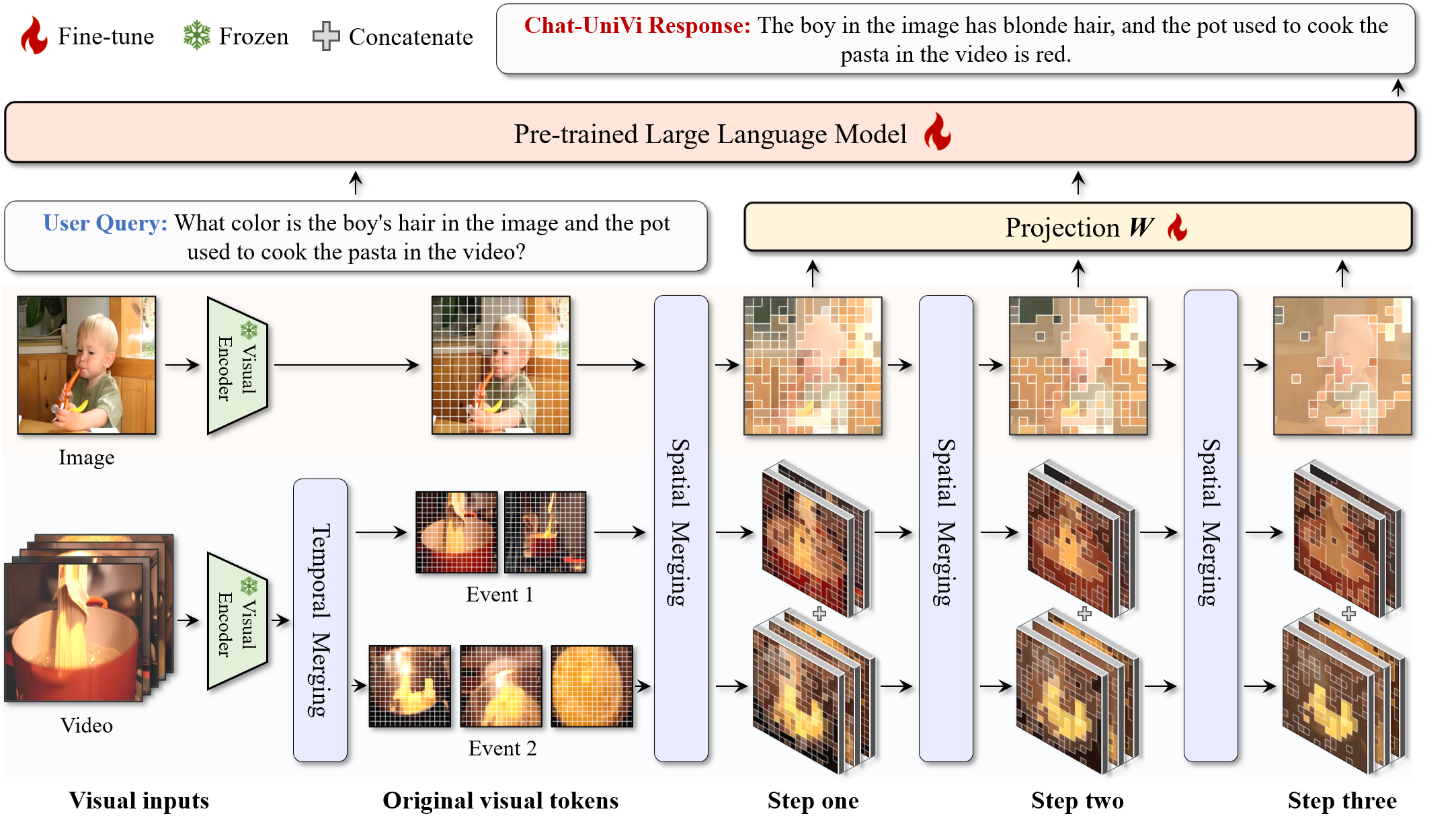
Chat-UniVi的核心创新在于其统一的视觉表征框架。该模型采用了一组动态视觉令牌来统一表示图像和视频。这种设计使模型能够高效地利用有限数量的视觉令牌,同时捕捉图像所需的空间细节和视频所需的全面时序关系。
具体来说,Chat-UniVi使用了多尺度表示方法,使大语言模型能够同时感知高层语义概念和低层视觉细节。这种设计不仅提高了模型的理解能力,还有效地减少了视觉令牌的数量,大大提升了训练和推理的效率。

联合训练策略
Chat-UniVi采用了一种独特的联合训练策略。模型在包含图像和视频的混合数据集上进行训练,这使得它能够直接应用于涉及两种媒体的任务,而无需任何修改。这种训练方法不仅提高了模型的灵活性,还实现了图像和视频理解能力的互补学习。
卓越的性能表现
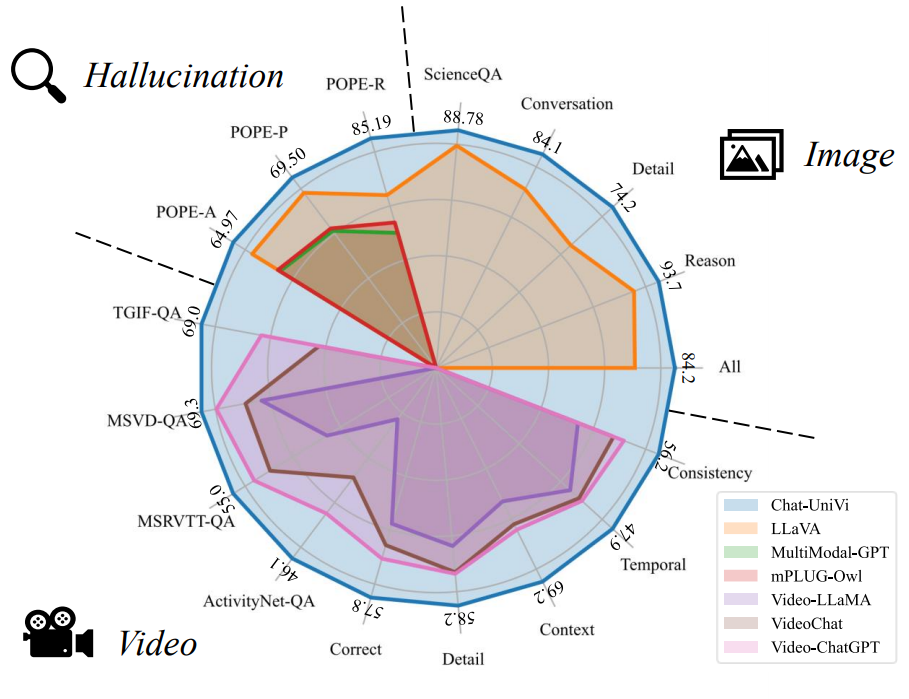
经过大量实验,Chat-UniVi展现出了令人印象深刻的性能。作为一个统一模型,它在多项任务上的表现甚至超过了专门为图像或视频设计的现有方法。这种优异的性能不仅体现在常规的理解任务上,还包括一些具有挑战性的场景,如零样本视频问答和科学问答等。
在图像理解方面,Chat-UniVi采用了与LLaVA相同的评估方法,即报告相对于GPT-4的指令遵循问题的相对分数。结果显示,Chat-UniVi在多个基准测试中表现出色。
对于视频理解,Chat-UniVi遵循Video-ChatGPT的评估协议,使用GPT辅助评估来衡量模型的能力。评分被标准化到0-100的范围内。在MSRVTT-QA、MSVD-QA、TGIF-QA和ActivityNet-QA等多个数据集上,Chat-UniVi都取得了竞争力强的结果。
特别值得一提的是,在ScienceQA测试集上,Chat-UniVi同时报告了零样本和微调结果,展示了其在科学领域问答方面的潜力。
此外,在对象幻觉基准测试(POPE)中,Chat-UniVi也取得了令人瞩目的成绩,显示了其在减少视觉幻觉方面的优势。
模型架构与实现
Chat-UniVi基于大语言模型构建,目前有7B和13B两个版本。模型采用了高效的参数设计,使得即使是13B版本也能在8张A100 GPU上在3天内完成全参数训练。这种高效的设计大大降低了模型的训练成本,使其更容易被广泛应用和研究。
在实现方面,Chat-UniVi提供了完整的代码和详细的使用说明。研究者可以通过Hugging Face模型库或本地加载方式使用Chat-UniVi。模型支持视频理解和图像理解的推理,并提供了易于使用的API。
应用示例与可视化
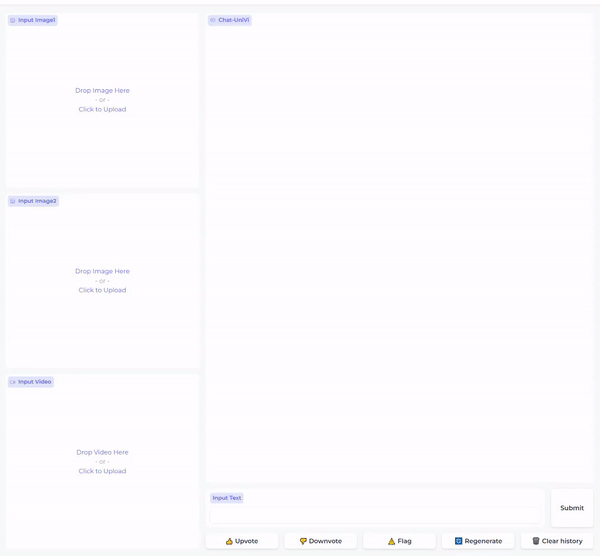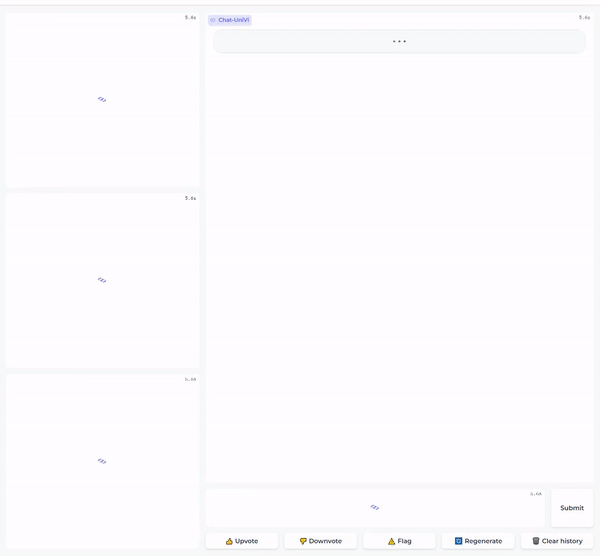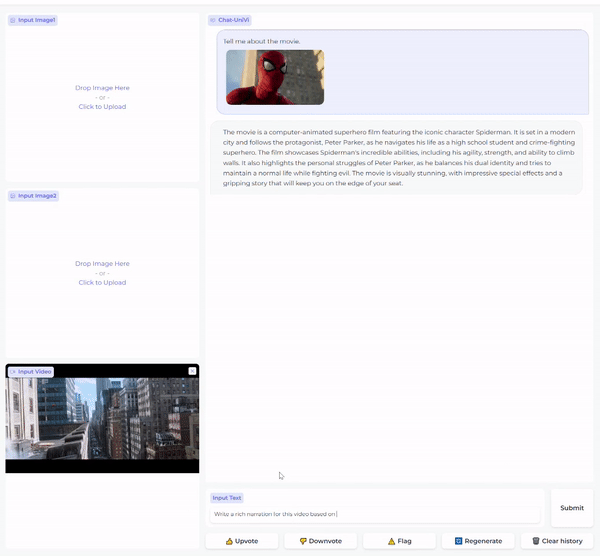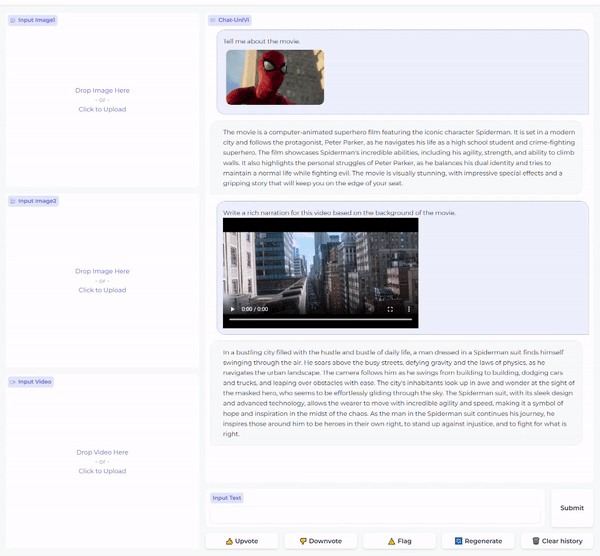
Chat-UniVi展示了多种实际应用场景,包括同时处理图像和视频的对话、多视频对话、多图像对话等。模型还支持中文对话,显示了其多语言处理能力。
在可视化方面,Chat-UniVi提供了图像和视频输入的可视化工具,帮助研究者更好地理解模型的工作原理和注意力机制。
未来展望
作为一个统一的视觉-语言模型,Chat-UniVi为多模态人工智能的发展开辟了新的道路。它不仅在性能上取得了突破,还提供了一个灵活、高效的框架来处理复杂的多模态任务。
未来,研究团队计划进一步优化模型,探索更多的应用场景,并推动模型在实际应用中的部署。随着Chat-UniVi的不断发展,我们可以期待看到更多令人兴奋的多模态AI应用出现在各个领域。
总的来说,Chat-UniVi代表了多模态AI研究的一个重要里程碑。它不仅推动了技术的进步,还为未来的人机交互和智能系统设计提供了新的可能性。随着这项技术的不断成熟,我们可以期待看到更多创新的应用,从智能教育到自动内容分析,再到高级人机对话系统,Chat-UniVi都有潜力带来革命性的变革。










