
ColBERT简介
ColBERT(Contextualized Late Interaction over BERT)是由斯坦福大学未来数据实验室开发的一种先进的神经网络搜索模型。它能够在保持高精度的同时,实现对大规模文本集合的快速检索,通常只需几十毫秒就能完成搜索。
ColBERT的核心思想是"细粒度的上下文后期交互"。它首先将每个文档编码为一个token级别的嵌入矩阵,然后在搜索时将查询也编码为一个矩阵,并使用高效的向量相似度运算符(如MaxSim)来找到与查询在上下文中最匹配的文档。这种丰富的交互使ColBERT能够超越单向量表示模型的质量,同时又能高效地扩展到大型语料库。
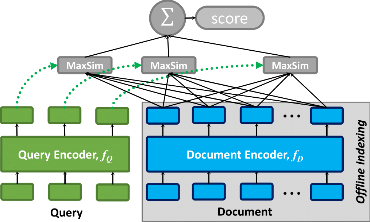
如上图所示,ColBERT的检索过程可以分为以下几个步骤:
- 文档编码:将每个文档编码为一个token级别的嵌入矩阵(图中蓝色部分)。
- 查询编码:在搜索时,将查询编码为另一个矩阵(图中绿色部分)。
- 相似度计算:使用高效的向量相似度运算符(如MaxSim)来计算查询和文档之间的细粒度上下文匹配程度。
- 排序:根据相似度得分对文档进行排序,返回最相关的结果。
ColBERT的主要特点
-
高效性:ColBERT能够在几十毫秒内完成对大规模文本集合的搜索,这使得它非常适合实时搜索应用。
-
高精度:通过细粒度的上下文交互,ColBERT能够捕捉到查询和文档之间更细微的语义关系,从而提供更准确的搜索结果。
-
可扩展性:ColBERT的设计使其能够高效地扩展到大型语料库,这对于处理现实世界的大规模数据集至关重要。
-
灵活性:ColBERT可以应用于各种自然语言处理任务,如文档检索、问答系统和多跳推理等。
-
开源实现:ColBERT的代码已在GitHub上开源,这使得研究人员和开发者可以方便地使用和改进这个模型。
ColBERT的应用流程
使用ColBERT通常涉及以下几个步骤:
-
数据预处理:将文档集合和查询转换为tab分隔(TSV)文件格式。
-
模型准备:下载预训练的ColBERTv2检查点,或者训练自己的ColBERT模型。
-
索引构建:使用ColBERT模型对文档集合进行索引,这将文档编码为矩阵并存储在磁盘上,同时构建高效搜索所需的数据结构。
-
检索:使用构建好的索引,对给定的查询进行检索,返回最相关的文档。
让我们详细了解这些步骤:
数据预处理
ColBERT使用简单的tab分隔文件格式来存储查询、文档集合和排序结果:
- 查询文件:每行格式为
qid\tquery text - 文档集合文件:每行格式为
pid\tpassage text - 排序结果文件:每行格式为
qid\tpid\trank
这种格式与MS MARCO Passage Ranking数据集的格式兼容,方便研究人员直接使用现有的数据集。
模型准备
ColBERT提供了一个预训练的ColBERTv2检查点,该检查点在MS MARCO Passage Ranking任务上进行了训练。用户可以直接下载并使用这个检查点,也可以选择训练自己的ColBERT模型。
训练ColBERT模型需要准备一个JSONL格式的三元组文件,每行包含 [qid, pid+, pid-],分别表示查询ID、相关文档ID和不相关文档ID。ColBERT支持两种训练方式:
- 基础训练(ColBERTv1风格):
from colbert.infra import Run, RunConfig, ColBERTConfig
from colbert import Trainer
if __name__ == '__main__':
with Run().context(RunConfig(nranks=4, experiment="msmarco")):
config = ColBERTConfig(
bsize=32,
root="/path/to/experiments",
)
trainer = Trainer(
triples="/path/to/MSMARCO/triples.train.small.tsv",
queries="/path/to/MSMARCO/queries.train.small.tsv",
collection="/path/to/MSMARCO/collection.tsv",
config=config,
)
checkpoint_path = trainer.train()
print(f"Saved checkpoint to {checkpoint_path}...")
- 高级训练(ColBERTv2风格):
from colbert.infra.run import Run
from colbert.infra.config import ColBERTConfig, RunConfig
from colbert import Trainer
def train():
with Run().context(RunConfig(nranks=4)):
triples = '/path/to/examples.64.json'
queries = '/path/to/MSMARCO/queries.train.tsv'
collection = '/path/to/MSMARCO/collection.tsv'
config = ColBERTConfig(bsize=32, lr=1e-05, warmup=20_000, doc_maxlen=180, dim=128,
attend_to_mask_tokens=False, nway=64, accumsteps=1,
similarity='cosine', use_ib_negatives=True)
trainer = Trainer(triples=triples, queries=queries, collection=collection, config=config)
trainer.train(checkpoint='colbert-ir/colbertv1.9')
if __name__ == '__main__':
train()
索引构建
为了实现快速检索,ColBERT需要预先计算文档的表示并构建索引。索引构建过程如下:
from colbert.infra import Run, RunConfig, ColBERTConfig
from colbert import Indexer
if __name__ == '__main__':
with Run().context(RunConfig(nranks=1, experiment="msmarco")):
config = ColBERTConfig(
nbits=2,
root="/path/to/experiments",
)
indexer = Indexer(checkpoint="/path/to/checkpoint", config=config)
indexer.index(name="msmarco.nbits=2", collection="/path/to/MSMARCO/collection.tsv")
这个过程会将文档编码为矩阵,存储在磁盘上,并构建用于高效搜索的数据结构。
检索
有了索引后,我们就可以进行高效的检索了。ColBERT支持端到端检索,可以直接从全集合中找到与查询最相关的前k个文档:
from colbert.data import Queries
from colbert.infra import Run, RunConfig, ColBERTConfig
from colbert import Searcher
if __name__ == '__main__':
with Run().context(RunConfig(nranks=1, experiment="msmarco")):
config = ColBERTConfig(
root="/path/to/experiments",
)
searcher = Searcher(index="msmarco.nbits=2", config=config)
queries = Queries("/path/to/MSMARCO/queries.dev.small.tsv")
ranking = searcher.search_all(queries, k=100)
ranking.save("msmarco.nbits=2.ranking.tsv")
用户可以通过指定 ncells、centroid_score_threshold 和 ndocs 等搜索超参数来权衡速度和结果质量。
ColBERT的实际应用
ColBERT在多个自然语言处理任务中展现出了优秀的性能,包括但不限于:
-
文档检索:ColBERT在MS MARCO Passage Ranking等标准基准测试中取得了优异的成绩。
-
开放域问答:ColBERT被用于构建高效的检索器,为开放域问答系统提供相关上下文。
-
多跳推理:ColBERT的变体Baleen被用于实现大规模的多跳推理。
-
领域适应:UDAPDR利用ColBERT进行无监督的领域适应,提高了跨领域的检索性能。
ColBERT的未来发展
随着自然语言处理技术的不断进步,ColBERT也在持续evolving。一些值得关注的发展方向包括:
-
模型压缩:通过量化、剪枝等技术进一步减小模型大小,提高检索效率。
-
多模态扩展:将ColBERT的思想扩展到图像、视频等多模态数据的检索中。
-
与大型语言模型的结合:探索ColBERT与GPT等大型语言模型的协同,提升检索和生成的质量。
-
实时更新:研究如何在不重新构建整个索引的情况下,实现文档集合的实时更新。
-
可解释性:提高模型的可解释性,帮助用户理解为什么某些文档被排在前面。
结语
ColBERT作为一种高效精准的神经网络搜索模型,为大规模文本检索提供了一个强大的解决方案。它不仅在学术研究中取得了显著成果,也在实际应用中展现出巨大潜力。随着技术的不断演进和社区的持续贡献,我们有理由相信ColBERT将在未来的信息检索和自然语言处理领域发挥更加重要的作用。
无论您是研究人员、开发者还是对先进搜索技术感兴趣的爱好者,ColBERT都值得您深入探索和尝试。它开源的特性使得每个人都有机会参与到这个激动人心的技术发展中来,共同推动信息检索技术的边界。

要开始使用ColBERT,您可以访问其GitHub仓库获取最新的代码和文档。同时,ColBERT的研究团队也在持续发布相关论文和更新,关注他们的工作将有助于您更好地理解和应用这项技术。让我们一起期待ColBERT在信息检索领域带来的更多突破和创新!













