
CoMoSpeech:基于一致性模型的单步语音和歌声合成
CoMoSpeech是一种创新的语音合成方法,由Zhen Ye、Wei Xue、Xu Tan等人于2023年提出。该方法巧妙地结合了扩散概率模型(DDPMs)和一致性模型的优势,实现了高效率、高质量的语音和歌声合成。
背景与挑战
近年来,扩散概率模型(DDPMs)在语音合成领域展现出了巨大的潜力,能够生成高质量的语音样本。然而,DDPMs通常需要大量的迭代步骤来保证样本质量,这严重限制了其推理速度。如何在保持语音质量的同时提高采样速度,成为了一个亟待解决的挑战。
CoMoSpeech的创新之处
CoMoSpeech提出了一种基于一致性模型的语音合成方法,其核心创新点包括:
-
单步采样: 通过一致性约束,CoMoSpeech实现了单步扩散采样,大幅提升了推理速度。
-
教师模型蒸馏: 从精心设计的基于扩散的教师模型中蒸馏出一个一致性模型,保证了合成语音的高质量。
-
多任务适用性: 不仅适用于文本到语音(TTS)任务,还能很好地处理歌声合成等更复杂的任务。
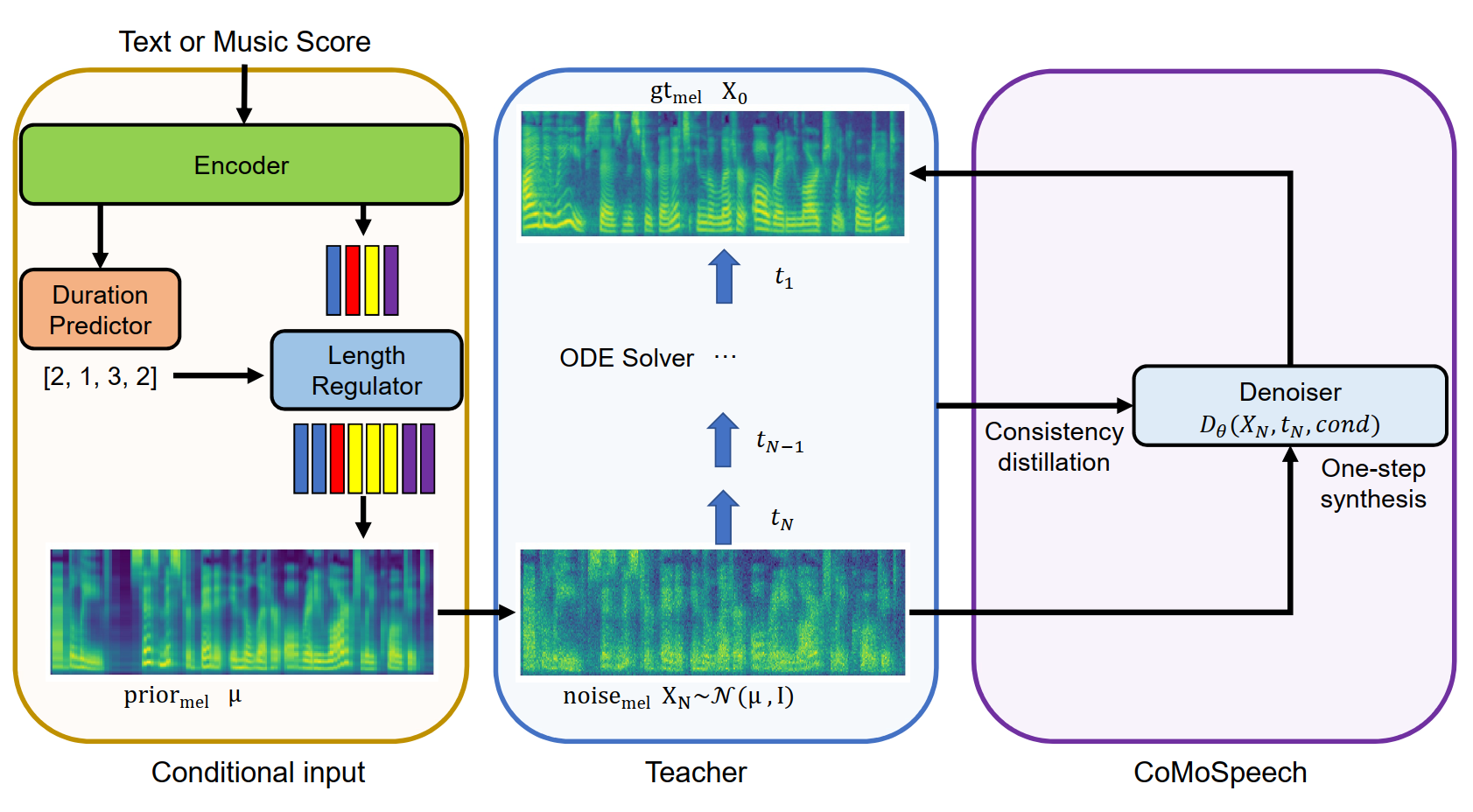
图1: CoMoSpeech的工作原理示意图。通过一致性约束,将教师模型的多步采样过程压缩为单步。
实验结果与性能
CoMoSpeech在多个方面展现出了卓越的性能:
-
推理速度: 在单个NVIDIA A100 GPU上,CoMoSpeech的推理速度比实时快150多倍,与FastSpeech2相当。
-
音频质量: 在文本到语音(TTS)和歌声合成任务中,CoMoSpeech生成的音频质量优于或可比于其他传统的多步扩散模型基线。
-
实用性: 单步采样的高效率使得基于扩散采样的语音合成真正具备了实用价值。
技术细节
CoMoSpeech的核心技术包括:
-
一致性约束: 通过引入一致性约束,使模型能够在单步中生成高质量语音。
-
教师模型设计: 精心设计的基于扩散的教师模型为一致性模型的蒸馏提供了良好基础。
-
条件输入处理: 针对TTS和歌声合成等不同任务,设计了适合的条件输入处理方法。
最新进展
CoMoSpeech团队持续对该技术进行改进和扩展:
- 2024年4月,提出了基于潜在一致性模型和对抗训练的零样本语音合成器FlashSpeech。
- 2023年12月,开发了基于一致性模型的歌声转换(SVC)版本。
- 2023年11月,发现使用零均值高斯噪声替代grad-tts中的先验也能达到类似性能。
- 2023年10月,为教师模型添加了Heun二阶方法支持,可用于教师模型采样和一致性蒸馏的更好ODE轨迹。
应用与展望
CoMoSpeech为语音合成领域带来了新的可能性:
-
高效TTS系统: 能够在保证音质的同时,大幅提升语音合成的速度,适用于各种实时应用场景。
-
歌声合成: 在处理复杂的歌声合成任务时也表现出色,为音乐制作领域提供了新工具。
-
低资源设备: 单步采样的特性使得CoMoSpeech有潜力在计算资源有限的设备上运行。
-
个性化语音: 通过进一步研究,有望实现更灵活、更个性化的语音合成。
开源与社区
CoMoSpeech项目已在GitHub上开源,得到了广泛关注:
- GitHub仓库获得了176颗星和18次fork。
- 项目提供了详细的使用说明,包括环境准备、推理和训练等步骤。
- 研究者们可以基于提供的代码和预训练模型进行进一步的探索和改进。
结语
CoMoSpeech的出现标志着语音合成技术进入了一个新的阶段。通过巧妙结合扩散模型和一致性模型的优势,CoMoSpeech在效率和质量之间找到了理想的平衡点。这一突破不仅推动了学术研究的进展,也为语音合成技术的实际应用铺平了道路。随着技术的不断完善和社区的持续贡献,我们有理由期待CoMoSpeech及其衍生技术在未来带来更多令人兴奋的应用。









