
Comprehensive-Transformer-TTS: 打造最先进的文本转语音系统
Comprehensive-Transformer-TTS是一个基于PyTorch实现的非自回归Transformer文本转语音(TTS)系统。该项目旨在支持多种先进的Transformer模型,并结合有监督和无监督的持续时间建模技术,以实现高质量的语音合成。作为一个不断发展的开源项目,Comprehensive-Transformer-TTS致力于与研究社区共同进步,最终达成打造最佳非自回归TTS系统的目标。
主要特点
-
非自回归架构: 采用非自回归设计,具有稳定性高、推理速度快、可控性强等优势。
-
多种Transformer模型: 支持包括Fastformer、Long-Short Transformer、Conformer、Reformer等在内的多种先进Transformer模型。
-
灵活的持续时间建模: 同时支持有监督和无监督的持续时间建模方法。
-
丰富的韵律建模: 集成了多种韵律建模技术,如DelightfulTTS和基于手机级混合密度网络的方法。
-
高度可定制: 通过配置文件可以灵活切换不同的模型结构、韵律建模和持续时间建模方法。
-
多说话人支持: 支持单说话人和多说话人TTS,可用于各种应用场景。
核心技术
Comprehensive-Transformer-TTS融合了多项前沿的TTS技术,主要包括:
-
Transformer变体:
- Fastformer: 采用加性注意力机制,提高效率
- Long-Short Transformer: 高效处理长序列
- Conformer: 结合卷积和Transformer,适用于语音识别
- Reformer: 通过局部敏感哈希提高效率
- 原始Transformer: 经典的自注意力架构
-
韵律建模:
- DelightfulTTS: 微软在Blizzard Challenge 2021中使用的语音合成系统
- 基于手机级混合密度网络的丰富韵律多样性建模
-
持续时间建模:
- 有监督方法: 基于FastSpeech 2的方法
- 无监督方法: 基于"One TTS Alignment To Rule Them All"的技术,无需外部对齐器
-
声码器支持:
- HiFi-GAN
- MelGAN
性能对比
项目对不同Transformer变体在LJSpeech数据集上进行了性能对比测试,结果如下:
| 模型 | 内存使用 | 训练时间(1K步) |
|---|---|---|
| Fastformer (lucidrains') | 10531MiB / 24220MiB | 4m 25s |
| Fastformer (wuch15's) | 10515MiB / 24220MiB | 4m 45s |
| Long-Short Transformer | 10633MiB / 24220MiB | 5m 26s |
| Conformer | 18903MiB / 24220MiB | 7m 4s |
| Reformer | 10293MiB / 24220MiB | 10m 16s |
| Transformer | 7909MiB / 24220MiB | 4m 51s |
| Transformer_fs2 | 11571MiB / 24220MiB | 4m 53s |
从结果可以看出,不同模型在内存使用和训练速度上存在差异,用户可以根据具体需求选择合适的模型。
快速上手
要开始使用Comprehensive-Transformer-TTS,您需要按照以下步骤操作:
- 安装依赖:
pip3 install -r requirements.txt
2. **准备数据集**:
项目支持LJSpeech(单说话人)和VCTK(多说话人)数据集。您也可以按照类似方式添加自己的数据集。
3. **数据预处理**:
运行`prepare_align.py`和`preprocess.py`脚本进行数据预处理。
4. **模型训练**:
使用`train.py`脚本训练模型,可以通过配置文件调整各种参数。
5. **语音合成**:
训练完成后,使用`synthesize.py`脚本生成语音。
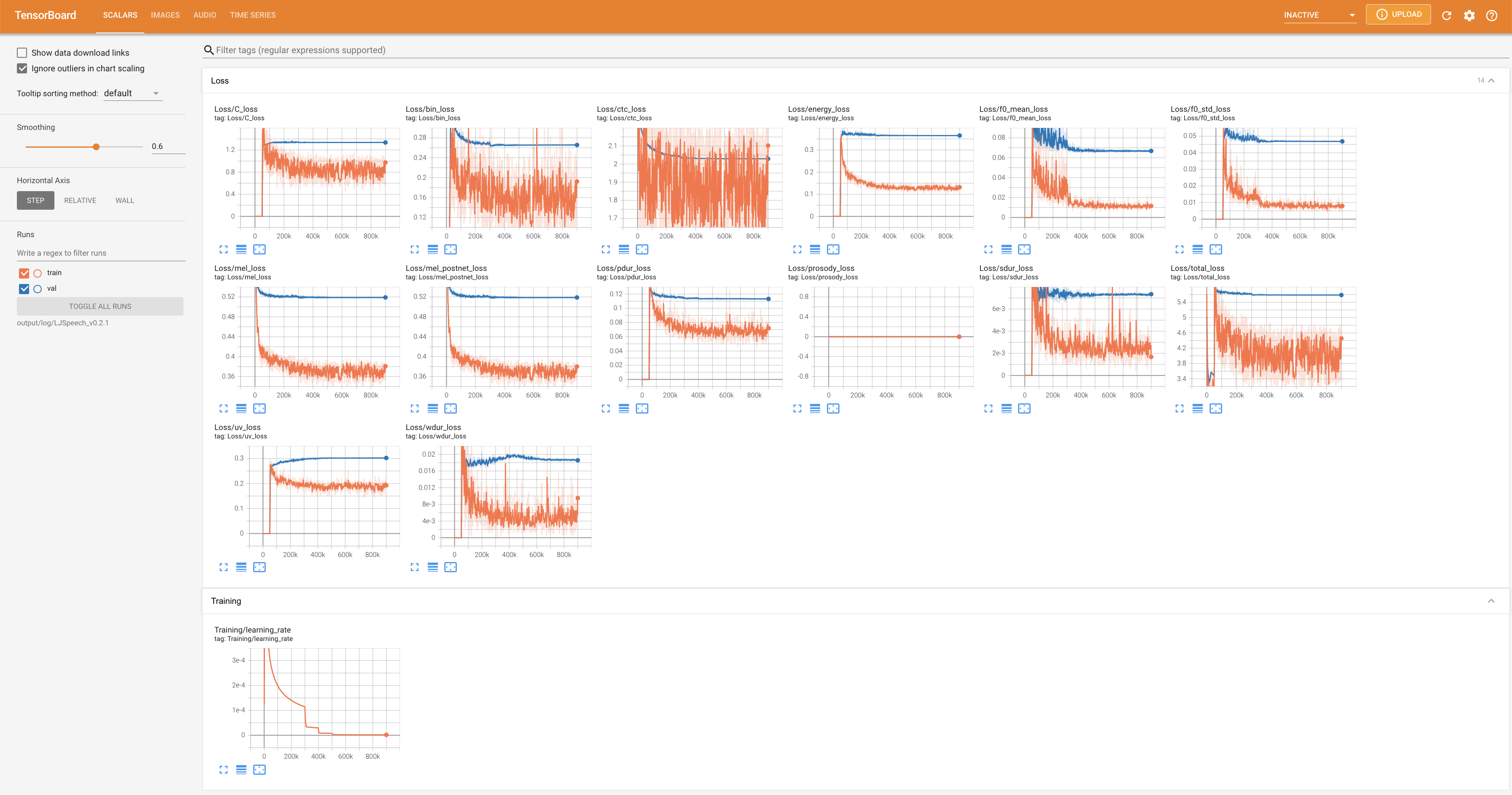
### 可视化与监控
项目提供了TensorBoard支持,可以实时监控训练过程中的损失曲线、合成的梅尔频谱图和音频样本。使用以下命令启动TensorBoard:
tensorboard --logdir output/log
### 消融实验
项目进行了详细的消融实验,比较了不同模块对模型性能的影响:
1. **模型结构对比**: "transformer_fs2"在内存使用和模型大小方面更优化,训练时间和梅尔损失更低。但输出质量并未显著提升,有时"transformer"块生成的语音音高轮廓更稳定。
2. **音高条件对比**: 音频质量和表现力之间存在权衡:
- 音频质量: "ph" >= "frame" > "cwt"
- 表现力: "cwt" > "frame" > "ph"
这些实验结果为用户选择合适的模型配置提供了参考。
### 最新更新
项目持续更新,最近的主要更新包括:
- v0.2.1 (2022年3月5日): 修复和更新代码库,提供预训练模型和演示样本
- v0.2.0 (2022年2月18日): 更新数据预处理器和方差适配器,添加多种韵律建模方法
### 总结
Comprehensive-Transformer-TTS作为一个全面的非自回归TTS系统,集成了多项先进技术,为研究人员和开发者提供了一个强大的实验平台。通过灵活的配置和丰富的功能,用户可以探索不同的模型结构和训练策略,以实现高质量的语音合成。
项目的开源性质和持续更新也确保了它能够跟随TTS领域的最新进展不断发展。无论是学术研究还是实际应用,Comprehensive-Transformer-TTS都是一个值得关注和使用的优秀工具。
🔗 [项目GitHub地址](https://github.com/keonlee9420/Comprehensive-Transformer-TTS)
通过不断的改进和社区贡献,Comprehensive-Transformer-TTS有望在未来实现其成为"终极TTS系统"的宏伟目标。欢迎对非自回归TTS感兴趣的研究者和开发者加入这个激动人心的项目,共同推动语音合成技术的发展。


















