
Continuous-Eval: 为LLM应用提供全面评估的开源框架
在人工智能和大语言模型(LLM)快速发展的今天,如何有效评估和优化LLM驱动的应用成为了一个重要课题。Continuous-Eval应运而生,它是一个专为LLM应用设计的开源评估框架,旨在通过数据驱动的方法为开发者提供全面、精准的评估工具。本文将深入介绍Continuous-Eval的核心特性、使用方法以及它如何助力LLM应用的持续优化。
Continuous-Eval的核心特性
1. 模块化评估
Continuous-Eval的一大亮点是其模块化评估能力。它允许开发者对应用pipeline中的每个模块进行单独评估,使用针对性的指标。这种细粒度的评估方法使得开发者能够精确定位应用中的瓶颈或问题区域,从而进行有针对性的优化。
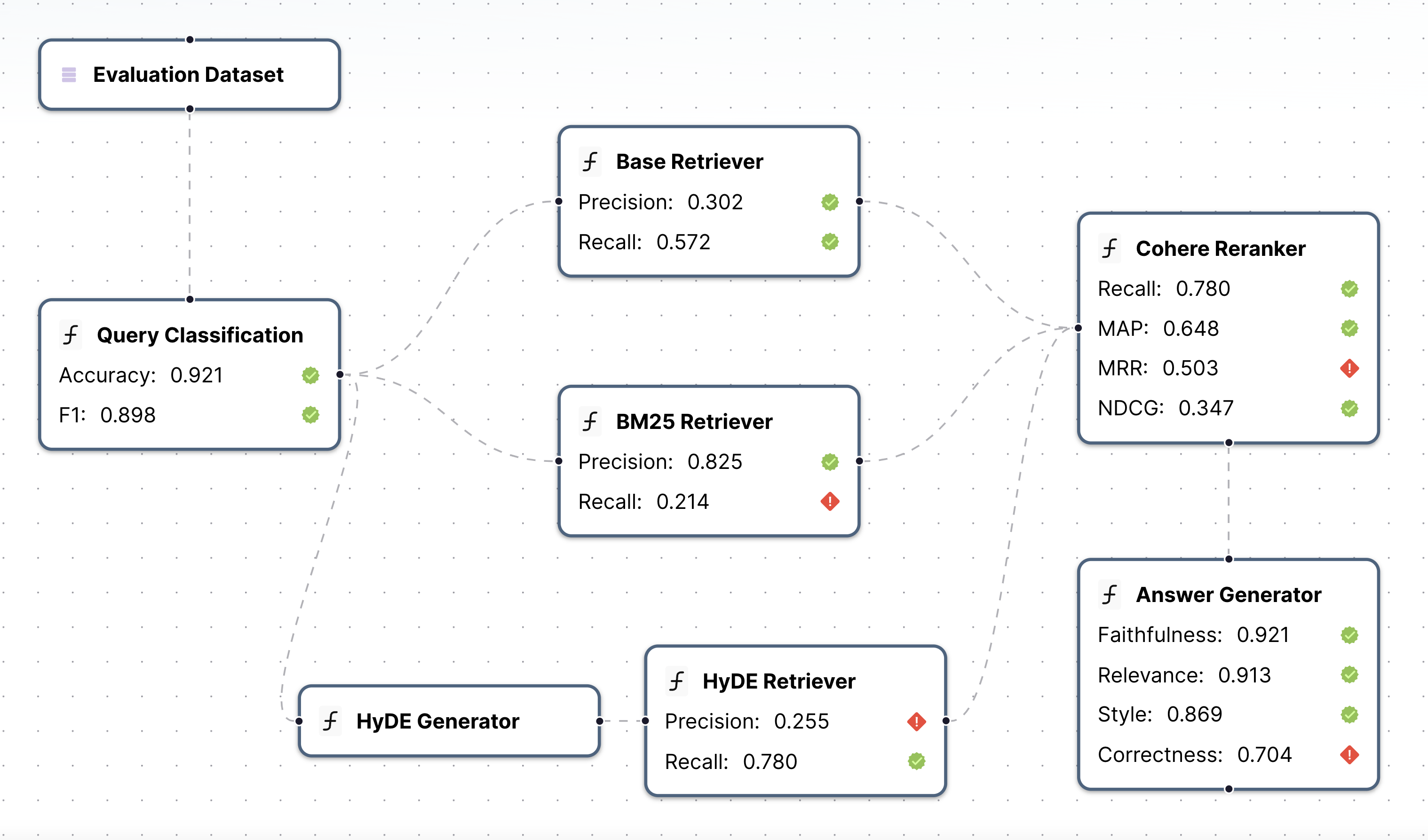
如上图所示,Continuous-Eval支持对检索、重排序、生成等多个环节进行独立评估,每个环节都可以应用特定的评估指标。
2. 全面的指标库
Continuous-Eval提供了一个全面的评估指标库,涵盖了多种LLM应用场景:
- 检索增强生成(RAG)
- 代码生成
- 智能体工具使用
- 分类任务
- 其他LLM使用场景
这些指标包括确定性指标、语义指标和基于LLM的指标,开发者可以根据需求灵活组合使用。例如,对于RAG系统,可以同时使用精确率、召回率、F1值等传统指标,以及基于LLM的上下文精确度和覆盖率指标,全方位评估系统性能。
3. 整合用户反馈
Continuous-Eval创新性地引入了用户反馈整合机制。开发者可以轻松构建一个接近人类评判的集成评估流程,并且具有数学保证。这一特性使得评估结果更贴近实际应用场景,提高了评估的可靠性和实用性。
4. 合成数据集生成
为解决高质量评估数据集稀缺的问题,Continuous-Eval提供了合成数据集生成功能。开发者可以生成大规模的合成数据集来测试其应用pipeline,这不仅节省了人工标注的时间和成本,还能覆盖更多的边缘情况,提高评估的全面性。
快速上手Continuous-Eval
Continuous-Eval的使用非常简单直观。首先,通过pip安装包:
python3 -m pip install continuous-eval
然后,你就可以开始使用各种评估指标了。以下是一个简单的例子,展示如何使用精确率、召回率和F1值来评估检索结果:
from continuous_eval.metrics.retrieval import PrecisionRecallF1
datum = {
"question": "What is the capital of France?",
"retrieved_context": [
"Paris is the capital of France and its largest city.",
"Lyon is a major city in France.",
],
"ground_truth_context": ["Paris is the capital of France."],
"answer": "Paris",
"ground_truths": ["Paris"],
}
metric = PrecisionRecallF1()
print(metric(**datum))
评估完整的应用Pipeline
Continuous-Eval的强大之处在于它能够评估整个应用pipeline。你可以定义pipeline中的各个模块,并为每个模块选择相应的评估指标:
from continuous_eval.eval import Module, ModuleOutput, Pipeline, Dataset, EvaluationRunner
from continuous_eval.eval.logger import PipelineLogger
from continuous_eval.metrics.retrieval import PrecisionRecallF1, RankedRetrievalMetrics
from continuous_eval.metrics.generation.text import DeterministicAnswerCorrectness
dataset = Dataset("dataset_folder")
# 定义一个简单的3步RAG pipeline: Retriever -> Reranker -> Generation
retriever = Module(
name="Retriever",
input=dataset.question,
output=List[str],
eval=[
PrecisionRecallF1().use(
retrieved_context=ModuleOutput(),
ground_truth_context=dataset.ground_truth_context,
),
],
)
reranker = Module(
name="reranker",
input=retriever,
output=List[Dict[str, str]],
eval=[
RankedRetrievalMetrics().use(
retrieved_context=ModuleOutput(),
ground_truth_context=dataset.ground_truth_context,
),
],
)
llm = Module(
name="answer_generator",
input=reranker,
output=str,
eval=[
DeterministicAnswerCorrectness().use(
answer=ModuleOutput(), ground_truth_answers=dataset.ground_truths
),
],
)
pipeline = Pipeline([retriever, reranker, llm], dataset=dataset)
定义好pipeline后,你可以使用EvaluationRunner来运行评估:
evalrunner = EvaluationRunner(pipeline)
metrics = evalrunner.evaluate(dataset)
print(metrics.results()) # 输出评估结果
合成数据生成
Continuous-Eval还提供了强大的合成数据生成功能。通过Relari平台,你可以生成定制的合成数据集,用于评估或训练。这些数据集可以模拟各种用户交互场景,如RAG系统、智能体、代码助手等,为你的评估提供更丰富的测试数据。
开源社区与贡献
Continuous-Eval是一个开源项目,欢迎社区贡献。如果你有兴趣参与项目开发,可以查看贡献指南了解更多详情。项目使用Apache 2.0许可证,鼓励自由使用和分发。
结语
Continuous-Eval为LLM应用开发者提供了一个强大而灵活的评估框架。通过模块化评估、全面的指标库、用户反馈整合和合成数据生成,它使得LLM应用的评估和优化变得更加简单和高效。无论你是在开发RAG系统、智能体还是其他类型的LLM应用,Continuous-Eval都能为你提供宝贵的洞察和改进方向。
随着LLM技术的不断发展,像Continuous-Eval这样的评估工具将在确保AI应用质量和可靠性方面发挥越来越重要的作用。我们期待看到更多开发者利用这个强大的工具,推动LLM应用向更高水平发展。
🔗 相关资源:
通过Continuous-Eval,让我们共同推动LLM应用评估的边界,为用户带来更优质、更可靠的AI体验! 🚀










