
CrossFormer简介
CrossFormer是由浙江大学和腾讯AI Lab联合提出的一种新型视觉Transformer模型。它的核心创新在于引入了跨尺度注意力机制,能够有效地处理不同尺度的视觉特征,从而在多个视觉任务上取得了优异的性能。
CrossFormer的主要特点包括:
-
跨尺度嵌入层(CEL):将输入嵌入与多尺度特征混合。
-
长短距离注意力机制(L/SDA):将嵌入分组,只在组内计算自注意力。
-
动态位置偏置(DPB):使相对位置偏置适用于可变图像大小。
-
渐进式分组策略(PGS):在性能和计算成本之间取得更好的平衡。
-
激活冷却层(ACL):抑制残差流中激活幅度的急剧增长。
这些创新设计使得CrossFormer能够有效地处理跨尺度的视觉信息,在图像分类、目标检测和语义分割等多个视觉任务中都表现出色。
CrossFormer的核心设计
跨尺度嵌入层(CEL)
跨尺度嵌入层是CrossFormer的一个关键组件。它的主要作用是将输入的嵌入与多个尺度的特征进行混合。这种设计使得模型能够捕捉到不同尺度的视觉信息,从而更好地理解图像的内容。
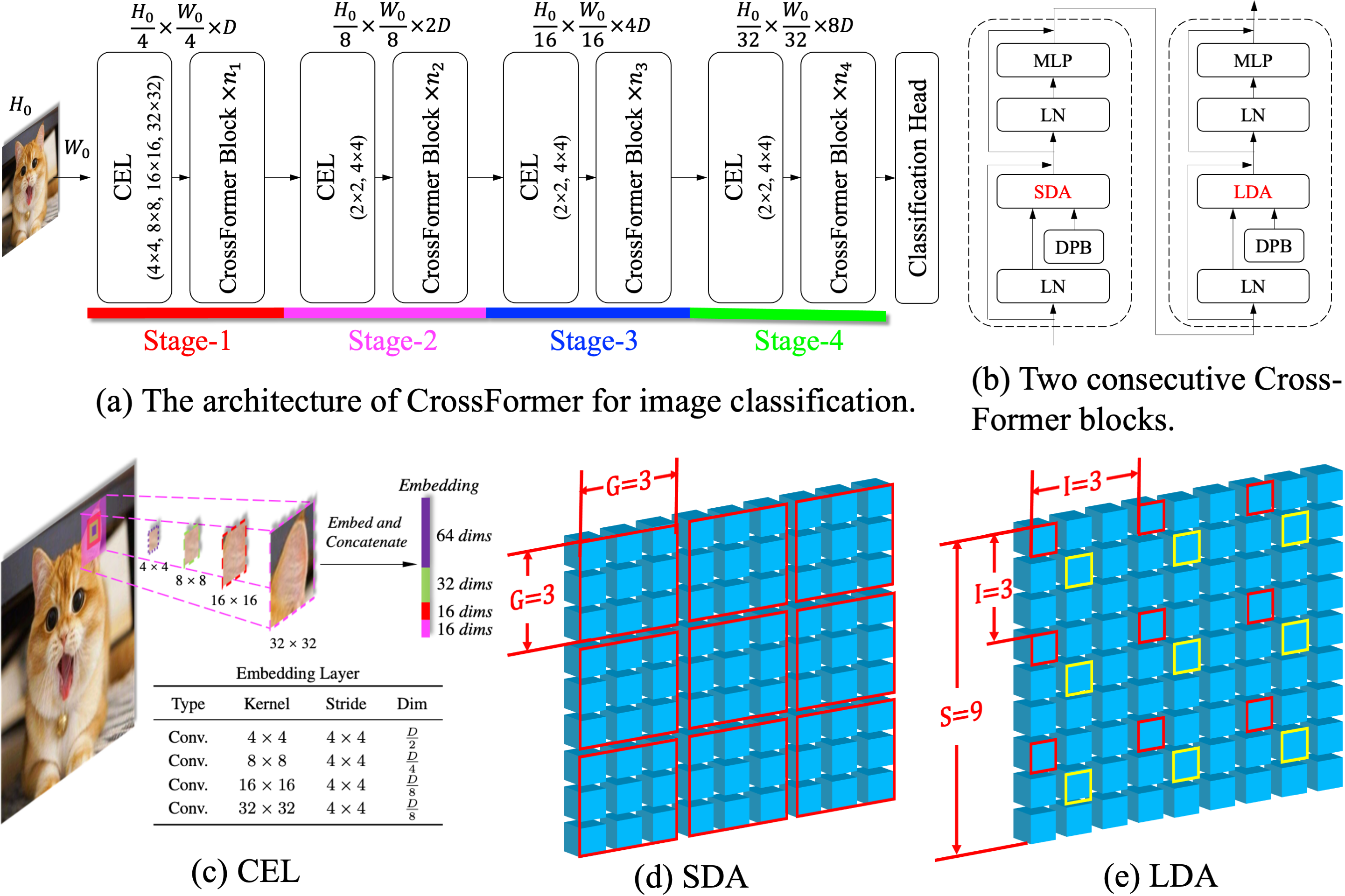
如上图所示,CEL通过对输入特征进行多尺度处理,然后将这些不同尺度的特征与原始输入进行融合,最终得到包含多尺度信息的嵌入表示。
长短距离注意力机制(L/SDA)
长短距离注意力机制是CrossFormer的另一个重要创新。它的核心思想是将所有的嵌入分成若干组,然后只在组内计算自注意力。这种设计有以下几个优点:
- 降低了计算复杂度,使得模型能够处理更大规模的输入。
- 允许模型同时关注局部(短距离)和全局(长距离)的信息。
- 增强了模型的表示能力,使其能够捕捉到更丰富的视觉特征。
动态位置偏置(DPB)
动态位置偏置模块的设计目的是使相对位置偏置能够适用于可变大小的图像输入。这一特性使得CrossFormer在处理不同分辨率的图像时具有更好的灵活性和适应性。
渐进式分组策略(PGS)
渐进式分组策略是CrossFormer++中引入的改进。它通过动态调整注意力计算中的分组大小,在模型性能和计算成本之间取得了更好的平衡。这使得CrossFormer++能够在保持高性能的同时,更好地适应不同的硬件环境和计算资源限制。
激活冷却层(ACL)
激活冷却层是为了解决深层Transformer网络中常见的激活值剧烈增长问题。通过抑制残差流中激活幅度的急剧增长,ACL有助于稳定模型的训练过程,提高模型的泛化能力。
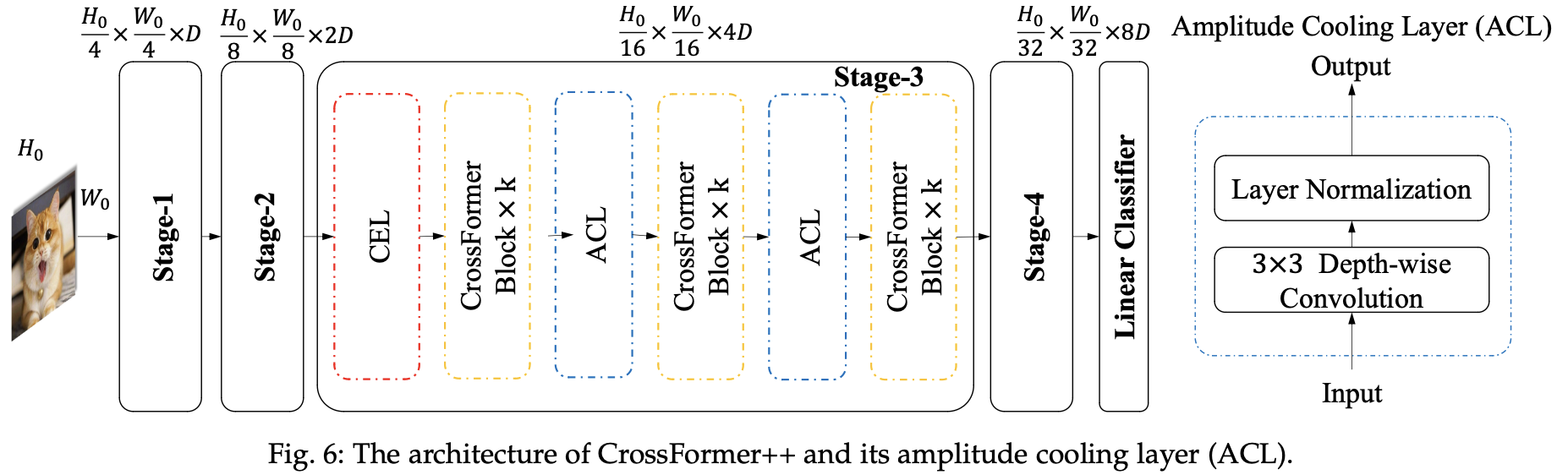
上图展示了CrossFormer++的整体架构,包括了PGS和ACL等改进设计。
CrossFormer的应用与性能
CrossFormer在多个视觉任务上都展现出了优异的性能,包括图像分类、目标检测和语义分割等。以下是CrossFormer在不同任务上的具体表现:
图像分类
在ImageNet-1K数据集上的图像分类任务中,CrossFormer及其改进版CrossFormer++都取得了优秀的结果:
| 模型 | 参数量 | FLOPs | Top-1准确率 |
|---|---|---|---|
| CrossFormer-S | 30.7M | 4.9G | 82.5% |
| CrossFormer++-S | 23.3M | 4.9G | 83.2% |
| CrossFormer-B | 52.0M | 9.2G | 83.4% |
| CrossFormer++-B | 52.0M | 9.5G | 84.2% |
| CrossFormer-L | 92.0M | 16.1G | 84.0% |
| CrossFormer++-L | 92.0M | 16.6G | 84.7% |
可以看到,CrossFormer++在各个模型规模上都取得了明显的性能提升,尤其是在参数量相近的情况下,准确率有了显著提高。
目标检测
在COCO 2017数据集上的目标检测任务中,CrossFormer作为主干网络也展现出了优异的性能:
| 主干网络 | 检测头 | 学习策略 | 参数量 | FLOPs | box AP | mask AP |
|---|---|---|---|---|---|---|
| CrossFormer-S | RetinaNet | 1x | 40.8M | 282.0G | 44.4 | - |
| CrossFormer++-S | RetinaNet | 1x | 40.8M | 282.0G | 45.1 | - |
| CrossFormer-S | Mask R-CNN | 1x | 50.2M | 301.0G | 45.4 | 41.4 |
| CrossFormer++-S | Mask R-CNN | 1x | 43.0M | 287.4G | 46.4 | 42.1 |
CrossFormer++不仅在检测性能上有所提升,而且在某些情况下还减少了参数量和计算量,显示出了更高的效率。
语义分割
在ADE20K数据集上的语义分割任务中,CrossFormer同样表现出色:
| 主干网络 | 分割头 | 迭代次数 | 参数量 | FLOPs | mIoU |
|---|---|---|---|---|---|
| CrossFormer-S | FPN | 80K | 34.3M | 209.8G | 46.4 |
| CrossFormer++-S | FPN | 80K | 27.1M | 199.5G | 47.4 |
| CrossFormer-S | UPerNet | 160K | 62.3M | 979.5G | 47.6 |
| CrossFormer++-S | UPerNet | 160K | 53.1M | 963.5G | 49.4 |
在语义分割任务中,CrossFormer++不仅提高了分割精度,还在大多数情况下减少了模型的参数量和计算量。
CrossFormer的优势与潜在应用
CrossFormer的设计理念和优异性能使其在计算机视觉领域具有广泛的应用前景:
-
通用视觉任务:CrossFormer在图像分类、目标检测和语义分割等多个基础视觉任务上都表现出色,可以作为一个通用的视觉主干网络。
-
多尺度场景理解:得益于其跨尺度注意力机制,CrossFormer特别适合处理需要同时关注局部细节和全局结构的场景,如医疗图像分析、遥感图像解释等。
-
视频分析:CrossFormer的长短距离注意力机制为处理视频序列提供了潜在的优势,可能在视频分类、动作识别等任务中有良好表现。
-
自动驾驶:目标检测和语义分割是自动驾驶中的关键任务,CrossFormer的高性能使其有望应用于自动驾驶的感知系统。
-
移动端AI:CrossFormer++通过渐进式分组策略实现了更好的效率权衡,为将高性能视觉模型部署到资源受限的移动设备提供了可能。
结论
CrossFormer通过创新的跨尺度注意力机制,成功地解决了现有视觉Transformer在处理不同尺度特征时的局限性。其在多个视觉任务上的优异表现,证明了这种设计的有效性和潜力。随着CrossFormer++的进一步改进,我们可以期待这种架构在更广泛的计算机视觉应用中发挥重要作用。
未来,研究人员可能会探索将CrossFormer的核心思想扩展到其他领域,如自然语言处理或多模态学习。同时,进一步优化模型的效率和可解释性也是值得关注的方向。随着技术的不断进步,我们有理由相信,像CrossFormer这样的创新模型将继续推动人工智能和计算机视觉领域的发展,为更多实际应用场景带来新的可能性。









