
dask-sql:Python中的分布式SQL查询引擎
dask-sql是一个强大的分布式SQL查询引擎,它巧妙地结合了Python和SQL的优势,为数据处理和分析提供了灵活而高效的解决方案。这个开源项目为Dask数据框架提供了SQL前端,使用户能够利用Dask的分布式计算能力执行SQL查询,而无需深入了解复杂的数据框架API。
核心特性
dask-sql的核心特性使其成为数据科学家和分析师的理想工具:
-
Python和SQL的完美结合: 用户可以灵活地混合使用Python和SQL来处理数据。可以用Python加载数据,用SQL转换数据,再用Python增强数据,最后用SQL查询数据 - 或者反过来。这种方法充分利用了pandas和Dask的Python数据框架API以及常见的SQL操作,让用户能够以最便捷的方式处理数据。
-
无限扩展能力: 借助Dask生态系统的强大功能,计算可以根据需求轻松扩展 - 从笔记本电脑到超级计算机集群,无需更改任何SQL代码。无论是K8s还是云部署,批处理系统还是YARN,只要Dask支持,dask-sql就能支持。
-
自定义查询的灵活性: 用户可以在SQL中使用Python自定义函数(UDF),而不会影响性能。这使得SQL查询可以扩展到大量Python库,包括机器学习、复杂的输入格式处理和高级统计分析等。
-
简单的安装和维护: dask-sql可以通过pip或conda轻松安装,也可以通过Docker运行,使其易于部署和维护。
-
多样化的使用方式: dask-sql可以与Jupyter笔记本、常规Python模块集成,也可以作为独立的SQL服务器供任何BI工具使用。它甚至与Apache Hue原生集成。
-
GPU支持: dask-sql支持在CUDA-enabled GPU上运行SQL查询,利用RAPIDS库(如cuDF)实现SQL的加速计算。
工作原理
dask-sql的工作原理主要包括两个步骤:
- 使用Apache Arrow DataFusion将SQL查询转换为关系代数,表示为逻辑查询计划。
- 将这个查询描述转换为Dask API调用并执行,返回一个Dask数据框。
在第一步中,DataFusion需要了解Dask数据框的列和类型信息。为此,dask-sql在dask_planner中定义了一些Rust代码来存储这些信息。完成关系代数转换后(使用DaskSQLContext.logical_relational_algebra),dask_sql.physical中定义的Python方法将其转换为物理Dask执行计划,逐一转换关系代数的每个部分。
实际应用示例
让我们通过一个简单的例子来看看dask-sql是如何工作的:
import dask.dataframe as dd
from dask_sql import Context
# 创建一个上下文来保存注册的表
c = Context()
# 加载数据并在上下文中注册
# 这将给表一个名称,我们可以在查询中使用
df = dd.read_csv("large_dataset.csv")
c.create_table("my_data", df)
# 执行SQL查询。结果仍然是一个Dask数据框
result = c.sql("""
SELECT
my_data.name,
SUM(my_data.value)
FROM
my_data
GROUP BY
my_data.name
""", return_futures=False)
# 显示结果
print(result)
在这个例子中,我们首先创建了一个Context对象,然后使用Dask读取了一个大型CSV文件。我们将这个数据框注册到上下文中,给它一个名称"my_data"。然后,我们执行了一个SQL查询,对数据进行分组和聚合。最后,我们打印出结果。
这个简单的例子展示了dask-sql如何无缝地将SQL查询与Dask的分布式计算能力结合起来。即使处理大型数据集,这个查询也能高效地执行。
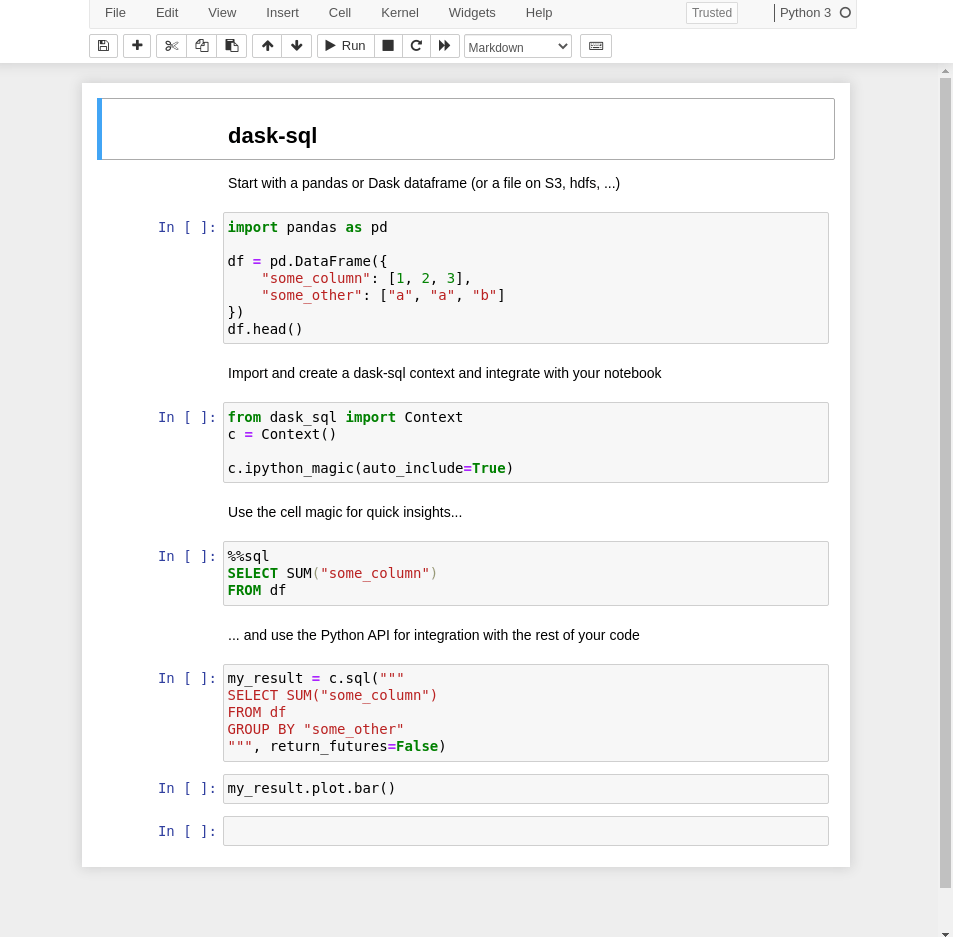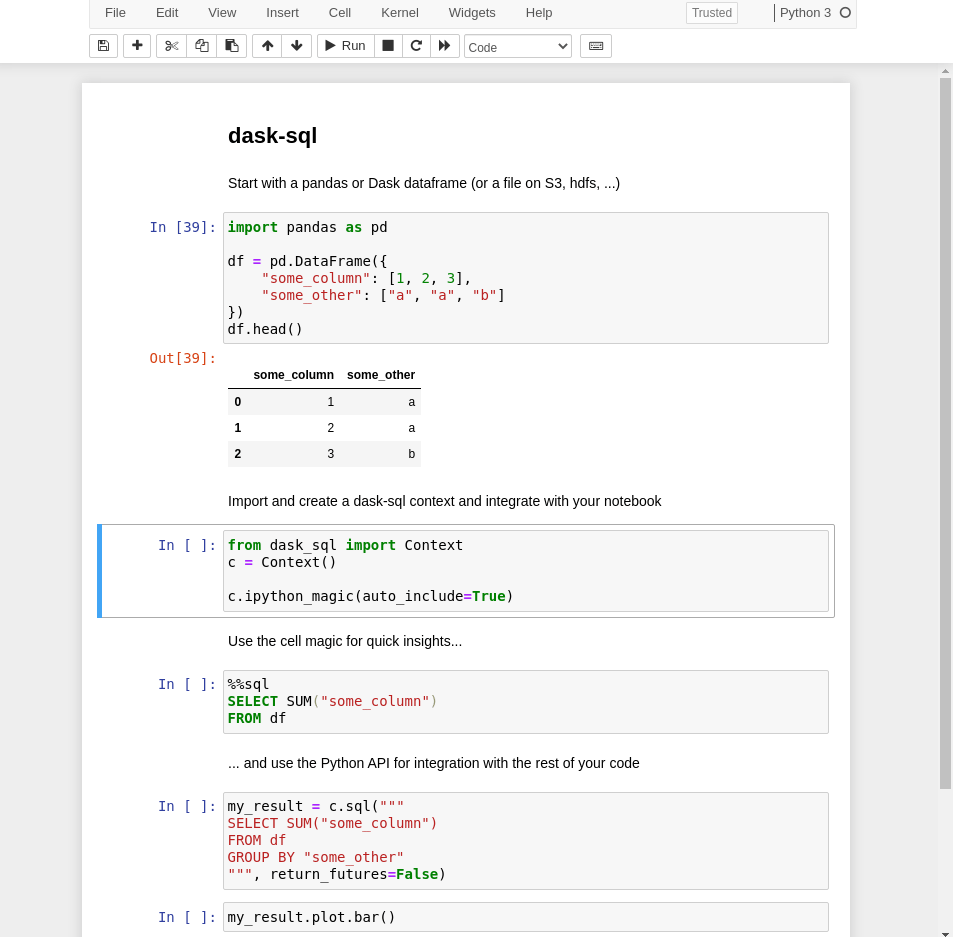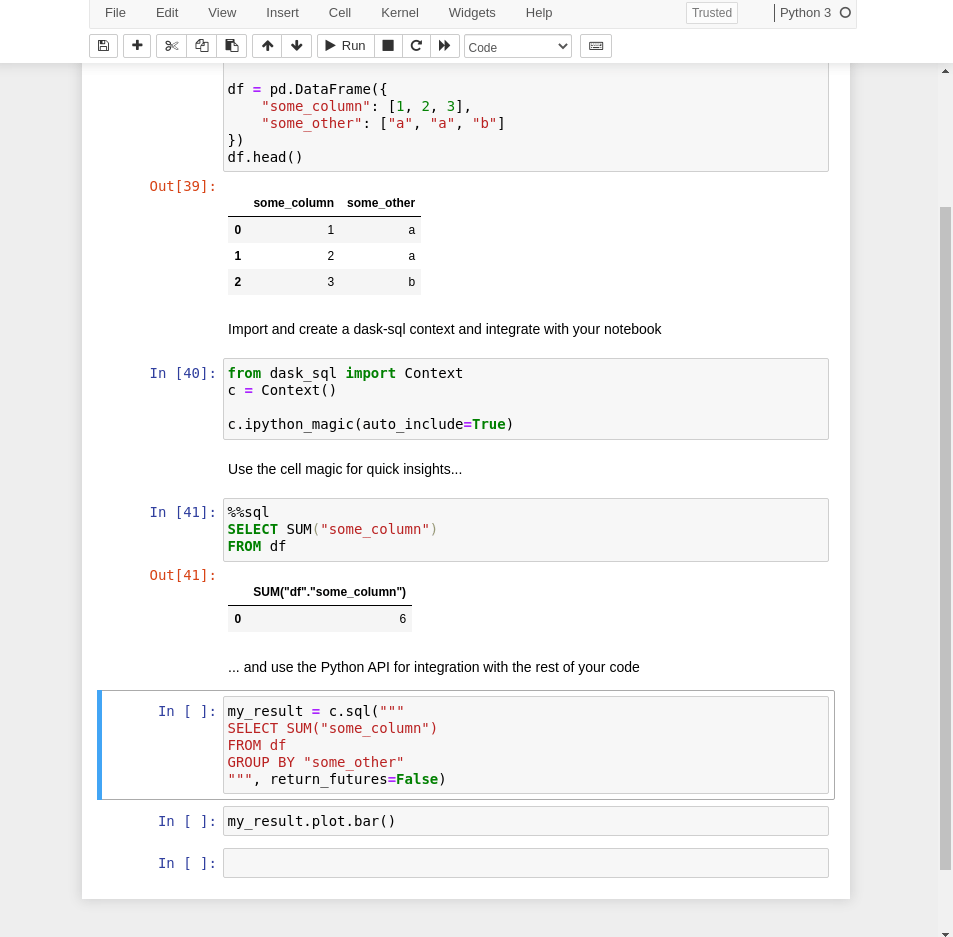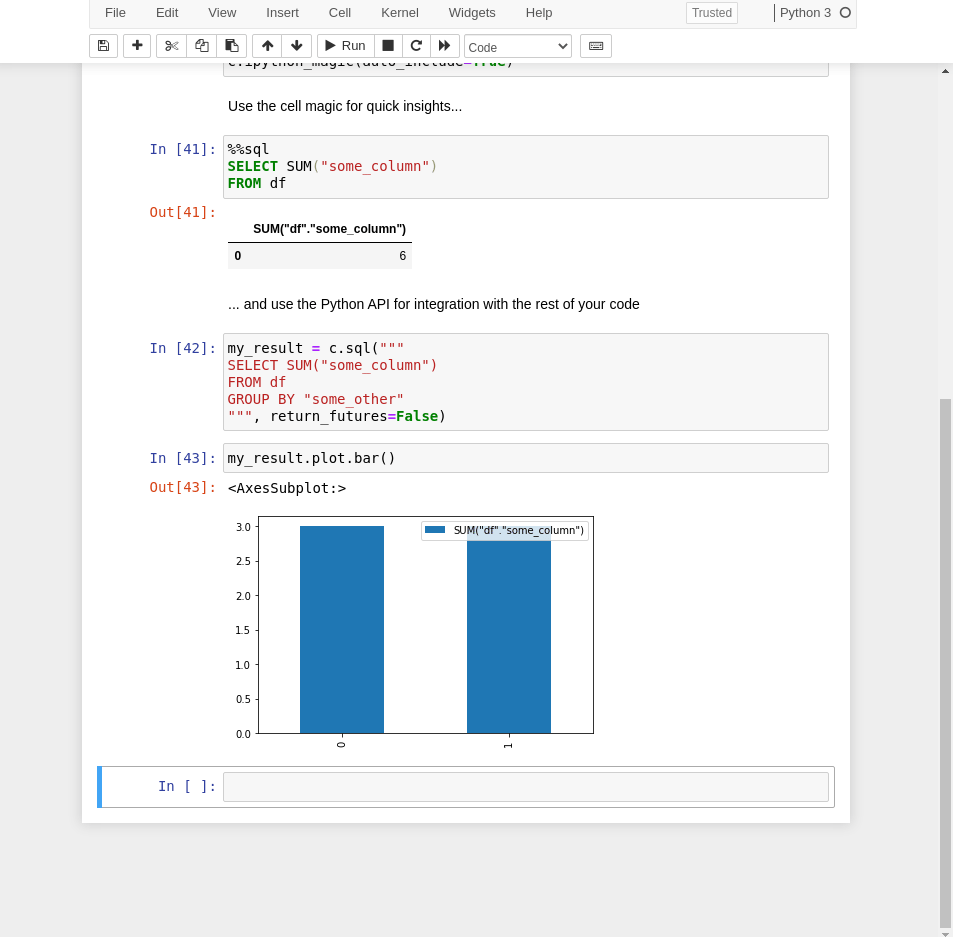
安装和使用
dask-sql的安装非常简单,可以通过conda(推荐)或pip安装:
使用conda:
conda install dask-sql -c conda-forge
使用pip:
pip install dask-sql
安装完成后,你就可以像上面的例子那样使用dask-sql了。
SQL服务器功能
除了在Python代码中使用,dask-sql还提供了一个SQL服务器功能。这个服务器使用Presto wire协议,允许任何Presto客户端连接并执行查询。要启动服务器,可以运行:
dask-sql-server
或者使用Docker镜像:
docker run --rm -it -p 8080:8080 nbraun/dask-sql
这将在端口8080上启动一个服务器,你可以使用Presto客户端连接并执行SQL查询。
命令行界面
dask-sql还提供了一个命令行界面,方便快速测试SQL命令:
dask-sql --load-test-data --startup
(dask-sql) > SELECT * FROM timeseries LIMIT 10;
这个CLI工具让用户能够快速验证查询和探索数据,而无需编写完整的Python脚本。
社区和开发
dask-sql是一个活跃的开源项目,欢迎社区贡献。虽然目前它还不能理解所有的SQL命令,但开发团队正在积极寻求反馈、改进和贡献者。如果你对SQL和分布式计算感兴趣,参与dask-sql的开发将是一个很好的机会。
结论
dask-sql为数据科学家和分析师提供了一个强大的工具,将SQL的简单性和Python的灵活性与Dask的分布式计算能力相结合。无论是处理小型数据集还是大规模分布式计算,dask-sql都能提供一致的接口和出色的性能。随着项目的不断发展,我们可以期待看到更多强大的特性和更广泛的应用场景。
如果你正在寻找一种方法来简化你的数据处理流程,同时保持扩展性和灵活性,dask-sql绝对值得一试。它不仅能提高你的生产力,还能为你的数据分析工作流程带来新的可能性。










