
大型语言模型的数据管理:提升AI性能的关键
近年来,大型语言模型(Large Language Models, LLMs)在自然语言处理领域取得了突破性进展,展现出惊人的能力。然而,这些模型的性能在很大程度上依赖于它们所训练的数据。本文将深入探讨LLM数据管理的重要性,以及如何通过优化数据策略来提升模型性能。
预训练阶段的数据管理
预训练是LLM开发的第一个关键阶段,这个阶段的数据管理主要涉及以下几个方面:
1. 数据域组成
数据域的多样性对LLM的通用性至关重要。研究表明,平衡不同领域的数据可以显著提高模型的泛化能力。例如,DoReMi项目提出了一种优化数据混合的方法,通过调整不同数据源的比例来提高预训练效果。
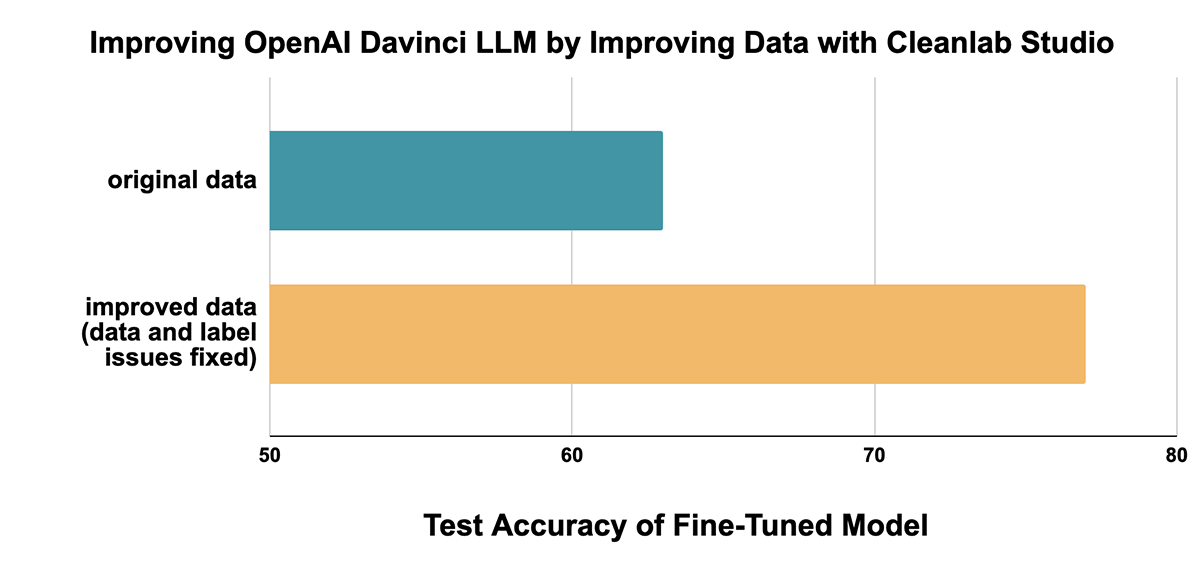
2. 数据数量
"数据越多越好"这一说法并不总是正确的。研究人员发现,数据量与模型性能之间存在一定的规律,即所谓的"缩放法则"。此外,数据重复也是一个需要关注的问题,过多的重复可能会导致模型过拟合或学习效率低下。
3. 数据质量
高质量的数据对于训练出优秀的LLM至关重要。数据质量管理主要包括以下几个方面:
- 质量过滤: 去除低质量、无意义或有害的数据。
- 去重: 避免数据集中存在大量重复内容。
- 毒性过滤: 移除可能导致模型产生有害或偏见输出的数据。
- 多样性与时效性: 确保数据的多样性和时效性,以提高模型的适应能力。
监督微调阶段的数据管理
监督微调是LLM开发的第二个关键阶段,这个阶段的数据管理主要关注以下几个方面:
1. 任务组成
合理的任务组成可以显著提高模型的多任务能力。例如,FLAN(Finetuned Language Models Are Zero-Shot Learners)项目通过在大量不同任务上进行微调,成功提高了模型的零样本学习能力。
2. 指令质量
高质量的指令对于提升模型的指令跟随能力至关重要。研究人员提出了多种方法来优化指令质量,如自我指导、人机协作等。例如,Self-Instruct项目提出了一种利用LLM自身能力来生成高质量指令的方法。

3. 指令多样性
指令的多样性对于提高模型的泛化能力非常重要。研究表明,增加指令的多样性可以帮助模型更好地理解和执行各种任务。一些项目,如Stanford Alpaca,通过生成大量多样化的指令来提升模型性能。
4. 指令复杂度
随着研究的深入,研究者们发现增加指令的复杂度可以进一步提升模型的能力。例如,WizardLM项目通过生成和使用更复杂的指令,成功提高了模型处理复杂任务的能力。
动态数据高效学习
除了静态的数据管理策略,研究者们还探索了动态的数据高效学习方法:
-
训练影响数据: 一些方法根据模型的训练进展动态调整数据集,如引入提前停止标准或主动学习策略。
-
数据影响训练: 另一些方法则根据数据特性动态调整训练过程,如课程学习或动态数据增长策略。
结论与展望
数据管理在LLM的开发过程中扮演着至关重要的角色。通过优化数据域组成、数量、质量,以及采用动态学习策略,我们可以显著提升LLM的性能。未来,随着更多创新方法的出现,数据管理将继续成为推动LLM发展的关键因素。
作为AI领域的从业者或研究者,我们应该持续关注数据管理的最新进展,并将这些技术应用到实际的LLM开发中。同时,我们也需要注意数据隐私和伦理问题,确保LLM的发展能够造福人类社会。
让我们携手共进,通过不断优化数据管理策略,推动大型语言模型技术向更高水平迈进!


















