
DDSP-SVC:让AI歌声转换触手可及
在人工智能技术飞速发展的今天,歌声转换作为一个热门的研究方向,吸引了众多开发者和研究人员的关注。而DDSP-SVC项目的出现,无疑为这一领域注入了新的活力。本文将深入介绍DDSP-SVC项目,探讨其核心技术、优势特点以及应用前景。
什么是DDSP-SVC?
DDSP-SVC是一个基于差分数字信号处理(Differentiable Digital Signal Processing, DDSP)的实时端到端歌声转换系统。该项目由GitHub用户yxlllc开发并开源,旨在开发可在个人电脑上普及的免费AI变声软件。
DDSP-SVC的核心思想是利用差分数字信号处理技术,将复杂的歌声转换任务分解为一系列可微分的信号处理模块。这种方法不仅大大降低了计算复杂度,还提高了模型的可解释性和可控性。
DDSP-SVC的主要特点
-
低硬件要求:相比其他知名的歌声转换项目如SO-VITS-SVC,DDSP-SVC对计算机硬件的要求更低。这意味着即使是普通的个人电脑也能运行DDSP-SVC模型。
-
快速训练:DDSP-SVC的训练速度非常快,可以将训练时间缩短数个数量级。这大大提高了模型的迭代效率,使得研究人员和开发者可以更快地进行实验和改进。
-
实时转换:DDSP-SVC支持实时的歌声转换,这为live演出和实时互动应用提供了可能。
-
高质量合成:尽管DDSP-SVC的原始合成质量可能不是最理想的,但通过使用预训练的声码器增强器或浅层扩散模型,它可以达到不亚于其他项目的合成质量。
-
多说话人支持:DDSP-SVC支持多说话人模型的训练,这使得一个模型可以同时支持多个声音的转换。
DDSP-SVC的技术架构
DDSP-SVC的技术架构主要包含以下几个部分:
-
特征编码器:用于提取输入音频的特征表示。DDSP-SVC支持使用ContentVec或HubertSoft作为特征编码器。
-
DDSP模型:核心的歌声转换模型,负责将输入特征转换为目标说话人的声音参数。
-
声码器/增强器:用于提高合成音频的质量。DDSP-SVC使用NSF-HiFiGAN作为默认的声码器。
-
音高提取器:用于提取输入音频的音高信息。DDSP-SVC使用RMVPE作为音高提取器。
-
浅层扩散模型:可选的组件,用于进一步提高合成音质。
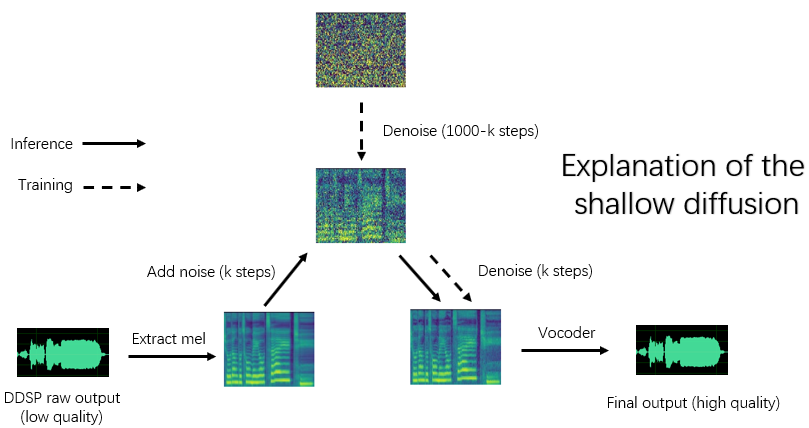
DDSP-SVC的使用流程
使用DDSP-SVC进行歌声转换通常包括以下步骤:
-
环境配置:安装必要的依赖,包括PyTorch、torchaudio等。
-
数据准备:收集训练数据,并将其放置在指定的目录结构中。
-
预处理:运行预处理脚本,提取音频特征和音高信息。
-
模型训练:使用预处理后的数据训练DDSP-SVC模型。
-
推理/转换:使用训练好的模型进行歌声转换,可以选择实时转换或非实时转换。
DDSP-SVC的应用前景
DDSP-SVC作为一个强大而灵活的歌声转换工具,有着广泛的应用前景:
-
音乐创作:musicians可以使用DDSP-SVC创造新的声音效果或模仿其他歌手的声音。
-
虚拟主播/虚拟歌手:DDSP-SVC可以为虚拟主播或虚拟歌手提供多样化的声音。
-
语音助手个性化:可以用于定制个性化的语音助手声音。
-
语音修复:帮助修复有声音问题的录音。
-
教育培训:用于语音训练和发音矫正。
DDSP-SVC的未来发展
尽管DDSP-SVC已经展现出了强大的性能,但它仍在不断发展和改进中。未来的发展方向可能包括:
-
进一步提高合成质量:通过改进模型结构和训练方法,提高原始输出的质量。
-
降低资源消耗:优化算法,使其能在更低端的硬件上运行。
-
增强多语言支持:改进模型以better处理不同语言间的转换。
-
情感控制:增加对生成声音情感的精细控制。
-
与其他AI技术的结合:例如与大语言模型结合,实现更智能的声音生成。
结语
DDSP-SVC作为一个开源的歌声转换项目,不仅为研究人员提供了一个优秀的实验平台,也为普通用户带来了易于使用的AI变声工具。它的低硬件要求、快速训练和高质量合成等特点,使得AI歌声转换技术更加普及和亲民。
随着项目的不断发展和社区的持续贡献,我们有理由相信DDSP-SVC将在未来发挥更大的作用,为音乐创作、娱乐产业和人机交互等领域带来更多创新和可能性。无论你是研究人员、开发者还是普通用户,都可以尝试使用DDSP-SVC,探索AI歌声转换的奇妙世界。
🔗 相关链接:
💡 注意事项: 使用DDSP-SVC时,请确保只使用合法获得授权的数据进行训练,并遵守相关法律法规。不要将生成的音频用于非法或不道德的目的。
DDSP-SVC的出现,为AI歌声转换领域带来了新的可能。它不仅降低了技术门槛,也为音乐创作和声音处理提供了更多灵感。让我们期待DDSP-SVC在未来能够创造出更多令人惊叹的声音奇迹!









