
DenseCL:突破自监督视觉预训练的新范式
在计算机视觉领域,自监督学习已成为一种极具前景的研究方向。它能够利用大量未标注的数据来学习通用的视觉表示,为下游任务提供强大的预训练模型。然而,传统的自监督方法大多针对图像分类任务进行优化,对于目标检测、语义分割等密集预测任务的效果往往不尽如人意。为了解决这一问题,来自澳大利亚阿德莱德大学的研究团队提出了一种新颖的密集对比学习方法——DenseCL(Dense Contrastive Learning),旨在更好地适应密集预测任务的需求。
DenseCL的核心思想
DenseCL的核心思想是在像素级别进行对比学习,而不是传统方法中的图像级别。具体来说,它通过以下步骤实现:
- 对输入图像进行两次数据增强,得到两个视图。
- 将两个视图分别输入到编码器网络中,提取特征图。
- 在特征图的每个空间位置上计算对比损失,使得对应位置的特征更相似,而不同位置的特征更不相似。
- 通过优化这个密集的对比损失来训练网络,学习到更适合密集预测任务的特征表示。
这种方法的优势在于,它能够捕捉到图像的局部结构信息,而不仅仅是全局语义信息。这对于需要精确定位目标或分割区域的任务来说尤为重要。
DenseCL的技术细节
DenseCL的实现非常简洁高效。研究人员基于MoCo-v2框架进行了改进,主要修改了以下几个方面:
-
特征提取:使用ResNet-50作为骨干网络,但移除了最后的全局平均池化层,保留了空间维度信息。
-
投影头:采用1x1卷积层作为投影头,将特征图映射到低维空间。
-
对比损失:在特征图的每个空间位置上计算InfoNCE损失,而不是整张图像的全局表示。
-
正负样本选择:正样本为两个视图中对应位置的特征,负样本为其他所有位置的特征。
-
动量更新:采用动量编码器来维护特征队列,提高训练稳定性。
这些设计使得DenseCL能够在引入极少计算开销的情况下(仅比MoCo-v2慢1%),实现显著的性能提升。

DenseCL的优异表现
DenseCL在多个下游任务上展现出了卓越的性能:
-
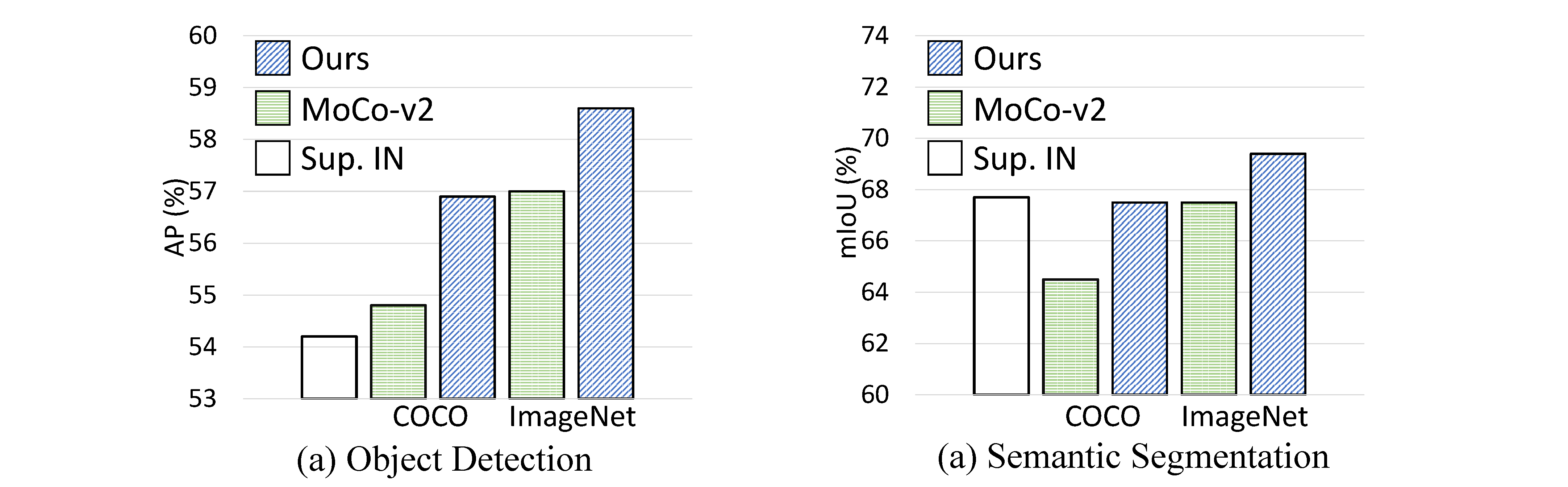
目标检测:在PASCAL VOC数据集上,DenseCL比MoCo-v2提高了2.0% AP;在COCO数据集上提高了1.1% AP。
-
实例分割:在COCO数据集上,DenseCL比MoCo-v2提高了0.9% AP。
-
语义分割:在PASCAL VOC数据集上,DenseCL比MoCo-v2提高了3.0% mIoU;在Cityscapes数据集上提高了1.8% mIoU。
这些结果充分证明了DenseCL在密集预测任务上的优势。特别是在语义分割任务上,DenseCL的改进幅度最为显著,这与其设计初衷高度一致。
DenseCL的灵活性和易用性
除了性能优异外,DenseCL还具有以下特点:
-
实现简单:核心代码仅需10行左右,易于理解和修改。
-
灵活性强:与数据预处理解耦,可以灵活使用各种数据增强方法。
-
训练高效:相比基线方法,几乎不增加额外的计算开销。
-
通用性好:预训练模型可以直接替换ImageNet预训练模型,用于各种密集预测任务。
这些特性使得DenseCL非常适合研究人员进行进一步的探索和改进。
DenseCL的应用前景
DenseCL的成功为自监督学习在密集预测任务中的应用开辟了新的方向。它不仅可以应用于目标检测和语义分割,还可以扩展到其他需要精细空间信息的任务,如实例分割、姿态估计等。
在实际应用中,DenseCL预训练的模型可以作为各种计算机视觉任务的强大初始化。例如:
- 自动驾驶:提高对道路场景的精确理解能力。
- 医疗影像分析:增强对病变区域的定位和分割精度。
- 遥感图像处理:改善对地表特征的识别和分类效果。
- 工业质检:提升对产品缺陷的检测能力。
这些应用都能从DenseCL更精细的特征表示中受益,有望带来性能的进一步提升。
未来研究方向
尽管DenseCL已经取得了显著的成果,但在自监督学习领域仍有许多值得探索的方向:
- 多尺度特征融合:如何更好地利用不同层级的特征信息。
- 跨模态学习:将DenseCL扩展到图像-文本等多模态数据上。
- 大规模预训练:探索在更大规模数据集上训练DenseCL的效果。
- 架构设计:研究更适合密集预测任务的骨干网络结构。
- 理论分析:深入理解DenseCL成功的原因和机制。
这些方向都有望进一步推动自监督学习在计算机视觉领域的发展。
结语
DenseCL作为一种创新的自监督视觉预训练方法,成功地将对比学习的思想扩展到了密集预测任务中。它不仅在性能上取得了显著提升,还保持了实现简单、使用灵活的优点。随着研究的深入和应用的拓展,DenseCL有望为计算机视觉领域带来更多突破性的进展,推动自监督学习技术向更高水平迈进。
📚 参考资料:


















