
大型音频模型的发展与应用:综述与展望
近年来,大型语言模型(Large Language Models, LLMs)在自然语言处理领域取得了突破性进展。随着研究人员将这一技术应用到音频信号处理中,大型音频模型(Large Audio Models, LAMs)也逐渐成为学术界和产业界关注的焦点。本文将全面介绍大型音频模型的发展历程、关键技术、主要应用场景以及未来研究方向,为读者提供这一快速发展领域的全面认识。
大型音频模型的发展历程
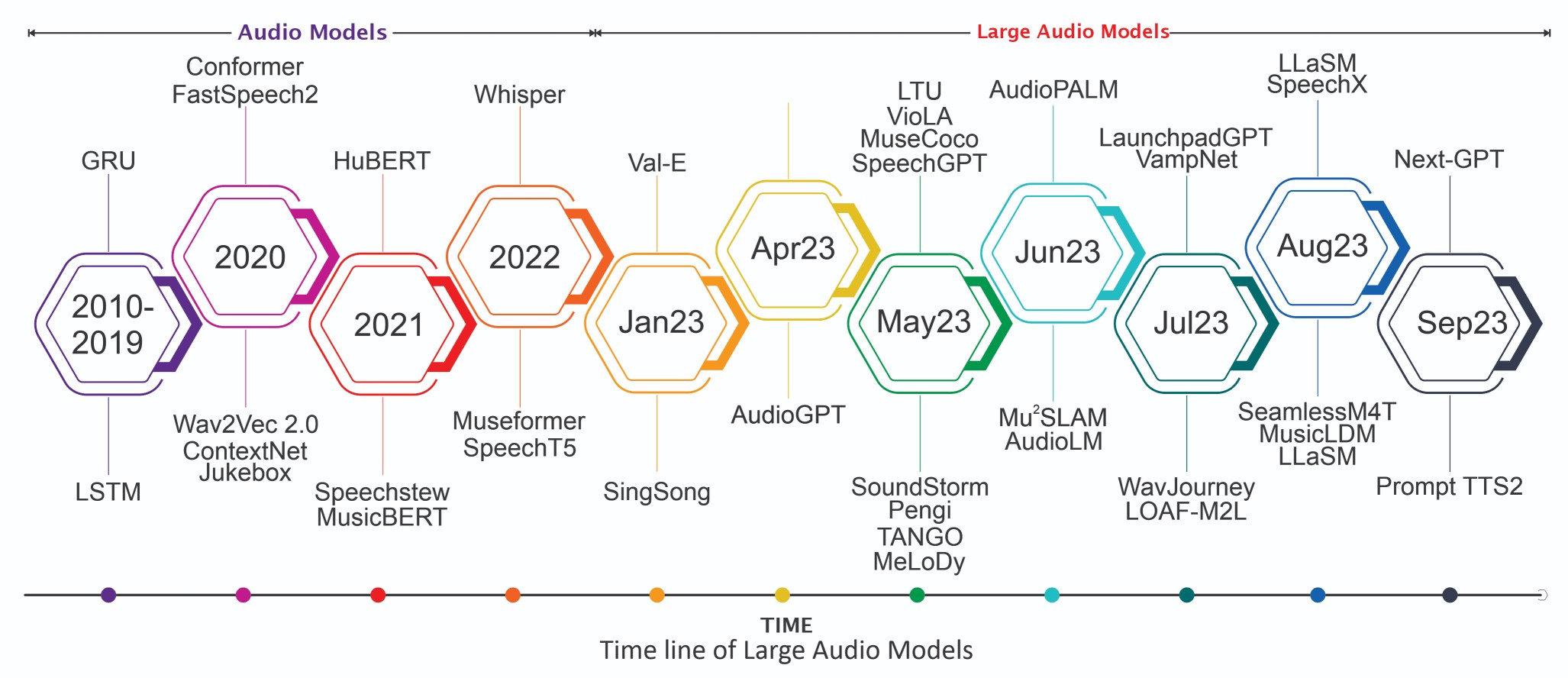
大型音频模型的出现可以追溯到Transformer架构在自然语言处理领域的成功应用。2017年,Google提出的Transformer模型凭借其出色的并行计算能力和长距离依赖建模能力,在机器翻译等任务上取得了突破性进展。此后,研究人员开始探索将Transformer应用于音频信号处理,这为大型音频模型的诞生奠定了基础。
2020年,OpenAI发布的GPT-3模型展示了大规模语言模型的强大能力,引发了学术界和产业界对大模型的广泛关注。受此启发,研究人员开始尝试构建面向音频任务的大规模模型。2022年,Google推出的AudioLM模型被认为是大型音频模型发展的一个里程碑。AudioLM采用语言建模的方法来生成音频,展示了大型模型在音频生成任务上的巨大潜力。
2023年,Meta发布的SeamlessM4T模型进一步推动了大型音频模型的发展。该模型支持100种语言的多种语音任务,展示了大型音频模型作为"通用翻译器"的能力。同年,字节跳动推出的SALMONN模型则为大语言模型赋予了"听觉"能力,使其能够直接处理语音输入。
大型音频模型的关键技术
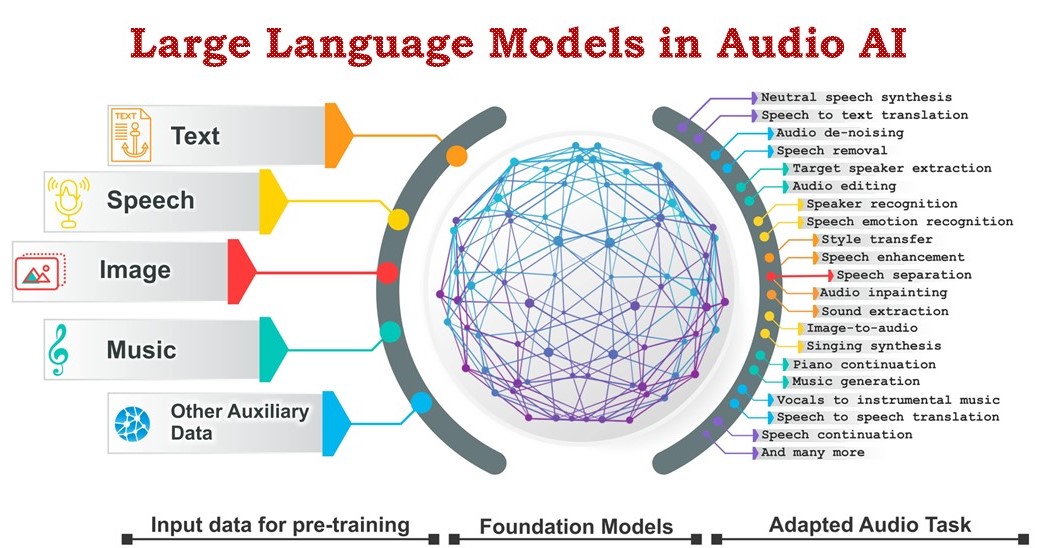
大型音频模型的核心思想是将语言模型的方法应用于音频信号处理。然而,音频信号的高维度特性和语音的一对多关系给模型设计带来了新的挑战。为此,研究人员提出了一系列创新性的技术方案:
-
多级标记化: 为了有效处理音频信号,许多大型音频模型采用了多级标记化策略。例如,AudioLM模型使用语义标记(semantic tokens)来捕捉音频的高层结构,同时使用声学标记(acoustic tokens)来保留音频的细节信息。这种方法既能保证生成音频的长期一致性,又能确保生成结果的高保真度。
-
自监督学习: 大型音频模型通常采用自监督学习的方法进行预训练。例如,w2v-BERT模型使用掩码预测任务来学习音频的表示,这使得模型能够从大量未标注的音频数据中学习有用的特征。
-
层次化建模: 为了处理音频信号的多尺度特性,一些模型采用了层次化的建模方法。例如,AudioLM模型使用多个Transformer模型来逐级建模音频序列,从语义标记到细粒度的声学标记。
-
跨模态学习: 一些大型音频模型引入了跨模态学习的思想,将音频、文本甚至视频等多种模态的信息结合起来。例如,SpeechGPT模型通过结合语音和文本信息,实现了更自然的语音交互能力。
大型音频模型的主要应用场景
大型音频模型在多个音频处理任务中展现出了强大的能力,主要应用场景包括:
-
自动语音识别(ASR): 大型音频模型在ASR任务中取得了显著进展。例如,Google的研究表明,将大型语言模型与语音编码器相结合可以显著提高ASR的性能,特别是在处理长文本时。
-
语音合成(TTS): 大型音频模型为TTS任务带来了新的可能性。Neural Codec Language Models等模型展示了零样本文本到语音合成的能力,即无需针对特定说话人进行微调就能生成高质量的语音。
-
语音翻译: 大型音频模型在端到端语音翻译任务中表现出色。例如,Meta的SeamlessM4T模型支持100种语言之间的语音翻译,而无需依赖单独的ASR或TTS系统。
-
音乐生成: 在音乐领域,大型音频模型展示了令人印象深刻的生成能力。例如,Google的MusicLM模型可以根据文本描述生成高质量的音乐片段。
-
多模态交互: 一些大型音频模型支持音频、文本等多种模态的输入和输出,为更自然的人机交互奠定了基础。例如,SpeechGPT模型可以进行语音对话,同时保持对话的连贯性和语义一致性。
大型音频模型面临的挑战与未来方向
尽管大型音频模型取得了显著进展,但仍面临一些挑战:
-
计算资源需求: 训练和部署大型音频模型需要大量的计算资源,这限制了其广泛应用。未来需要探索更高效的模型架构和训练方法。
-
数据隐私: 音频数据往往包含敏感信息,如何在保护隐私的同时利用大规模数据训练模型是一个重要问题。
-
生成内容的控制: 如何精确控制生成音频的各个方面(如情感、风格、音色等)仍是一个挑战。
-
多语言和多方言支持: 虽然一些模型已经支持多种语言,但对低资源语言和方言的支持仍有待提高。
-
伦理和安全问题: 大型音频模型可能被滥用于生成虚假音频内容,如何防范这种风险是一个重要的研究方向。
未来,大型音频模型的研究可能会朝以下方向发展:
-
模型效率优化: 探索更高效的模型架构和训练方法,降低计算资源需求。
-
多模态融合: 加强音频、文本、图像等多种模态之间的融合,实现更自然的人机交互。
-
个性化和适应性: 研究如何快速适应特定用户或场景的需求,提高模型的实用性。
-
可解释性和可控性: 提高模型决策的可解释性,并增强对生成内容的精确控制能力。
-
负责任的AI: 研究如何在发挥大型音频模型潜力的同时,确保其安全、公平和符合伦理。
结论
大型音频模型代表了音频信号处理领域的一个重要发展方向。通过将大规模语言模型的思想应用于音频领域,研究人员开发出了能够处理各种复杂音频任务的强大模型。尽管仍面临一些挑战,但大型音频模型已经展示了其在语音识别、语音合成、音乐生成等领域的巨大潜力。未来,随着技术的不断进步和新应用场景的开发,大型音频模型有望为人机交互、创意产业等领域带来革命性的变革。
作为一个快速发展的研究领域,大型音频模型还有很多待探索的方向。研究人员需要继续努力,解决现有的技术挑战,同时也要关注模型应用中可能出现的伦理和社会问题。只有这样,才能确保大型音频模型的发展既推动技术进步,又能为人类社会带来真正的价值。









