
Diffusion Autoencoders简介
Diffusion Autoencoders(简称DiffAE)是由Konpat Preechakul等人在2022年CVPR会议上提出的一种新型图像生成模型。它巧妙地结合了扩散概率模型(Diffusion Probabilistic Models, DPMs)和自编码器(Autoencoder)的优点,旨在学习一种语义丰富且易于解码的图像表示。
近年来,扩散概率模型在图像生成领域取得了巨大成功,其生成质量已经可以与GAN相媲美。然而,DPM使用的潜在变量往往缺乏语义意义,难以直接用于下游任务。而DiffAE的核心思想就是利用可学习的编码器来捕获高级语义信息,同时使用DPM作为解码器来建模剩余的随机变化。
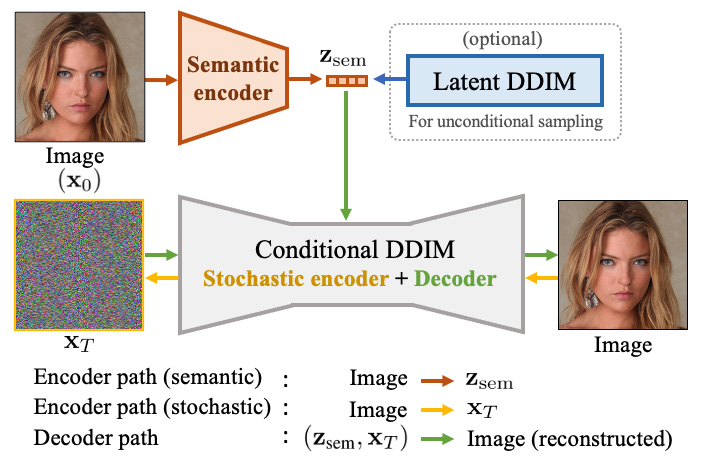
如上图所示,DiffAE由两个主要部分组成:
- 语义编码器:将输入图像x0映射到语义子码zsem
- 条件DDIM:同时作为"随机"编码器(x0 → xT)和解码器((zsem, xT) → x0)
其中,zsem捕获高级语义信息,而xT捕获低级随机变化。这两部分共同组成了可以几乎完美重建原始图像的潜在编码。
DiffAE的主要特点
与传统的扩散模型和GAN相比,DiffAE具有以下几个显著特点:
1. 语义丰富的潜在表示
DiffAE学习到的潜在表示分为两部分:语义子码zsem和随机子码xT。其中zsem具有丰富的语义信息,支持各种下游任务,如属性编辑、插值等。而xT则保留了图像的随机细节信息。这种两级编码使得DiffAE能够在保持图像细节的同时进行语义级操作。
2. 高质量重建与生成
得益于扩散模型强大的生成能力,DiffAE不仅可以高质量地重建输入图像,还能生成新的图像样本。通过在zsem的分布上拟合另一个扩散模型,DiffAE可以实现无条件采样,生成质量与原始扩散模型相当。
3. 灵活的图像编辑能力
DiffAE学习到的潜在空间具有良好的线性特性,支持简单的向量运算来实现语义编辑。例如,可以通过在潜在空间中添加表示某个属性变化的向量,来改变图像的特定属性。这种编辑方式非常直观且灵活。
4. 对真实图像的操作
与GAN不同,DiffAE无需复杂的GAN反演过程就可以直接编辑真实图像。只需将真实图像编码到潜在空间,进行所需的编辑操作,然后解码回图像空间即可。这大大简化了对真实图像的操作流程。
DiffAE的应用示例
DiffAE在图像生成和编辑领域展现出了强大的能力,以下是一些典型应用:
1. 属性编辑
DiffAE可以轻松实现对图像属性的精确编辑,如改变发型、添加眼镜等。

如上图所示,DiffAE可以在保持原始图像细节的同时,自然地改变各种面部属性。值得注意的是,这些编辑效果非常逼真,例如添加眼镜时会自然地产生阴影效果,移除眼镜则会消除镜片的折射效果。
2. 图像插值
DiffAE支持在潜在空间中对两张图像进行平滑插值,生成自然过渡的图像序列。
具体操作步骤如下:
- 将两张源图像编码到潜在空间
- 在潜在空间中对两个编码进行加权求和
- 将插值结果解码回图像空间
这种方法可以生成非常平滑自然的过渡效果,两端点与输入图像几乎完全一致。
3. 无条件采样
通过在DiffAE的潜在分布上拟合另一个扩散模型,可以实现高质量的无条件图像生成。实验表明,这种方法生成的图像质量(以FID分数衡量)可以与原始扩散模型相媲美。
4. 少样本条件生成
DiffAE学习到的语义丰富的潜在表示,为少样本条件生成提供了便利。只需在潜在空间中拟合一个简单的条件生成模型,就可以实现高质量的条件图像生成,而无需在像素空间中训练复杂的条件模型。
DiffAE的实现与使用
DiffAE的官方实现代码已在GitHub上开源,感兴趣的读者可以访问https://github.com/phizaz/diffae获取详细信息。该仓库提供了完整的训练和推理代码,以及预训练模型。
使用DiffAE非常简单,以下是几个快速上手的步骤:
- 安装依赖:
pip install -r requirements.txt
-
下载预训练模型,并放置在
checkpoints目录下 -
使用Jupyter notebook进行交互式操作:
sample.ipynb: 无条件生成manipulate.ipynb: 属性编辑interpolate.ipynb: 图像插值autoencoding.ipynb: 自编码重建
-
对自己的图像进行对齐(可选):
- 将图像放入
imgs目录 - 运行
align.py - 对齐后的图像会保存在
imgs_align目录
- 将图像放入
总结与展望
Diffusion Autoencoders成功地将扩散概率模型的强大生成能力与自编码器的可解释表示相结合,为图像生成和编辑领域带来了新的可能性。它不仅保持了扩散模型的高质量生成能力,还提供了语义丰富、易于操作的潜在表示,支持各种下游任务。
DiffAE的成功表明,结合不同类型模型的优点是一个很有前景的研究方向。未来可能会看到更多类似的混合模型,以解决各种复杂的视觉任务。此外,将DiffAE的思想扩展到其他领域,如视频、3D等,也是很有潜力的研究方向。
总的来说,Diffusion Autoencoders为图像生成和编辑领域提供了一个强大而灵活的新工具,相信它会在未来的研究和应用中发挥重要作用。🚀🎨









