
DLTA-AI:革新数据标注与跟踪的AI助手
在人工智能和计算机视觉快速发展的今天,高质量的标注数据集对于训练优秀的模型至关重要。然而,数据标注一直是一项耗时耗力的工作。为了解决这个问题,DLTA-AI应运而生,它是一款革命性的开源数据标注工具,旨在通过集成最先进的计算机视觉模型,为研究人员和开发者提供一个高效、直观且功能强大的标注平台。
什么是DLTA-AI?
DLTA-AI(Data Labeling, Tracking and Annotation with AI)是下一代数据标注工具,它巧妙地将最先进的计算机视觉模型与流行的标注工具Labelme相结合,为用户提供了一个无缝的标注体验和直观的工作流程。这个创新的工具使得创建图像数据集变得比以往任何时候都更加简单和高效。
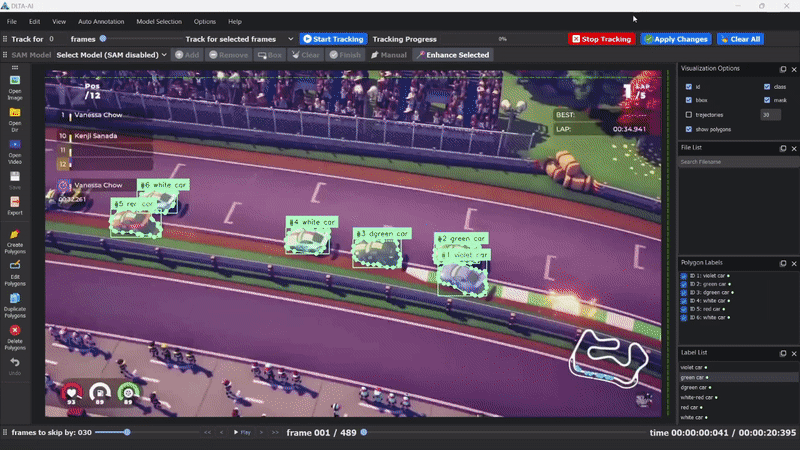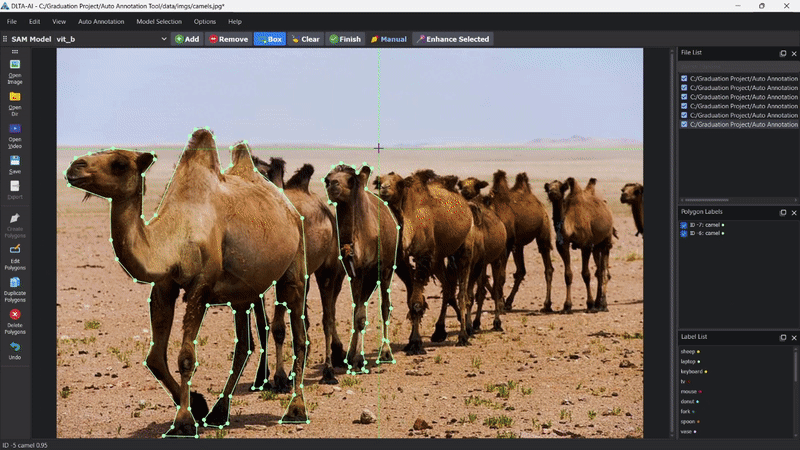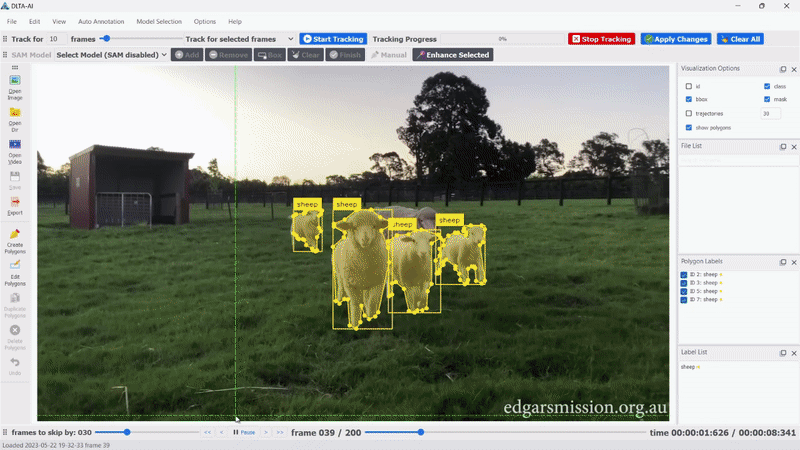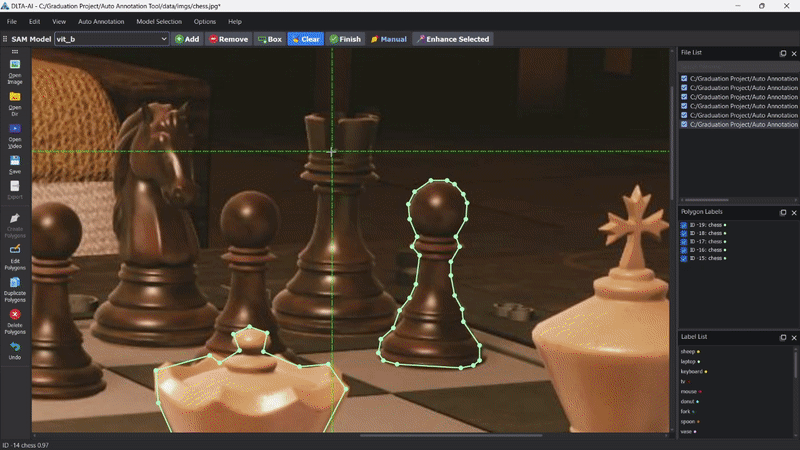
DLTA-AI的核心特性
- 多样化的输入模式
DLTA-AI支持多种输入模式,以适应不同的应用场景:
- 单图模式:加载单张图像进行标注
- 目录模式:加载整个图像目录,适用于批量标注
- 视频模式:直接加载视频文件进行标注
- 视频帧提取模式:将视频转换为帧序列进行标注
- 强大的分割模型支持
DLTA-AI集成了多种先进的分割模型:
- MMDetection库中的多种实例分割、目标检测和全景分割模型
- Meta公司的Segment Anything (SAM)模型,支持零样本分割
- YOLOv8系列模型,提供快速且准确的结果
用户可以通过内置的模型浏览器轻松比较、下载和选择合适的模型。
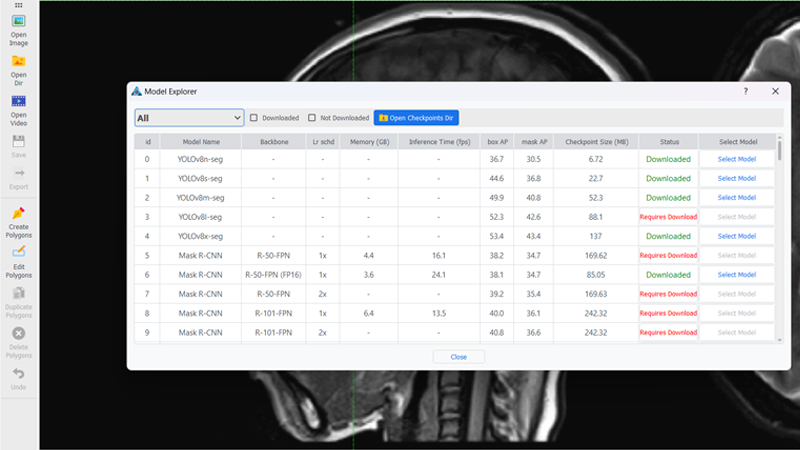
- 灵活的分割参数调整
DLTA-AI提供了丰富的分割参数调整选项:
- 置信度阈值:过滤低置信度的检测结果
- IOU阈值:基于交并比进行非极大值抑制
- 类别选择:自定义需要分割的目标类别
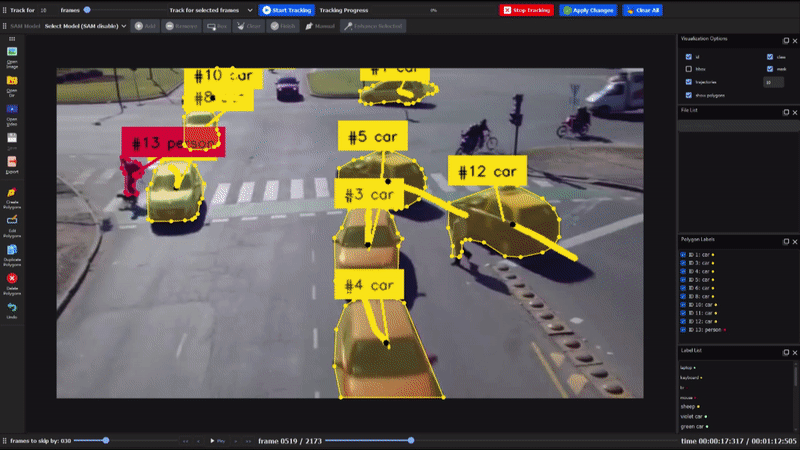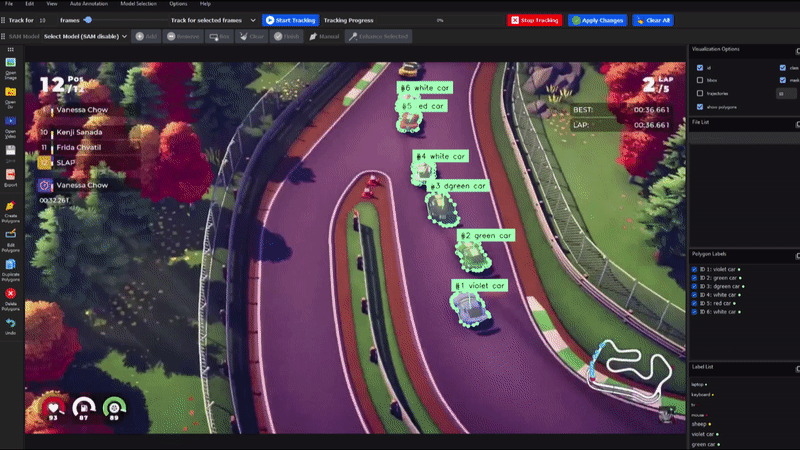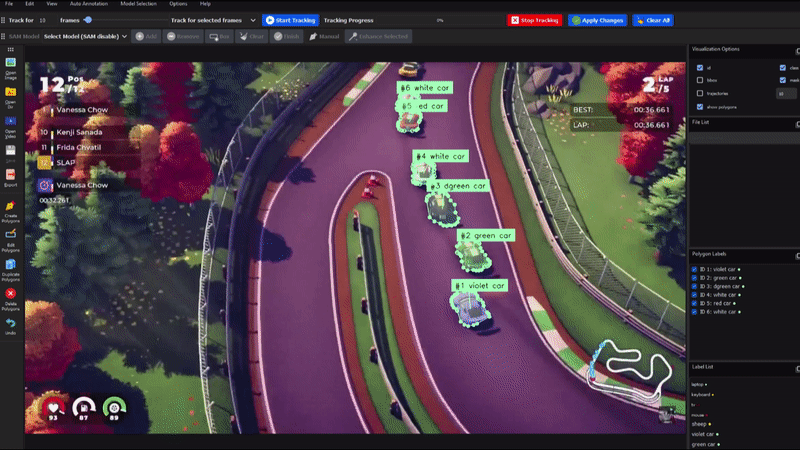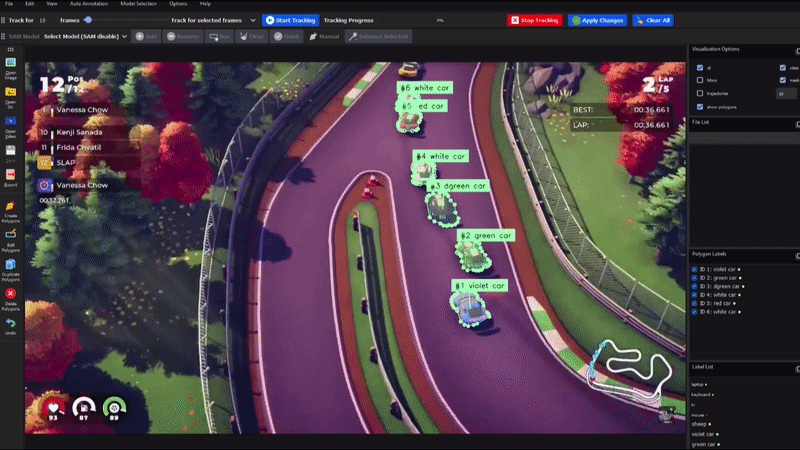
- 创新的对象跟踪功能
DLTA-AI不仅支持图像标注,还提供了完整的视频对象跟踪解决方案:
- 5种不同的跟踪算法可供选择
- 视频导航、跟踪设置和可视化选项
- 跟踪结果的编辑和删除功能,支持跨帧传播
- 半自动插值方法,用于修复遮挡和异常行为
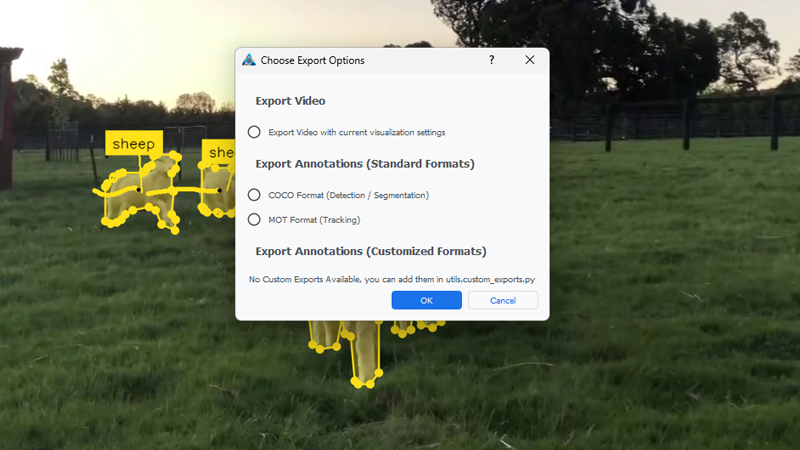
- 灵活的导出选项
DLTA-AI支持多种标准格式的导出:
- 实例分割结果可导出为COCO格式
- 跟踪结果可导出为MOT格式
- 支持将跟踪结果导出为视频文件,并可自定义可视化选项
- 用户可以定义自己的导出格式,满足特定需求
- 其他实用功能
- 支持多模型融合,结合不同模型的优势
- 显示运行时类型(CPU/GPU)和GPU内存使用情况
- 支持浅色/深色主题,自动同步系统主题
- 完全可定制的用户界面,支持拖放和显示/隐藏组件
- 长时间任务的操作系统通知
- 使用orjson进行更快的JSON序列化
- 额外脚本用于评估分割结果和从视频中提取帧
为什么选择DLTA-AI?
-
开源和可定制:DLTA-AI是一个完全开源的项目,用户可以根据自己的需求进行定制和扩展。
-
全面的AI支持:集成了多种先进的计算机视觉模型,为用户提供强大的自动标注能力。
-
灵活的工作流程:支持多种输入模式和导出格式,适应不同的应用场景。
-
直观的用户界面:现代化和功能丰富的界面设计,提供流畅的用户体验。
-
活跃的社区支持:作为一个开源项目,DLTA-AI拥有活跃的开发者社区,不断推动工具的改进和更新。
安装和使用
DLTA-AI的安装非常简单,只需要在创建新的Python环境并安装PyTorch后,使用pip安装DLTA-AI即可:
pip install DLTA-AI
安装完成后,可以通过以下命令启动DLTA-AI:
python -m DLTA_AI_app.main
详细的安装指南和常见问题解决方案可以在DLTA-AI用户指南中找到。
贡献与支持
DLTA-AI是一个开源项目,欢迎社区成员以各种方式做出贡献:
- 提交issues报告bug或建议新功能
- 创建pull requests修复问题或添加新特性
- 参与代码审查过程
- 在社交媒体上分享DLTA-AI,帮助扩大项目影响力
结语
DLTA-AI作为一款创新的数据标注工具,正在为计算机视觉领域的研究者和开发者带来前所未有的便利。通过集成先进的AI模型,DLTA-AI不仅大大提高了标注效率,还为用户提供了更加精确和一致的标注结果。随着项目的不断发展和社区的积极参与,我们有理由相信DLTA-AI将在未来继续引领数据标注工具的创新,为人工智能和计算机视觉的进步做出重要贡献。
无论您是研究人员、开发者还是数据科学家,DLTA-AI都将成为您数据准备工作流程中不可或缺的得力助手。立即尝试DLTA-AI,体验AI驱动的数据标注新时代吧!









