
DrQA: 开启智能问答新纪元
在人工智能和自然语言处理快速发展的今天,如何让机器像人类一样理解文本并回答问题成为了一个热门研究方向。Facebook研究院开发的DrQA(Document Reader and Question Answerer)系统在这一领域取得了重大突破,它能够从维基百科这样的大规模开放文档中准确回答各种问题,展现出了令人瞩目的性能。
DrQA的工作原理
DrQA采用了一个两阶段的问答流程:
-
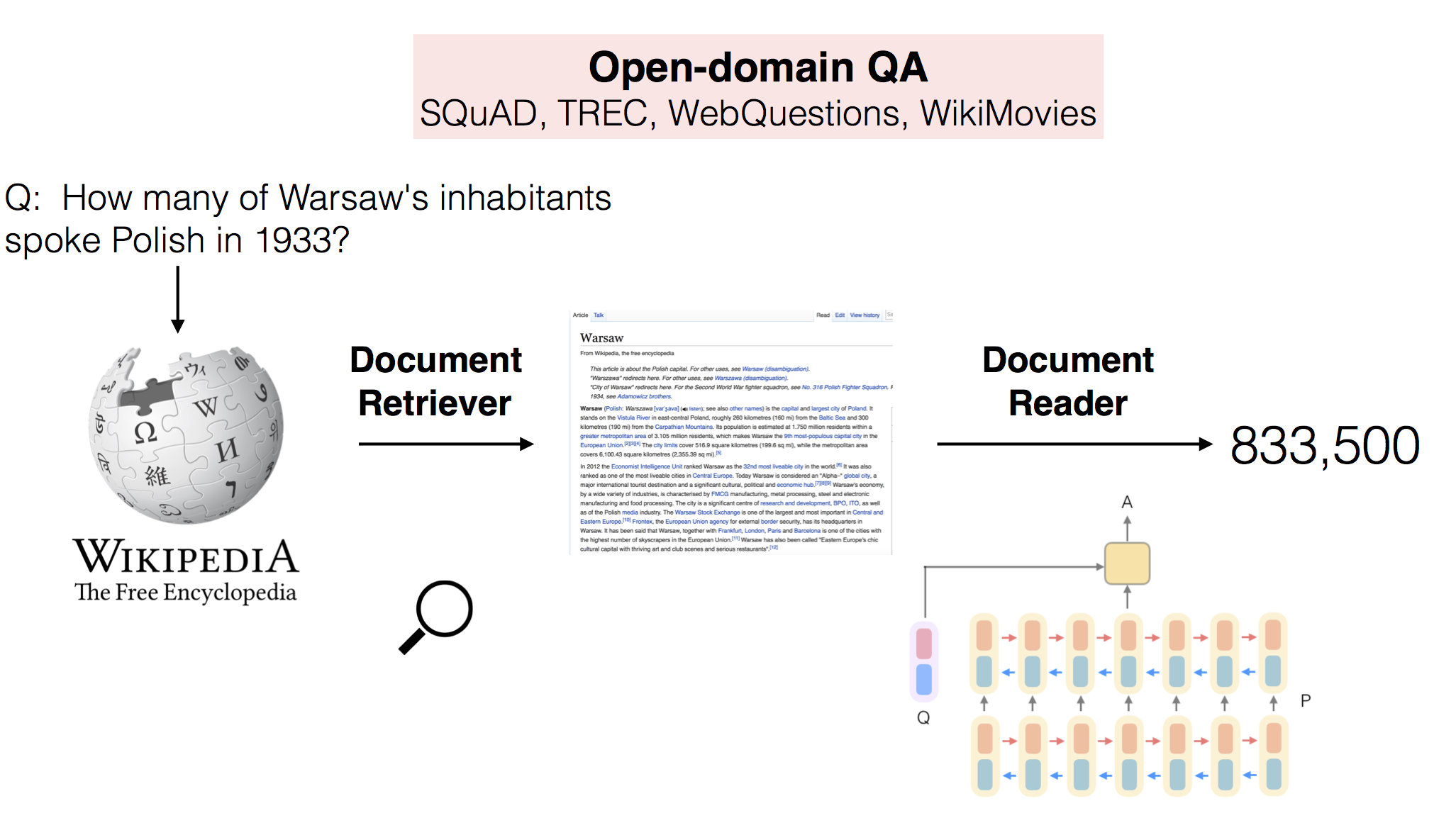
文档检索(Document Retriever): 首先利用TF-IDF等算法从海量文档中快速检索出与问题最相关的几个文档。这一步骤极大缩小了搜索范围,提高了效率。
-
文档阅读器(Document Reader): 然后使用深度学习模型从检索出的文档中定位并提取出准确的答案。这一步骤是DrQA的核心,采用了多层循环神经网络来理解文本语义并定位答案。
这种组合方法很好地平衡了检索效率和答案准确性,使DrQA能够在大规模语料上实现开放域问答。
DrQA的主要特点
-
开放域问答能力: DrQA不局限于特定领域,而是能够回答各种开放性问题。这得益于其使用维基百科作为知识源,涵盖了广泛的主题。
-
端到端的训练: DrQA采用端到端的深度学习方法,无需繁琐的特征工程,可以直接从原始文本学习到有效的表示。
-
多任务学习: DrQA通过在多个数据集上联合训练,提高了模型的泛化能力,使其在各种问答任务中都能表现出色。
-
可扩展性: 尽管DrQA主要使用维基百科作为知识源,但其架构设计使得它可以轻松扩展到其他文档集合,如企业内部文档等。
DrQA的应用前景
DrQA在自然语言处理和人工智能领域展现出了广阔的应用前景:
-
智能客服: DrQA可以应用于智能客服系统,帮助企业快速准确地回答客户问题,提高服务质量和效率。
-
知识管理: 在企业内部,DrQA可以用于构建智能知识管理系统,帮助员工快速检索和获取所需信息。
-
教育辅助: DrQA可以为在线教育平台提供智能问答功能,帮助学生解答疑问,提升学习体验。
-
科研助手: 研究人员可以利用DrQA快速检索和总结相关文献,提高研究效率。
实现你自己的DrQA系统
如果你对DrQA感兴趣并想尝试实现自己的问答系统,以下是一些建议步骤:
-
环境准备: 确保你的系统安装了Python 3.5或更高版本,以及PyTorch等必要的深度学习框架。
-
获取代码: 你可以从GitHub上克隆DrQA的官方代码仓库:
git clone https://github.com/facebookresearch/DrQA.git cd DrQA -
安装依赖: 使用pip安装所需的Python包:
pip install -r requirements.txt -
准备数据: DrQA使用SQuAD数据集进行训练。你可以下载并预处理这个数据集:
python scripts/reader/preprocess.py data/datasets/ -
训练模型: 使用预处理好的数据来训练DrQA模型:
python scripts/reader/train.py --data-dir data/datasets --train-file SQuAD-v1.1-train.txt --dev-file SQuAD-v1.1-dev.txt --model-dir models -
测试和使用: 训练完成后,你可以使用DrQA来回答问题:
python scripts/reader/predict.py --model models/your_model.mdl --data-dir data/datasets --test-file SQuAD-v1.1-test.txt
结语
DrQA作为一种强大的开放域问答系统,不仅在学术界引起了广泛关注,也为工业界的智能问答应用提供了新的可能性。随着自然语言处理技术的不断进步,我们有理由相信,像DrQA这样的系统将在未来发挥越来越重要的作用,为人类获取和处理信息带来革命性的变化。
无论你是研究人员、开发者还是对AI感兴趣的爱好者,DrQA都值得你深入探索和实践。通过理解和应用DrQA的原理,你将能够构建出更智能、更高效的问答系统,为人工智能的发展贡献自己的力量。
让我们共同期待DrQA和问答技术的更多突破,开创人机交互的新纪元!


















