
DS-1000:数据科学代码生成的新基准
数据科学作为一个快速发展的领域,对高效的代码生成工具有着迫切的需求。为了推动这一领域的进步,研究人员开发了DS-1000基准测试集,这是一个全面而可靠的数据科学代码生成评估工具。
DS-1000的核心特性
DS-1000基准包含1000个涵盖7个常用Python库的数据科学问题,具有以下三个核心特性:
-
多样性和实用性: DS-1000的问题来源于Stack Overflow,反映了现实世界中数据科学家面临的各种实际应用场景。这确保了基准测试的相关性和实用价值。
-
可靠的评估指标: DS-1000采用多标准评估方法,不仅通过运行测试用例检查功能正确性,还通过限制API使用或关键词来约束表面形式。这种严格的评估方法使得只有1.8%的Codex-002预测解决方案被错误接受,大大提高了评估的可靠性。
-
防止记忆效应: 为了防止模型仅仅通过记忆预训练数据中的解决方案来回答问题,DS-1000对原始Stack Overflow问题进行了轻微修改。这确保了模型必须真正理解并解决问题,而不是简单地回忆已知答案。

图1: DS-1000中的一个NumPy示例问题,涉及随机性,需要使用专业知识测试。
DS-1000的数据构成
DS-1000包含1000个问题,源自451个独特的Stack Overflow问题。为了防止潜在的记忆效应,超过一半的DS-1000问题是经过修改的:
- 152个表面扰动
- 235个语义扰动
- 162个困难重写
这种多样化的问题集确保了基准测试的全面性和挑战性。
评估方法和结果
DS-1000采用了严格的评估标准,包括功能正确性测试和表面形式约束。目前最好的公开系统(Codex-002)在DS-1000上的准确率为43.3%,这表明还有很大的改进空间。
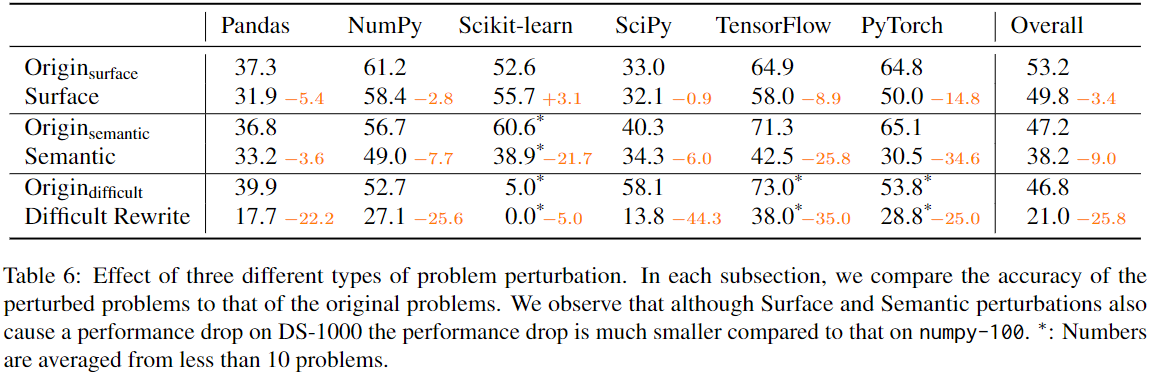
图2: Codex-002模型在DS-1000各个库上的表现。
DS-1000的应用价值
-
推动模型进步: DS-1000为研究人员提供了一个标准化的测试平台,可以客观评估和比较不同代码生成模型的性能。
-
实际应用参考: 对于数据科学从业者,DS-1000中的问题反映了实际工作中可能遇到的各种场景,可以作为学习和参考的资源。
-
教育培训工具: DS-1000可以作为教育机构和培训项目的辅助材料,帮助学生和学员掌握数据科学编程技能。
-
产品开发指南: 对于开发数据科学工具和平台的公司,DS-1000提供了用户需求的洞察,可以指导产品功能的设计和优化。
未来展望
DS-1000的发布为数据科学代码生成领域带来了新的机遇和挑战。随着大语言模型和人工智能技术的不断进步,我们可以期待看到更多创新性的解决方案来应对DS-1000提出的挑战。未来的研究方向可能包括:
- 开发更高效的代码生成算法
- 提高模型对数据科学领域专业知识的理解
- 探索如何将DS-1000的评估方法扩展到其他编程领域
结语
DS-1000作为一个全面而可靠的数据科学代码生成基准,为这一快速发展的领域提供了宝贵的评估工具。它不仅推动了技术的进步,也为数据科学教育和实践提供了重要参考。随着更多研究者和开发者参与到这个项目中来,我们有理由相信,DS-1000将继续推动数据科学编程工具的创新和发展,最终使数据科学工作变得更加高效和智能。









