
EasyContext:开启语言模型长上下文时代
在人工智能和自然语言处理领域,语言模型的上下文长度一直是一个重要的研究焦点。近期,由Zhang Peiyuan领导的研究团队推出的EasyContext项目在这一领域取得了突破性进展。该项目通过创新的内存优化和训练技巧,成功将语言模型的上下文长度扩展到100万个token,而且只需要最小的硬件支持。这一成果不仅大大提升了语言模型的性能,也为未来更广泛的应用打开了新的可能性。
突破性技术:简单而强大
EasyContext项目的核心思想是将现有的技术进行巧妙组合,以实现长上下文语言模型的训练。具体来说,该项目主要采用了以下几种技术:
- 序列并行化(Sequence parallelism)
- Deepspeed zero3 offload技术
- Flash attention及其融合交叉熵核心
- 激活检查点(Activation checkpointing)
这些技术的组合使得EasyContext能够在有限的硬件资源下实现惊人的性能。例如,使用8台A100 GPU就可以训练上下文长度为70万个token的Llama2-7B模型,而使用16台A100 GPU则可以将上下文长度扩展到100万个token的Llama2-13B模型。

多样化的序列并行方法
EasyContext项目支持多种序列并行方法,包括:
- Ring attention: 基于Shenggui等人和Liu等人的研究,特别是Zilin的实现。
- Dist flash attention: 之前称为LightSeq,由Li等人提出。
- Deepspeed Ulysses: 由Jacobs等人提出,Jiarui实现。
这些方法的多样性为研究人员提供了更多的选择,以适应不同的硬件配置和训练需求。
实现细节与性能表现
EasyContext项目的一个重要特点是,它能够在不使用任何近似方法的情况下,实现全面微调、完整注意力机制和全序列长度的训练。这意味着模型的质量没有任何妥协。
在性能方面,EasyContext展示了令人印象深刻的结果。例如,在"大海捞针"(Needle-in-a-haystack)任务中,EasyContext训练的模型表现出色,能够在极长的上下文中准确定位关键信息。
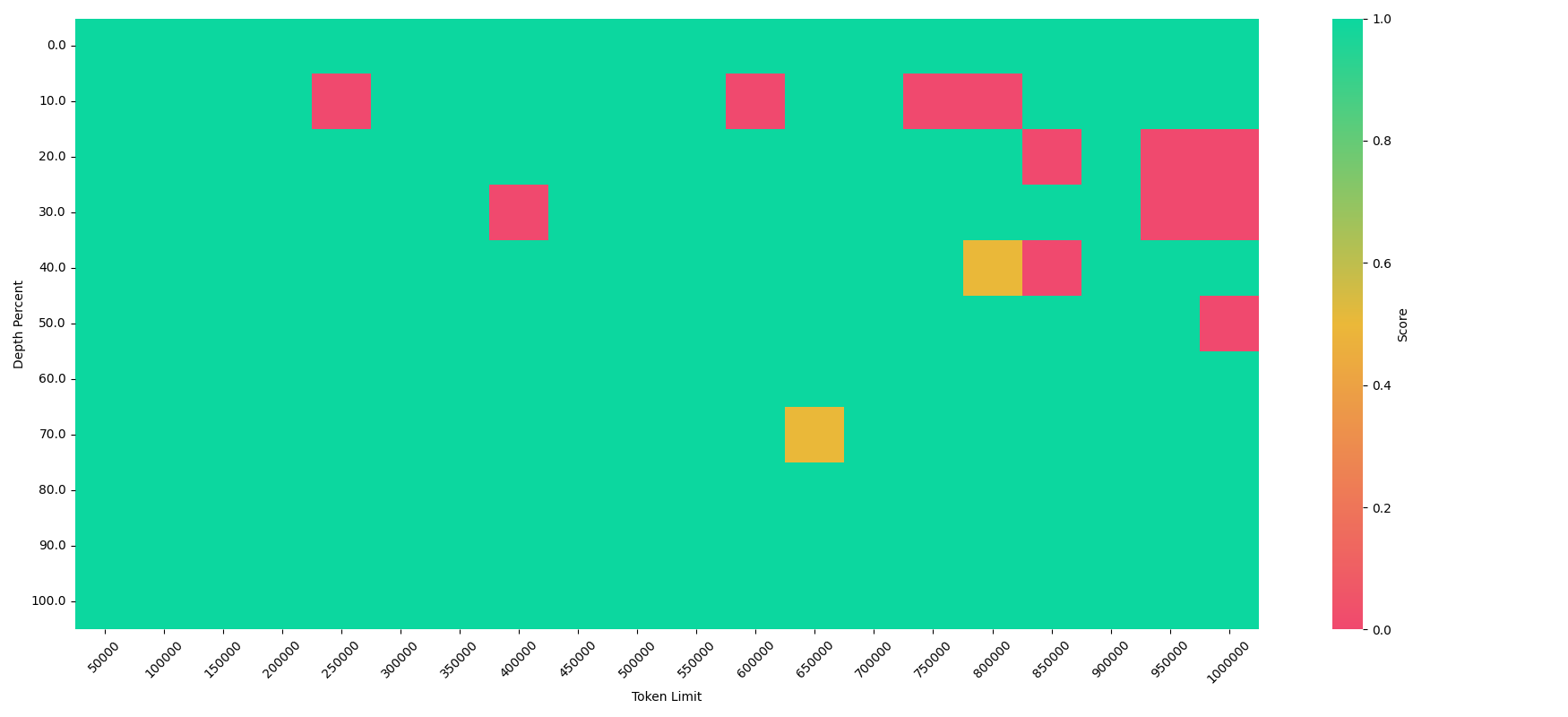
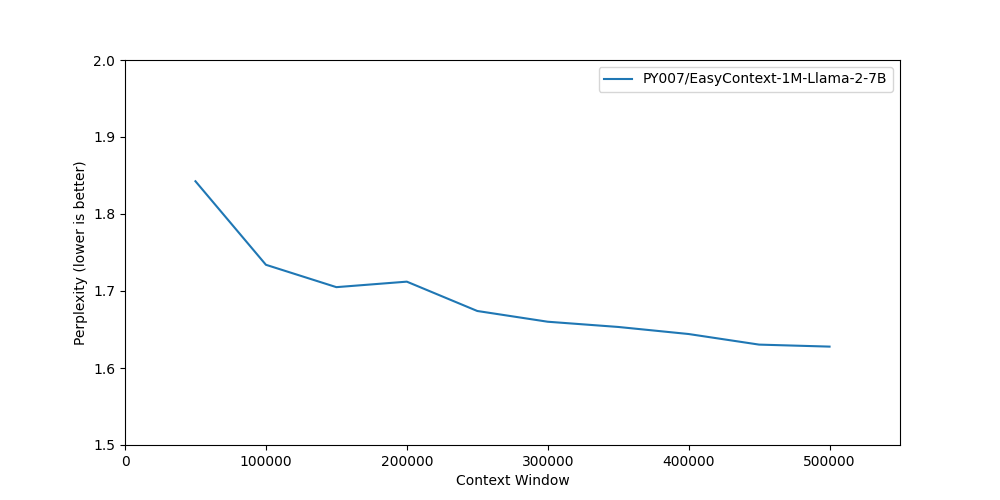
在困惑度(Perplexity)测试中,EasyContext训练的模型同样表现优异,显示出在长文本理解方面的强大能力。
安装与使用
EasyContext项目的安装相对简单,主要依赖于Python 3.10.0、PyTorch 2.4.0 (nightly)和CUDA 11.8。详细的安装步骤如下:
conda create -n easycontext python=3.10 -y && conda activate easycontext
pip install --pre torch==2.4.0.dev20240324 --index-url https://download.pytorch.org/whl/nightly/cu118
pip install packaging && pip install ninja && pip install flash-attn --no-build-isolation --no-cache-dir
pip install -r requirements.txt
值得注意的是,使用PyTorch nightly版本是必要的,因为PyTorch 2.2.0在处理70万token的上下文长度时可能会出现内存溢出(OOM)问题。
评估与训练
EasyContext提供了详细的评估脚本,包括"大海捞针"任务和困惑度测试。这些脚本允许研究人员全面评估模型在不同上下文长度下的性能。
在训练方面,EasyContext通过逐步增加Llama-2-7B模型的rope基频到1B,成功训练出了能够处理近100万token上下文的模型。值得注意的是,这个模型仅仅使用了51.2万token的序列长度进行训练,却能泛化到近100万token的上下文,展示了惊人的扩展能力。
速度与效率
在速度方面,EasyContext项目进行了详细的测试和比较。结果显示,从数据并行切换到环形注意力机制只会导致吞吐量的轻微下降。然而,当增加序列长度时,由于自注意力机制的二次复杂度,吞吐量会显著下降。
| 设置 | 8个A100上的吞吐量 |
|---|---|
| 64K, 数据并行 | 10240 tokens/s |
| 64K, 环形注意力 | 7816 tokens/s |
| 128K, 环形注意力 | 4266 tokens/s |
| 512K, 环形注意力 | 2133 tokens/s |
| 700K, 环形注意力 | 1603 tokens/s |
这些数据为研究人员提供了宝贵的参考,有助于在不同场景下选择最适合的训练策略。
未来展望
EasyContext项目的成功不仅限于语言模型领域。研究团队指出,这项技术在视频生成等领域也有巨大潜力。例如,700K的上下文长度意味着我们现在可以微调或生成1500帧的视频,假设每帧包含512个token。这为未来的多模态AI应用打开了新的可能性。
此外,EasyContext项目还列出了一系列待办事项,包括:
- 切换到猴子补丁(monkey patch)实现
- 添加dist flash attn
- 建立pip包
- 如果有额外计算资源,开发EasyContext-Llama-2-13B-1M和EasyContext-Mistral-7B-1M
- 指令微调
- 添加PoSE(Position-based Scaled Encoding)
这些计划显示了项目团队持续创新和改进的决心,也为社区贡献者提供了参与的机会。
结语
EasyContext项目的成功标志着语言模型研究进入了一个新的阶段。通过创新的技术组合和巧妙的优化策略,该项目成功地将语言模型的上下文长度扩展到了前所未有的水平,同时保持了模型的高质量和训练的高效率。
这一突破不仅提升了语言模型在长文本理解和生成方面的能力,也为其他领域如视频生成、多模态AI等提供了新的可能性。随着EasyContext技术的进一步发展和应用,我们有理由期待在自然语言处理和人工智能领域看到更多令人兴奋的进展。
对于研究人员和开发者来说,EasyContext项目提供了一个强大而灵活的工具,可以用于探索长上下文语言模型的潜力。通过开源代码和详细的文档,该项目也为整个AI社区的协作和创新做出了重要贡献。
随着技术的不断进步和更多研究的投入,我们可以期待看到EasyContext在更广泛的应用场景中发挥作用,推动自然语言处理技术向着更高水平迈进。这无疑将为人工智能的未来发展注入新的活力和可能性。









