
fast_rnnt: 加速RNN-T损失计算的利器
RNN-T (Recurrent Neural Network Transducer) 是语音识别等序列到序列任务中广泛使用的模型架构。然而,RNN-T的训练过程中涉及复杂的损失计算,往往成为整个训练流程的性能瓶颈。为了解决这一问题,fast_rnnt应运而生。它是一个专门用于高效计算RNN-T损失的PyTorch库,通过巧妙的算法设计大幅提升了计算速度和内存效率。
什么是fast_rnnt?
fast_rnnt是由语音识别领域知名研究者Dan Povey主导开发的开源项目。它实现了一种名为"pruned rnnt"的创新算法,可以显著加速RNN-T损失的计算过程。该项目最初是作为k2工具包的一部分开发的,后来被单独提取出来成为一个独立的库,以方便那些只需要RNN-T损失计算功能的用户。
fast_rnnt的核心思想是通过一个简化的joiner网络(仅包含编码器和解码器的加法运算)来获得RNN-T递归的剪枝边界,然后利用这些剪枝边界来评估完整的非线性joiner网络。这种方法可以大大减少需要计算的格点数量,从而显著提高计算效率。
pruned rnnt的工作原理
pruned rnnt算法的关键在于识别出RNN-T损失计算中真正重要的部分。研究发现,在每个时间帧,只有少量节点具有非零梯度,这为我们提供了优化的机会。
下图直观地展示了这一发现:
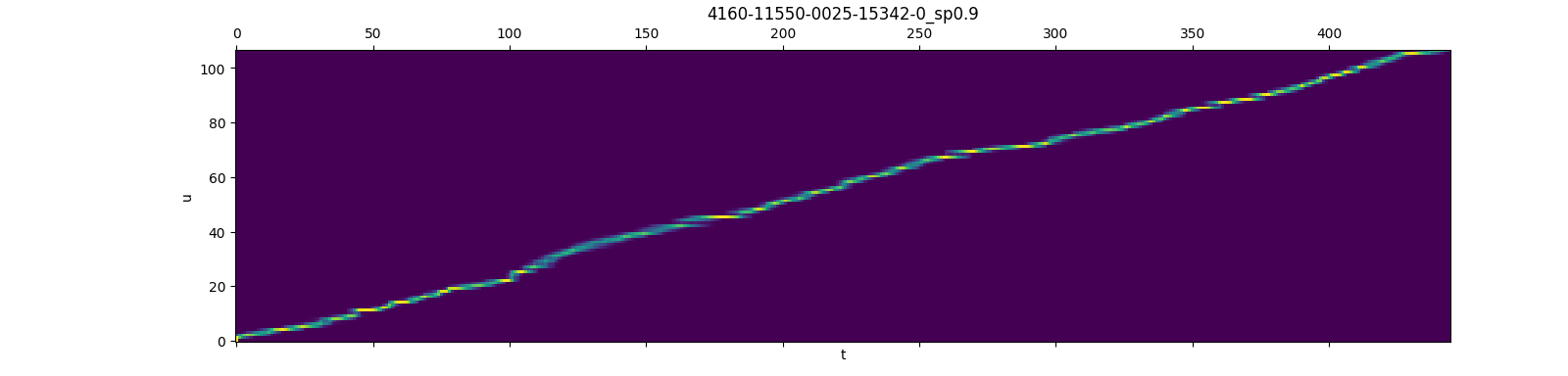
这张图展示了使用rnnt_loss_simple函数(设置return_grad=true)得到的格点节点梯度。我们可以清楚地看到,在每个时间帧,只有一小部分节点具有非零梯度。这个观察结果为pruned RNN-T损失提供了理论基础,即我们可以通过限制每帧的符号数量来优化计算。
fast_rnnt的主要特性
-
高效的损失计算: fast_rnnt实现了多种RNN-T损失计算函数,包括
rnnt_loss_simple、rnnt_loss_smoothed和rnnt_loss_pruned等,以适应不同的应用场景。 -
灵活的安装选项: 支持通过pip快速安装,也可以从源代码编译安装。用户可以根据需要选择是否启用CUDA支持。
-
广泛的PyTorch版本兼容性: 支持PyTorch 1.5.0及以上版本,确保与大多数现有项目兼容。
-
详细的使用文档: 提供了丰富的代码示例和使用说明,帮助用户快速上手和集成。
-
出色的性能表现: 根据基准测试结果,fast_rnnt在计算速度和内存使用方面都远超其他实现。
如何使用fast_rnnt?
fast_rnnt的安装非常简单,可以通过pip一键完成:
pip install fast_rnnt
安装完成后,可以通过以下代码检查安装是否成功:
import fast_rnnt
print(fast_rnnt.__version__)
fast_rnnt提供了多种损失计算函数,以下是rnnt_loss_simple的使用示例:
import torch
import fast_rnnt
B, T, S, C = 1, 10, 5, 20 # 批大小、时间步、序列长度、类别数
am = torch.randn((B, T, C), dtype=torch.float32)
lm = torch.randn((B, S + 1, C), dtype=torch.float32)
symbols = torch.randint(0, C, (B, S))
termination_symbol = 0
boundary = torch.zeros((B, 4), dtype=torch.int64)
boundary[:, 2] = S # target_lengths
boundary[:, 3] = T # num_frames
loss = fast_rnnt.rnnt_loss_simple(
lm=lm,
am=am,
symbols=symbols,
termination_symbol=termination_symbol,
boundary=boundary,
reduction="sum",
)
对于更高级的用法,如rnnt_loss_pruned,fast_rnnt还提供了更复杂的API,允许用户更精细地控制损失计算过程。
性能对比
fast_rnnt的性能优势是显著的。根据基准测试结果,fast_rnnt在计算速度和内存使用方面都远超其他实现:
| 实现方法 | 平均步骤时间 (μs) | 峰值内存使用 (MB) |
|---|---|---|
| torchaudio | 601,447 | 12,959.2 |
| fast_rnnt(unpruned) | 274,407 | 15,106.5 |
| fast_rnnt(pruned) | 38,112 | 2,647.8 |
| optimized_transducer | 567,684 | 10,903.1 |
| warprnnt_numba | 229,340 | 13,061.8 |
| warp-transducer | 210,772 | 13,061.8 |
从表中可以看出,fast_rnnt的pruned版本在计算速度上比其他方法快了一个数量级,同时内存使用也大幅降低。这意味着使用fast_rnnt可以显著加快RNN-T模型的训练速度,并允许在有限的GPU内存下训练更大的模型或使用更大的批量大小。
结论
fast_rnnt为RNN-T模型的训练提供了一个高效、灵活的损失计算解决方案。通过创新的pruned rnnt算法,它成功地在保持计算精度的同时,大幅提升了计算速度并降低了内存消耗。对于那些在语音识别、机器翻译等序列到序列任务中使用RNN-T模型的研究者和工程师来说,fast_rnnt无疑是一个值得尝试的工具。
随着深度学习模型规模的不断增长和训练数据量的持续扩大,像fast_rnnt这样能够提高计算效率的工具将变得越来越重要。它不仅可以加速模型训练和迭代,还能够帮助研究者在有限的计算资源下探索更复杂的模型结构。
如果你正在从事RNN-T相关的研究或开发工作,不妨尝试使用fast_rnnt来优化你的训练流程。相信它能为你的项目带来显著的性能提升。
📚 参考资料:
🔗 相关链接:









