
EfficientViT:高效高分辨率视觉任务的革命性模型
在计算机视觉领域,高分辨率密集预测任务一直是一个具有挑战性的问题。传统模型在处理高分辨率图像时往往需要庞大的计算资源,这限制了它们在实际应用中的部署。为了解决这个问题,麻省理工学院的研究人员开发了一个全新的视觉模型家族 - EfficientViT,它旨在为高分辨率密集预测视觉任务提供高效的解决方案。
EfficientViT的核心创新
EfficientViT的核心在于其独特的轻量级多尺度线性注意力模块。这个模块是EfficientViT能够在高效处理高分辨率图像的关键所在:
-
全局感受野: 通过线性注意力机制,EfficientViT能够有效捕获图像的全局上下文信息,而不需要昂贵的计算。
-
多尺度学习: 模块设计支持多尺度特征提取,使模型能够同时关注图像的局部细节和全局结构。
-
硬件友好: 所有操作都经过精心设计,以确保在GPU等硬件上能够高效运行。这使得EfficientViT特别适合实际部署。
通过这些创新,EfficientViT在保持高性能的同时,大幅降低了计算成本,为高分辨率视觉任务开辟了新的可能性。
EfficientViT的广泛应用
EfficientViT的versatility使其能够应用于多种计算机视觉任务:
- 图像分割(Segment Anything)
EfficientViT-SAM是基于EfficientViT架构开发的分割模型。它在COCO和LVIS等benchmark上展现了卓越的性能,同时保持了极高的效率。
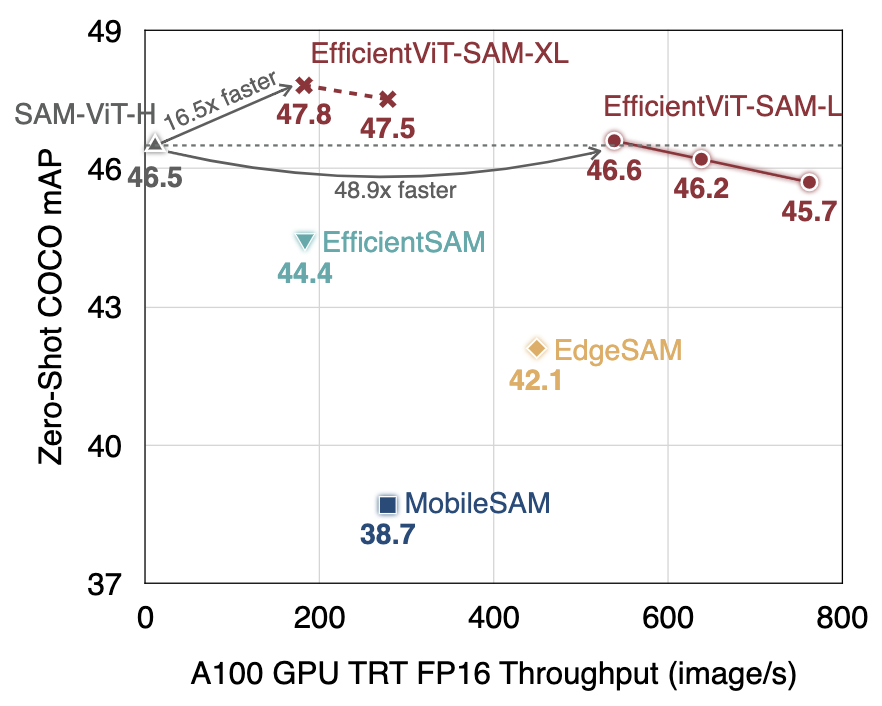
如上图所示,EfficientViT-SAM系列模型在mAP和计算效率之间取得了很好的平衡。例如,EfficientViT-SAM-XL1在1024x1024分辨率下实现了47.8的COCO mAP,而只需要37.2ms的推理延迟(在Jetson Orin上)。
- 图像分类
在ImageNet等大规模图像分类数据集上,EfficientViT同样表现出色。
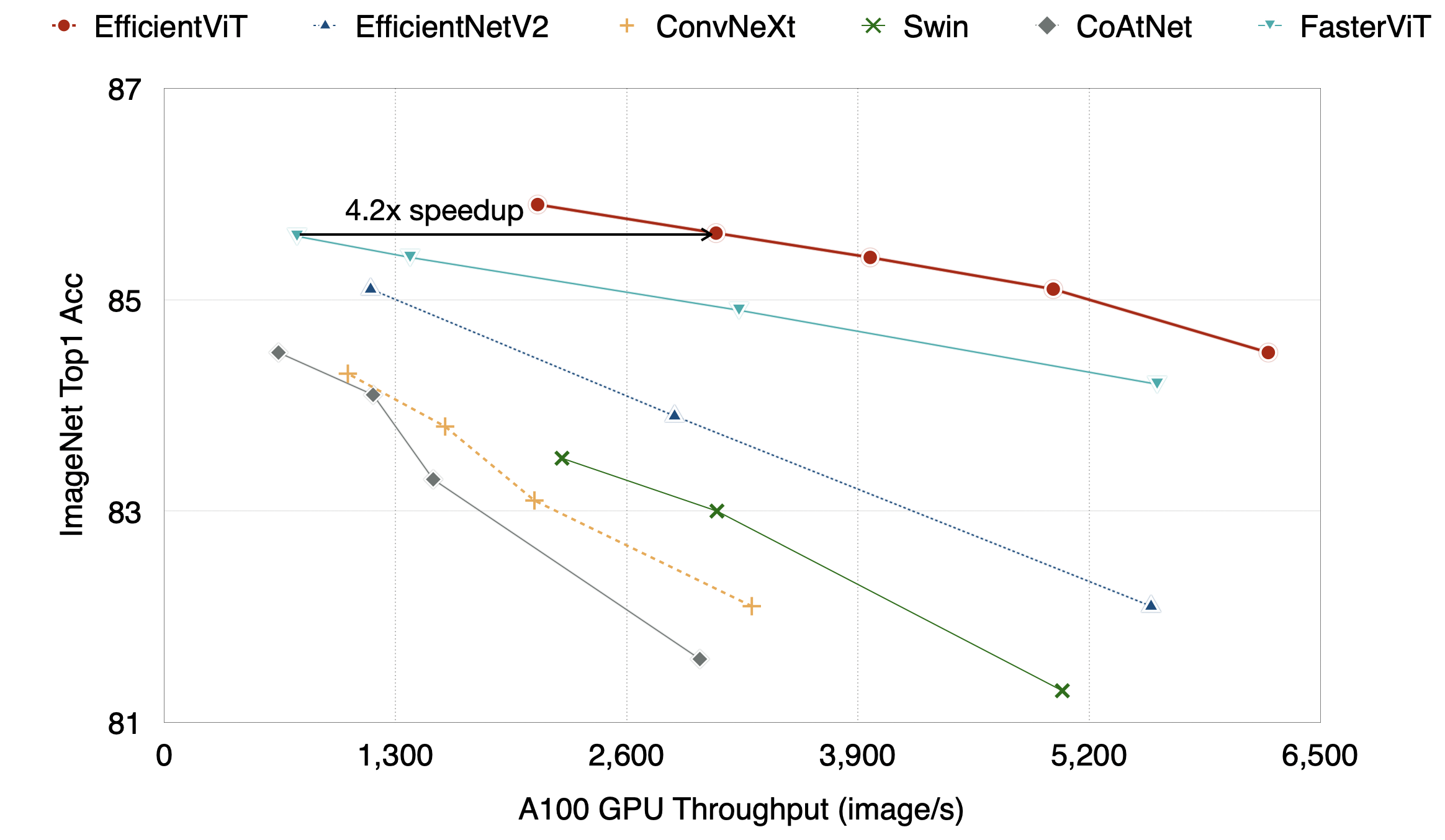
如图所示,EfficientViT在准确率和MAC(乘加运算次数)之间达到了很好的权衡,展现了其在图像分类任务上的高效性。
- 语义分割
EfficientViT在语义分割任务上也有出色表现。下面是EfficientViT在Cityscapes数据集上的语义分割演示:

可以看到,EfficientViT能够准确地对街景图像进行像素级别的语义分割,展现了其在复杂场景理解中的强大能力。
EfficientViT的实际应用
除了在标准benchmark上的出色表现,EfficientViT还在多个实际应用中展现了其价值:
-
医学影像分割: EfficientViT-SAM被用于MedficientSAM项目,并在CVPR 2024 Segment Anything In Medical Images On Laptop Challenge中获得第一名。这体现了EfficientViT在医疗领域的潜力。
-
开放集目标检测: EfficientViT被用作Grounding DINO 1.5 Edge的backbone,用于高效的开放集目标检测。这展示了EfficientViT在更广泛的计算机视觉任务中的适用性。
-
NVIDIA Jetson集成: EfficientViT已被集成到NVIDIA Jetson Generative AI Lab中,这为其在边缘计算设备上的部署提供了更多可能性。
-
GazeSAM: 研究人员将EfficientViT-SAM与视线估计技术结合,开发了GazeSAM系统。这个创新应用展示了EfficientViT与其他技术结合的潜力。

EfficientViT的未来发展
尽管EfficientViT已经取得了显著成果,但研究团队仍在持续推动其发展。未来的计划包括:
- 为ImageNet和分割任务提供预训练模型
- 开发专为云端设计的EfficientViT L系列
- 将EfficientViT应用于图像生成、CLIP、超分辨率等更多任务
这些计划显示了EfficientViT强大的扩展性和在计算机视觉领域的广阔前景。
结语
EfficientViT代表了计算机视觉领域的一个重要突破。通过创新的架构设计,它成功地在高性能和计算效率之间取得了平衡,为高分辨率密集预测任务提供了一个强大而实用的解决方案。随着持续的研究和应用,EfficientViT有望在更多领域发挥重要作用,推动计算机视觉技术向前发展。
对于研究人员和开发者来说,EfficientViT提供了一个强大的工具,可以用于构建更高效、更实用的视觉AI系统。随着其在各个领域的应用不断扩展,我们可以期待看到更多基于EfficientViT的创新应用出现,为人工智能的发展注入新的活力。









