
ElegantRL: 一个高效、可扩展的深度强化学习库
ElegantRL是由AI4Finance基金会开发的一个开源深度强化学习库。该项目旨在为用户和开发者提供一个高效、可扩展且易于使用的强化学习框架。ElegantRL具有以下几个主要特点:
云原生架构
ElegantRL采用云原生范式,通过微服务架构和容器化技术实现。它支持ElegantRL-Podracer和FinRL-Podracer等云原生部署方案,能够充分利用云平台的弹性和可扩展性。
高度可扩展性
ElegantRL充分利用了深度强化学习算法的并行性,可以轻松扩展到云平台上的数百甚至数千个计算节点。例如,它可以在具有数千个GPU的DGX SuperPOD平台上进行大规模训练。
弹性资源分配
ElegantRL允许在云平台上弹性和自动地分配计算资源,可以根据需求动态调整资源使用。
轻量级设计
ElegantRL的核心代码不到1000行,非常轻量级和易于理解。用户可以通过ElegantRL-Helloworld快速上手和学习。
高效性能
在多种测试场景(如单GPU/多GPU/GPU云)中,ElegantRL的性能都优于Ray RLlib等主流强化学习库。
稳定性好
ElegantRL采用了Hamiltonian项等多种方法来提高算法稳定性,比Stable Baselines 3等库更加稳定可靠。
实用性强
ElegantRL已在RLSolver、FinRL、FinRL-Meta等多个实际项目中得到应用,具有很强的实用性。
支持大规模并行仿真
ElegantRL支持在多个项目中使用大规模并行仿真,可以构建大量基于GPU的环境,从而大幅提高采样速度。
ElegantRL实现了以下几类主流的无模型深度强化学习算法:
- 连续动作空间的单智能体算法:DDPG、TD3、SAC、PPO、REDQ等
- 离散动作空间的单智能体算法:DQN、Double DQN、D3QN等
- 多智能体算法:QMIX、VDN、MADDPG、MAPPO、MATD3等
同时,ElegantRL还支持以下仿真器:
- Isaac Gym:用于大规模并行仿真
- OpenAI Gym、MuJoCo、PyBullet、FinRL:用于基准测试
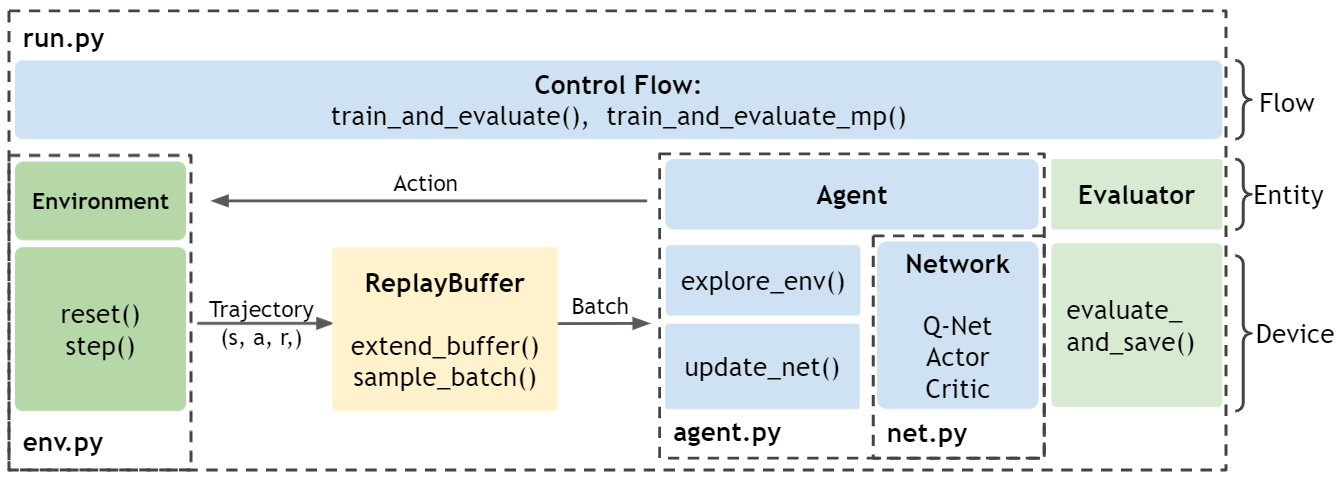
快速上手
对于初学者,ElegantRL提供了ElegantRL-Helloworld作为入门教程。用户可以按照DQN -> DDPG -> PPO的顺序运行示例代码,快速学习和掌握强化学习算法。
ElegantRL的核心结构非常简单:一个agent(agent.py)使用Actor-Critic网络(net.py)与环境(env.py)交互进行训练(run.py)。
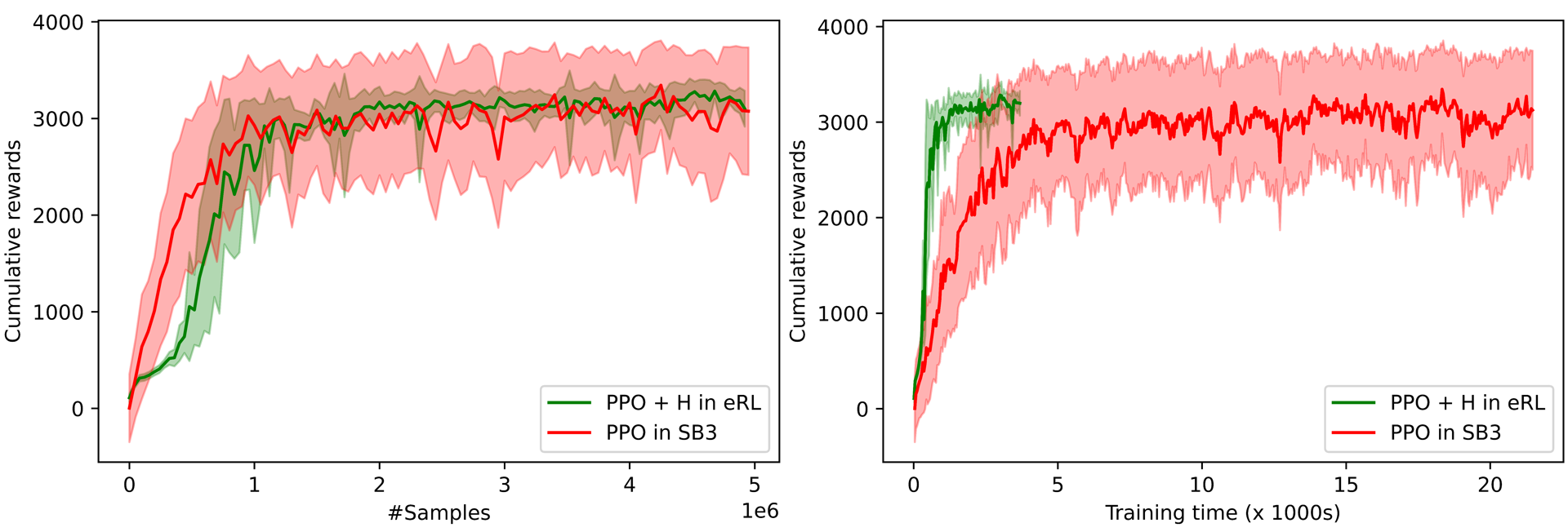
性能对比
实验表明,ElegantRL在多个测试环境中的性能都优于Ray RLlib等主流强化学习库:

同时,ElegantRL的算法稳定性也明显优于Stable Baselines 3:
安装与使用
ElegantRL的安装非常简单,只需要Python 3.6+和PyTorch 1.6+环境。可以通过pip直接安装:
pip install elegantrl
或者从GitHub安装最新版本:
git clone https://github.com/AI4Finance-Foundation/ElegantRL.git
cd ElegantRL
pip install .
总结
ElegantRL作为一个轻量级但功能强大的深度强化学习库,为研究人员和开发者提供了一个高效、可扩展的实验平台。它的云原生架构和并行训练能力,使其特别适合大规模强化学习任务。无论是初学者还是专业研究人员,都可以从ElegantRL中获益,快速实现自己的强化学习想法和应用。









