
大模型时代的到来
近年来,随着深度学习技术的快速发展和计算能力的不断提升,人工智能领域掀起了一场"大模型革命"。从2018年Google发布的BERT到2022年OpenAI推出的ChatGPT,大型预训练模型在自然语言处理、计算机视觉等多个领域取得了突破性进展,推动人工智能进入了一个全新的时代。
大模型,顾名思义就是参数规模庞大的深度学习模型。通常而言,参数量在十亿级别以上的模型都可以被称为大模型。这些模型通过在海量数据上进行预训练,可以学习到丰富的知识和强大的泛化能力,在各种下游任务中展现出惊人的性能。
本文将系统梳理大模型的发展历程,重点介绍语言模型和视觉模型两大方向的代表性工作,并探讨大模型给人工智能领域带来的深远影响。
语言大模型的发展历程
BERT:双向语言模型的里程碑
2018年10月,Google AI团队发布了BERT(Bidirectional Encoder Representations from Transformers)模型,开创了预训练语言模型的新范式。BERT采用了Transformer编码器结构,通过掩码语言模型(MLM)和下一句预测(NSP)两个预训练任务,学习文本的双向表示。
BERT的最大版本包含3.3亿参数,在16GB文本语料上训练了4天,成本约7000美元。虽然从今天的角度看,BERT的规模并不算大,但它的出现极大推动了预训练+微调范式在NLP领域的应用,为后来更大规模模型的出现奠定了基础。
GPT系列:生成式预训练模型的崛起
与BERT几乎同时,OpenAI推出了GPT(Generative Pre-Training)模型,开启了生成式预训练模型的新纪元。GPT采用了Transformer解码器结构,通过自回归语言建模任务进行预训练。
2019年2月,OpenAI发布了GPT-2,将模型规模扩大到15亿参数,在40GB网页文本上训练,展现出强大的文本生成能力。GPT-2一经发布就引发了巨大争议,OpenAI甚至一度拒绝公开完整模型,担心其可能被滥用。
2020年5月,GPT-3横空出世,以1750亿参数的惊人规模刷新了人们对语言模型的认知。GPT-3在45TB文本数据上训练,耗费了大约460万美元。更令人惊叹的是,GPT-3展现出了强大的少样本学习能力,仅通过任务描述和少量样例就能完成各种NLP任务,开创了"提示学习"(Prompt Learning)的新范式。
2022年11月,OpenAI推出了基于GPT-3.5的对话系统ChatGPT,在全球范围内掀起了AI热潮。ChatGPT展现出了接近人类的对话能力和知识运用能力,让人工智能走入了大众视野。2023年3月,OpenAI又发布了GPT-4,进一步提升了模型性能,并引入了多模态能力。
百花齐放:各大科技公司的角力
在OpenAI的带动下,各大科技公司纷纷加入大语言模型的竞赛中。Google在2020年发布了T5(Text-to-Text Transfer Transformer)模型,采用统一的文本到文本框架处理各种NLP任务。2022年,Google又推出了PaLM(Pathways Language Model),拥有5400亿参数,在计算效率上有很大提升。
微软与OpenAI达成战略合作,基于GPT-3开发了专有的大语言模型。Meta(原Facebook)则开源了OPT(Open Pre-trained Transformer)系列模型,包括1750亿参数的OPT-175B。DeepMind推出了Gopher、Chinchilla等模型,在模型规模与训练数据量的权衡上做了深入研究。
中国科技公司在大语言模型领域也不甘落后。百度的文心一言、阿里的通义千问、腾讯的混元等模型相继亮相,展现出不俗的性能。此外,智源研究院的悟道、华为的盘古α等开源大模型也受到广泛关注。
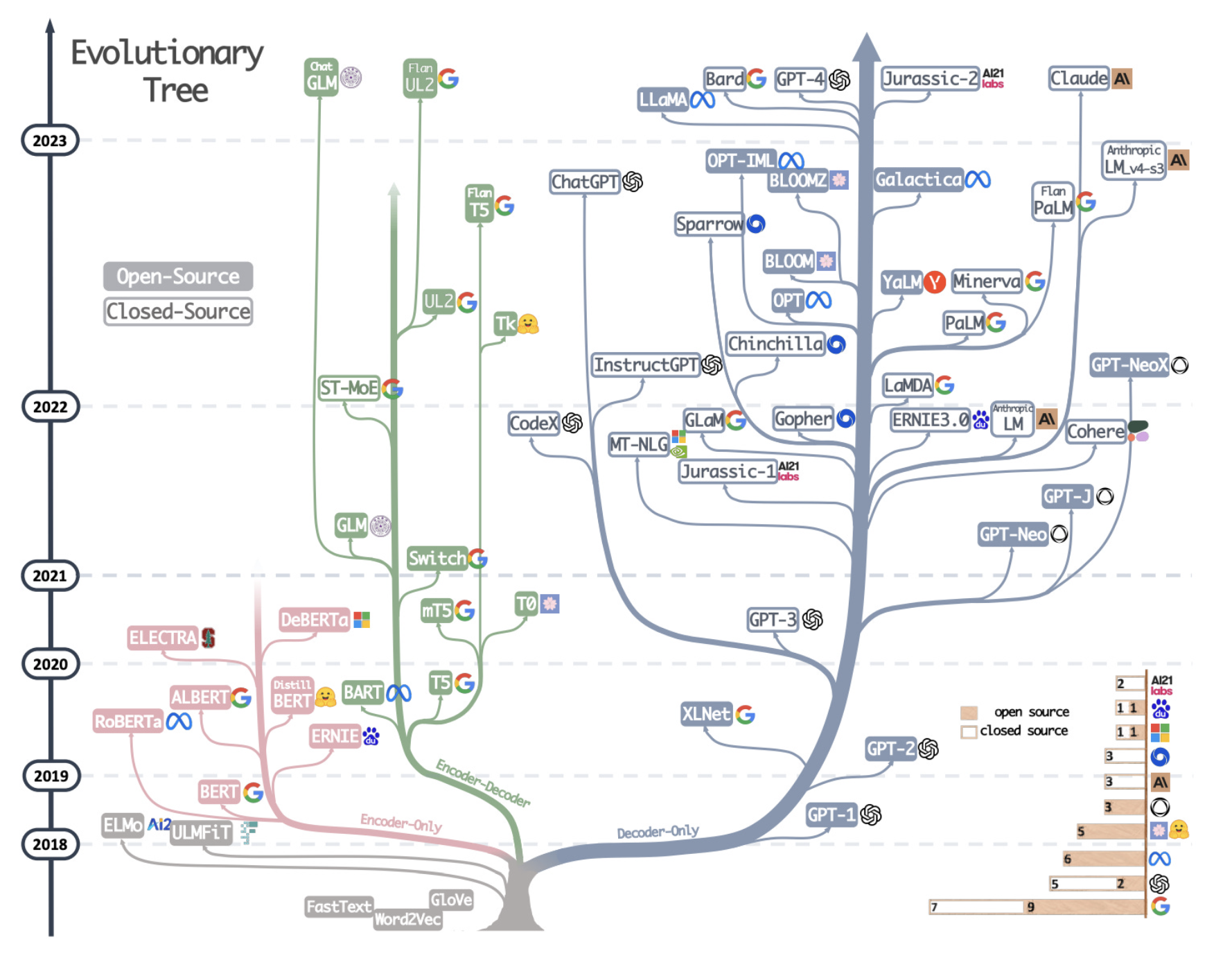
开源浪潮:大模型的民主化
随着大语言模型影响力的不断扩大,开源社区也在积极贡献自己的力量。2022年2月,Meta发布了OPT-175B模型的权重,成为首个完全开放的超大规模语言模型。2023年2月,Meta又发布了LLaMA系列模型,虽然采用了受限开源协议,但仍在社区引发了巨大反响。
在LLaMA的基础上,斯坦福大学团队推出了Alpaca模型,探索了低成本训练指令遵循模型的方法。随后,Berkeley、CMU等多所高校和众多开源组织纷纷发布了各自基于LLaMA的改进模型,如Vicuna、Koala、ChatGLM等,掀起了一股"LLaMA改装"热潮。
除LLaMA外,EleutherAI的GPT-NeoX、Stability AI的StableLM、MosaicML的MPT等开源大语言模型也受到广泛关注。这些模型为研究人员和开发者提供了宝贵的资源,大大降低了开展大模型研究的门槛。
视觉大模型:计算机视觉的新范式
DALL-E:图像生成的突破
2021年1月,OpenAI发布了DALL-E模型,将GPT-3的架构应用到了图像生成领域。DALL-E可以根据文本描述生成高质量的图像,展现出惊人的创造力和想象力。2022年4月,OpenAI又推出了DALL-E 2,进一步提升了图像质量和控制精度。
DALL-E的成功激发了研究者们在文本到图像生成方向的探索热情。Google的Imagen、Stability AI的Stable Diffusion等模型相继问世,将AI绘画推向了一个新的高度。
CLIP:视觉语言预训练的里程碑
2021年1月,OpenAI发布的另一个重要工作是CLIP(Contrastive Language-Image Pre-training)模型。CLIP通过对比学习的方式,在4亿图文对上进行预训练,学习了强大的视觉语言表示。
CLIP的核心创新在于采用了"自然语言监督"的思路,无需人工标注就能从互联网上收集的图文对中学习知识。这种方法使得模型可以轻松迁移到各种下游视觉任务中,展现出惊人的零样本学习能力。
Swin Transformer:视觉backbone的革新
2021年3月,微软亚洲研究院提出了Swin Transformer,将Transformer结构成功应用到了通用视觉backbone中。Swin Transformer通过引入局部注意力和跨窗口连接等创新,有效解决了视觉任务中的尺度问题,在多项视觉任务上取得了SOTA性能。
Swin Transformer的成功标志着计算机视觉领域的主流架构开始从CNN向Transformer转变。随后,MAE、BEiT等自监督视觉预训练方法的提出,进一步推动了视觉大模型的发展。
大模型的影响与未来展望
大模型的出现给人工智能领域带来了深远的影响:
-
性能提升:大模型在各种任务上都展现出了远超以往的性能,大大拓展了AI的应用边界。
-
范式转变:从"为特定任务设计模型"转变为"海量数据预训练+下游任务微调"的范式。
-
涌现能力:随着模型规模的增大,出现了一些意想不到的涌现能力,如少样本学习、跨模态迁移等。
-
研究方向的变化:促使研究者更多关注模型训练的效率、可解释性、安全性等方向。
-
产业影响:推动了AI技术的快速落地,催生了新的商业模式和应用场景。
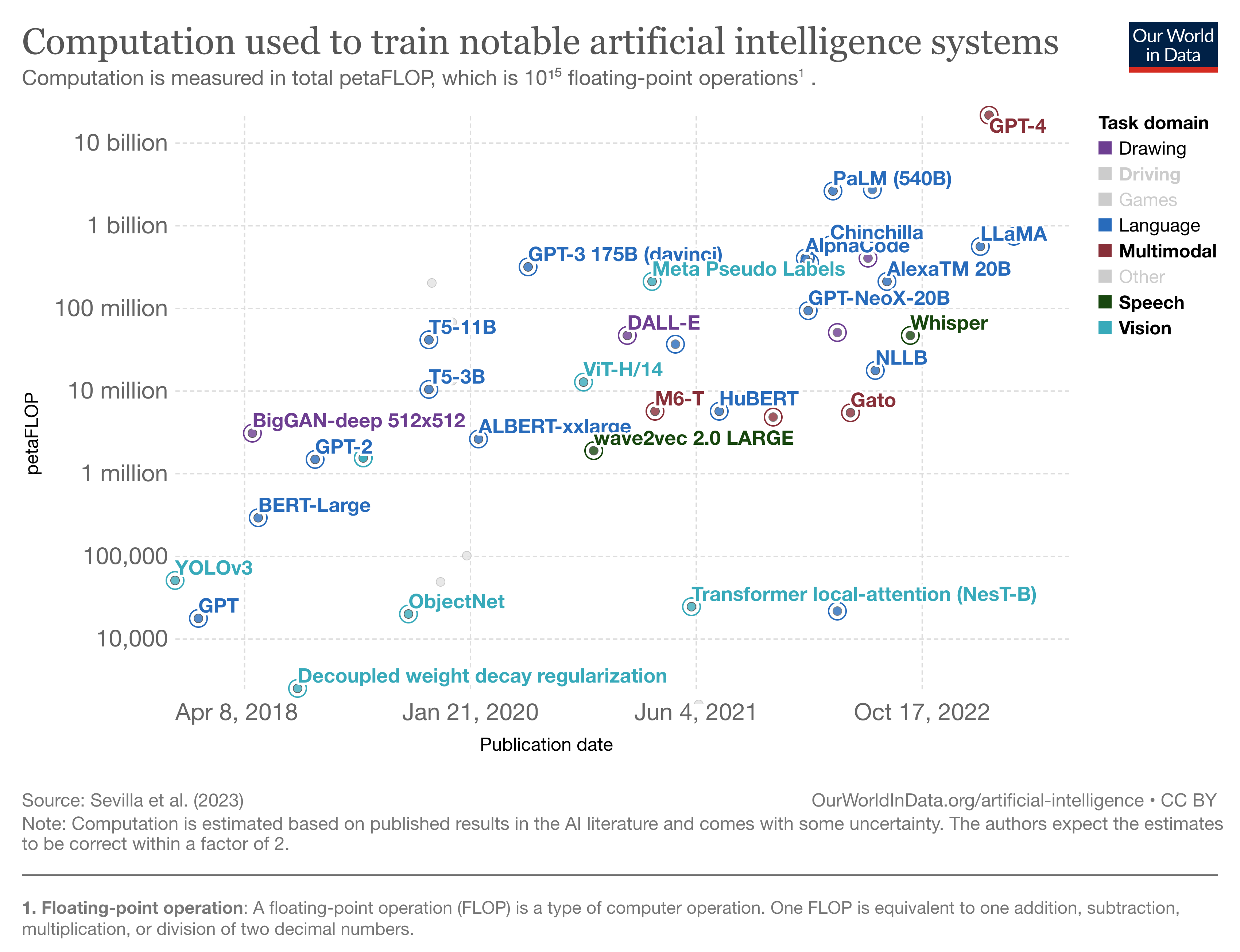
尽管大模型取得了令人瞩目的成就,但它也面临着一些挑战:
-
计算资源消耗巨大,训练成本高昂,不利于可持续发展。
-
存在偏见、幻觉等问题,亟需提升模型的可靠性和安全性。
-
黑箱特性导致可解释性差,难以应用在一些高风险场景。
-
版权和伦理问题日益凸显,需要建立相应的规范和监管机制。
未来,大模型的发展可能会朝以下方向演进:
-
多模态融合:将语言、视觉、音频等多种模态统一到一个框架中。
-
知识注入:将结构化知识更好地融入到大模型中,提升推理能力。
-
高效训练:探索更高效的模型结构和训练方法,降低资源消耗。
-
可控生成:提升模型输出的可控性和一致性,使之更加可靠。
-
与传统方法结合:探索大模型与神经符号推理等方法的结合。
-
隐私保护:研究如何在保护数据隐私的前提下训练和使用大模型。
结语
大模型的出现掀开了人工智能发展的新篇章,为我们展现了AI的无限可能。虽然目前大模型还存在诸多问题和挑战,但随着技术的不断进步和各方的共同努力,相信大模型终将成为推动人类社会进步的强大工具。在这个激动人心的大模型时代,每个人都有机会参与其中,共同塑造AI的未来。
让我们拭目以待,见证人工智能在大模型的推动下继续演进、发展,最终造福人类社会。










