
创新的端到端中文车牌识别系统
在当今快速发展的智能交通领域,车牌识别技术扮演着越来越重要的角色。然而,由于复杂的环境因素和车牌本身的多样性,实现高精度的车牌识别仍然面临诸多挑战。针对这一问题,GitHub上的开源项目"End-to-end-for-chinese-plate-recognition"提出了一种创新的解决方案,将深度学习与传统计算机视觉技术相结合,实现了端到端的中文车牌定位、矫正和识别。
系统架构与技术路线
该项目采用了三阶段的处理流程,巧妙地融合了U-Net、OpenCV和CNN三种技术:
-
U-Net图像分割:利用U-Net深度学习网络对输入图像进行语义分割,得到车牌区域的二值化图像。U-Net的多尺度特征提取和上采样结构使其能够精确地定位车牌位置。
-
OpenCV边缘检测与矫正:基于U-Net输出的二值图,使用OpenCV库进行边缘检测,获取车牌的精确轮廓和坐标。随后对倾斜的车牌进行透视变换,实现车牌图像的矫正。
-
CNN多标签识别:将矫正后的车牌图像输入到预训练的CNN模型中,实现对车牌字符的端到端识别。CNN模型采用多标签分类的方式,可以同时识别出车牌中的所有字符。
这种多阶段的处理流程充分发挥了各种技术的优势:U-Net擅长语义分割,可以有效应对复杂背景;OpenCV提供了丰富的图像处理算法,能够精确定位和矫正车牌;而CNN则在字符识别任务中表现出色。三者的结合使得系统具备了强大的环境适应性和识别准确性。
环境配置与实现细节
项目基于Python 3.6环境开发,主要依赖包括:
- TensorFlow 1.15.2
- OpenCV 4.1.0.25
- Keras 2.3.1
这些版本的选择既保证了系统的稳定性,又能充分利用深度学习框架的优势。开发者可以通过项目提供的requirements.txt文件快速搭建开发环境。
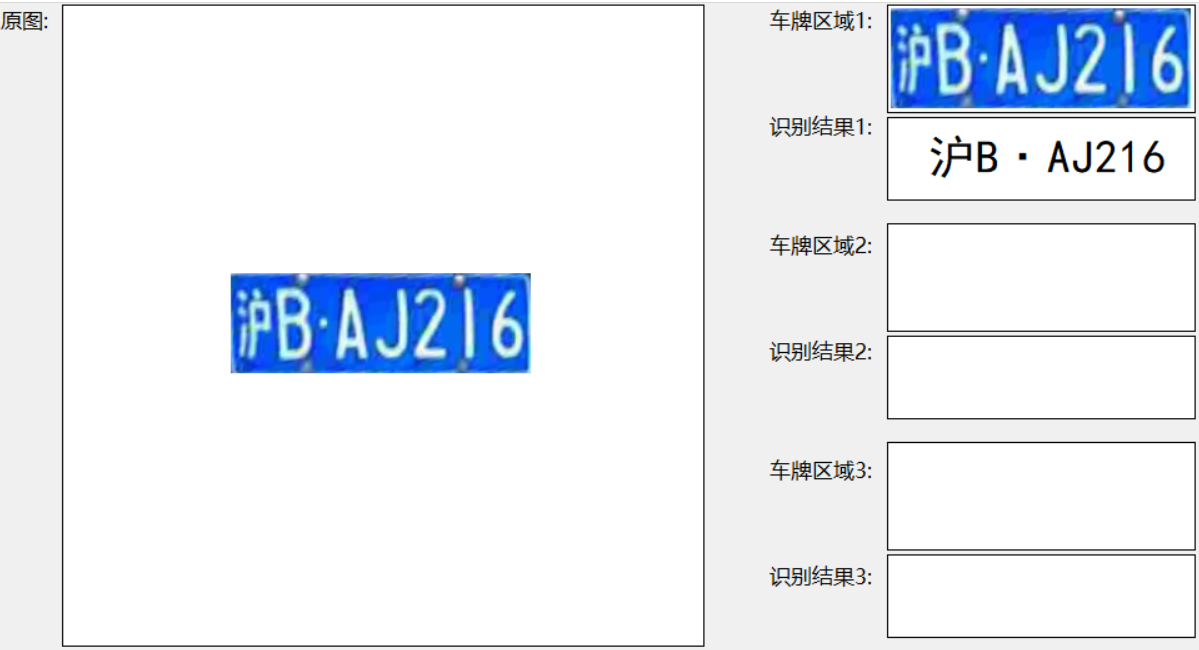
在实际应用中,系统展现出了优秀的性能。即使在拍摄角度倾斜、强曝光或昏暗等复杂环境下,也能较好地完成车牌识别任务。有趣的是,项目作者提到,该系统甚至能够识别出一些百度AI车牌识别API无法处理的图片,这充分证明了其强大的环境适应能力。
使用注意事项
尽管系统具有较强的鲁棒性,但在使用时仍需注意一些细节:
-
对于已经裁剪好的完整车牌图像,建议将尺寸控制在240*80像素以内。这是因为系统会自动判断是否需要进行车牌定位,过大的图像可能会被误判为包含其他区域,从而影响识别效果。
-
系统默认处理的是标准蓝白色车牌。对于其他类型的车牌(如新能源车牌),可能需要额外的训练数据和模型调整。
-
在实际部署时,需要考虑计算资源的限制。虽然端到端的处理方式提高了系统的集成度,但也可能增加了单次识别的计算量。在资源受限的环境中,可能需要对模型进行进一步的优化和压缩。
未来展望与改进方向
尽管该项目已经取得了显著的成果,但车牌识别技术仍有很大的发展空间。以下是一些潜在的改进方向:
-
模型轻量化:考虑采用MobileNet等轻量级网络结构,以适应移动设备等计算资源受限的场景。
-
多类型车牌支持:扩展训练数据集,使系统能够识别新能源车牌、警车车牌等特殊类型。
-
视频流处理:优化算法以支持实时视频流中的车牌检测和识别,这对于智能交通系统尤为重要。
-
多国车牌适配:考虑将系统扩展到其他国家的车牌识别,这需要针对不同国家的车牌特点进行模型调整。
-
引入注意力机制:在CNN识别阶段引入注意力机制,可能进一步提高对复杂或模糊字符的识别准确率。

结语
"End-to-end-for-chinese-plate-recognition"项目为中文车牌识别提供了一种创新的端到端解决方案。通过结合U-Net、OpenCV和CNN,该系统成功地应对了车牌识别中的诸多挑战。这种方法不仅在学术上具有创新性,也为实际应用提供了宝贵的参考。随着深度学习技术的不断发展和更多实际应用数据的积累,我们有理由相信,车牌识别技术将在不久的将来实现质的飞跃,为智能交通和城市管理带来更多可能性。
对于有志于研究计算机视觉和深度学习的开发者来说,这个项目无疑是一个很好的学习资源。它不仅展示了如何将不同的技术有机结合,还提供了详细的代码实现和测试样例。通过深入研究这个项目,开发者可以加深对图像处理、深度学习和车牌识别领域的理解,为今后的研究和实践打下坚实基础。
最后,值得一提的是,这个项目采用了Apache 2.0许可证,这意味着它可以被自由地使用、修改和分发。这种开放的态度不仅有利于技术的传播和改进,也为整个计算机视觉社区的发展做出了贡献。我们期待看到更多基于这个项目的创新应用和改进方案,共同推动车牌识别技术的进步。









