
External-Attention-pytorch:功能强大的注意力机制工具库
在深度学习领域,注意力机制已经成为一种非常重要的技术,被广泛应用于计算机视觉、自然语言处理等多个方向。External-Attention-pytorch是一个基于PyTorch实现的注意力机制工具库,包含了多种最新的注意力模块和视觉backbone网络的实现,为深度学习研究者和工程师提供了便捷的工具。
项目概览
External-Attention-pytorch项目由GitHub用户xmu-xiaoma666创建和维护。该项目的主要目标是实现一个既能让深度学习初学者容易理解,又能服务于科研和工业界的代码库。项目包含了多个系列的实现:
-
Attention Series: 包括External Attention、Self Attention、Squeeze-and-Excitation Attention等多种注意力机制的实现。
-
Backbone Series: 包括ResNet、MobileViT、ConvMixer等多种视觉backbone网络的实现。
-
MLP Series: 包括RepMLP、MLP-Mixer等多种MLP结构的实现。
-
Re-Parameter Series: 包括RepVGG、ACNet等重参数化方法的实现。
-
Convolution Series: 包括深度可分离卷积、MBConv等特殊卷积结构的实现。
主要特点
-
实现全面: 包含了多种最新的注意力机制和视觉backbone网络,覆盖面广。
-
代码简洁: 每个模块的实现都非常精简,便于理解和使用。
-
使用方便: 提供了详细的使用说明和示例代码,上手容易。
-
持续更新: 项目一直在积极维护和更新,不断加入最新的模型实现。
使用方法
External-Attention-pytorch提供了两种使用方式:
- 通过pip安装:
pip install fightingcv-attention
- 直接克隆GitHub仓库:
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch
使用示例:
import torch
from fightingcv_attention.attention.MobileViTv2Attention import *
input = torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output = sa(input)
print(output.shape)
主要模块介绍
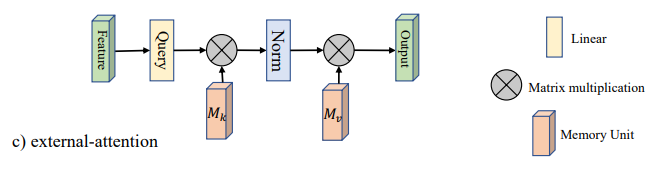
1. External Attention
External Attention是一种新型的注意力机制,由论文"Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"提出。相比于传统的Self Attention,External Attention引入了外部记忆单元,可以更好地捕捉全局上下文信息。
使用示例:
from model.attention.ExternalAttention import ExternalAttention
import torch
input = torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output = ea(input)
print(output.shape)
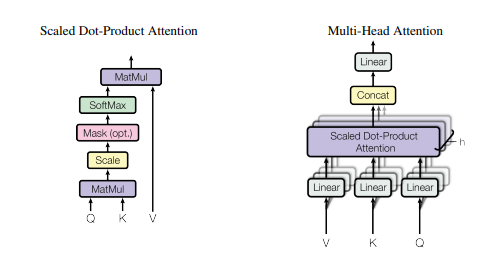
2. Self Attention
Self Attention是Transformer中的核心组件,在多个领域都取得了巨大成功。项目中实现了标准的Self Attention和简化版本的Self Attention。
使用示例:
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input = torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output = sa(input,input,input)
print(output.shape)
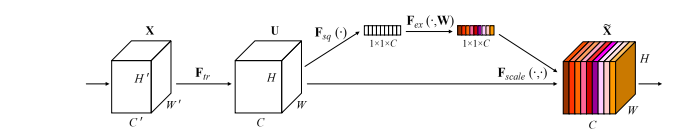
3. Squeeze-and-Excitation Attention
Squeeze-and-Excitation (SE) Attention是一种轻量级的注意力机制,通过显式建模通道间的相互依赖关系来提高网络的表示能力。
使用示例:
from model.attention.SEAttention import SEAttention
import torch
input = torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output = se(input)
print(output.shape)
总结
External-Attention-pytorch提供了丰富的注意力机制和视觉backbone网络实现,是一个非常有价值的工具库。无论是深度学习初学者还是经验丰富的研究者,都可以从中受益。该项目不仅可以帮助我们更好地理解和使用各种注意力机制,还可以作为实验的基础代码,为进一步的研究和开发提供支持。
随着深度学习技术的不断发展,注意力机制必将在未来扮演更加重要的角色。External-Attention-pytorch项目的持续更新和维护,将为研究者们提供一个宝贵的资源,帮助他们更好地探索和创新。我们期待看到更多基于这个项目的研究成果和应用实践。
如果你对注意力机制感兴趣,不妨尝试使用External-Attention-pytorch,相信它会给你的研究和开发带来便利和启发。同时,也欢迎更多的开发者参与到项目的贡献中来,共同推动这个优秀工具库的发展。
GitHub项目地址: https://github.com/xmu-xiaoma666/External-Attention-pytorch
让我们一起探索注意力机制的无限可能吧! 🚀🚀🚀









