
FastDiff: 革新语音合成的快速条件扩散模型
近年来,深度学习技术在语音合成领域取得了长足的进步。其中,基于扩散概率模型的方法因其优异的生成质量而备受关注。然而,传统扩散模型的推理速度较慢,限制了其在实际应用中的大规模部署。针对这一问题,来自浙江大学和腾讯AI实验室的研究团队提出了FastDiff,这是一种新型的快速条件扩散模型,旨在实现高质量语音合成的同时大幅提升推理速度。
FastDiff的核心创新
FastDiff的核心创新在于其独特的网络架构设计。研究人员采用了一种堆叠的时间感知位置可变卷积结构,具有多样化的感受野模式。这种设计能够高效地建模长期时间依赖关系,同时适应不同的条件输入。与传统扩散模型相比,FastDiff显著减少了所需的去噪步骤,从而实现了快速推理。
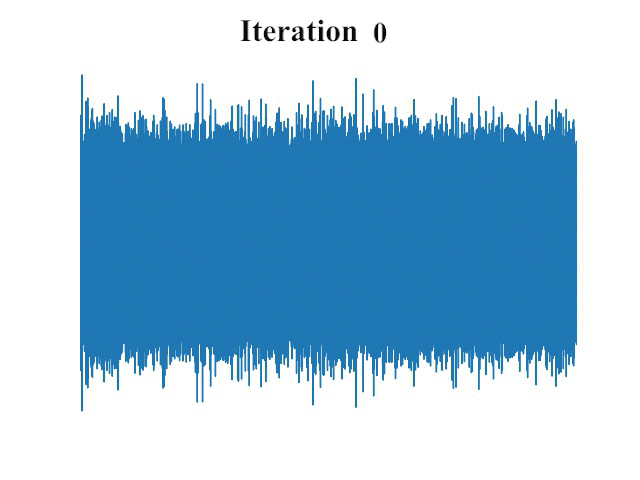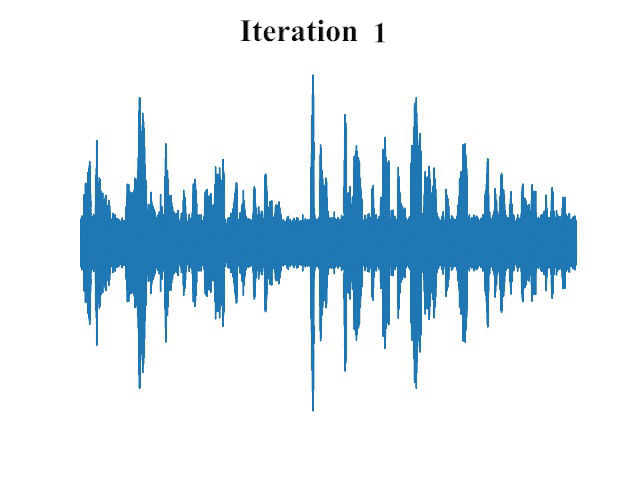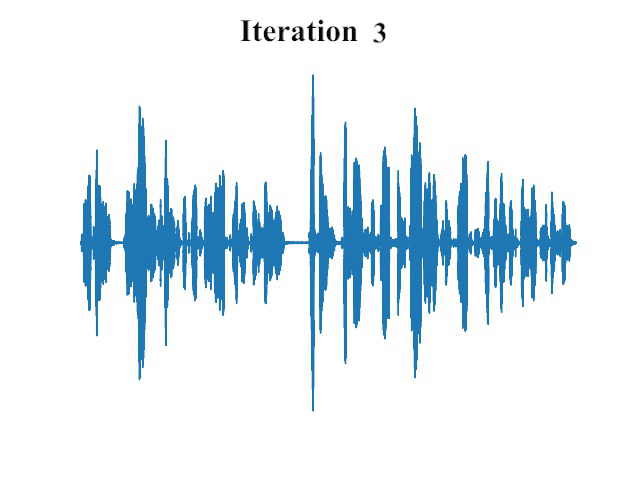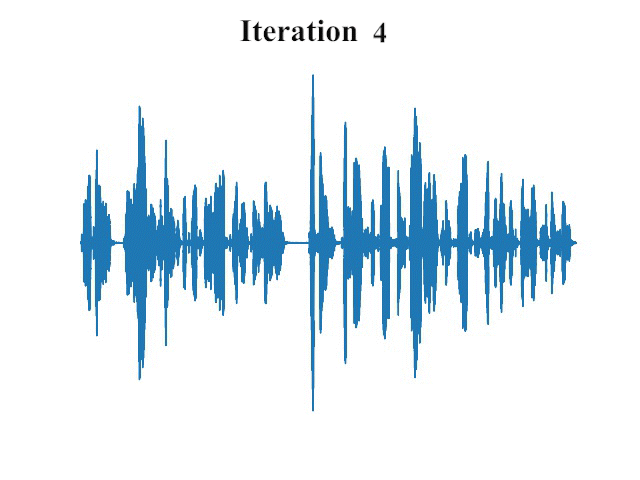
卓越的性能表现
实验结果表明,FastDiff在多个公开数据集上都取得了令人瞩目的性能。在LJSpeech、LibriTTS和VCTK等基准数据集上,FastDiff生成的语音样本在自然度和音质方面均达到了很高的水平。更重要的是,FastDiff仅需4步采样就能生成高质量语音,这意味着其推理速度比传统扩散模型快出数十倍甚至上百倍。
广泛的应用前景
FastDiff的出色性能使其在多个语音合成场景中具有广阔的应用前景:
-
文本转语音(TTS): FastDiff可以与各种声学模型(如Tacotron、FastSpeech等)结合,实现端到端的高质量TTS系统。
-
语音转换: 通过条件控制,FastDiff可以实现说话人风格转换、情感转换等语音转换任务。
-
语音修复: FastDiff的去噪能力使其能够有效地去除语音中的噪声,实现语音增强和修复。
-
多语言语音合成: FastDiff的灵活性使其易于扩展到多语言场景,为全球化应用提供支持。
开源与社区贡献
为了推动语音合成技术的进步,研究团队将FastDiff的实现代码和预训练模型以开源形式公开。这不仅方便了其他研究者复现结果和进行进一步的改进,也为工业界的应用提供了便利。
FastDiff的GitHub仓库(https://github.com/Rongjiehuang/FastDiff)提供了详细的使用说明,包括环境配置、数据准备、模型训练和推理等步骤。研究者们还在Hugging Face平台上提供了在线演示(https://huggingface.co/spaces/Rongjiehuang/ProDiff),让用户可以直接体验FastDiff的语音合成效果。
持续的技术演进
FastDiff的成功激发了研究团队进一步探索更高效的语音合成方法。他们随后提出了ProDiff,这是FastDiff的改进版本,进一步优化了速度和质量之间的平衡。这表明,基于扩散模型的语音合成技术仍有巨大的发展空间。
结语
FastDiff的提出标志着语音合成技术进入了一个新的阶段。它不仅在理论上提出了创新的模型结构,而且在实践中展现了卓越的性能。随着FastDiff及其衍生技术的不断发展和应用,我们可以期待在不久的将来,更加自然、高效的语音交互系统将成为现实,为人机交互带来革命性的变革。
FastDiff的成功也为扩散模型在其他领域的应用提供了启发。其快速推理的方法可能被应用到图像生成、视频合成等其他生成任务中,推动整个生成式AI领域的进步。
值得注意的是,尽管FastDiff在技术上取得了巨大突破,但在实际应用中仍需谨慎考虑伦理和法律问题。研究团队特别强调,禁止任何组织或个人未经同意使用该技术生成他人的语音,特别是政府领导人、政治人物和名人的语音。这一声明反映了研究者们对技术伦理的重视,也为该技术的负责任使用提供了指导。
总的来说,FastDiff为高质量、高效率的语音合成开辟了新的道路。随着技术的不断完善和应用范围的扩大,我们可以期待看到更多基于FastDiff的创新应用,推动语音技术和人工智能领域的持续发展。









