
FastSpeech2简介
FastSpeech2是微软提出的一个快速、高质量的端到端文本转语音(TTS)模型,是FastSpeech的改进版本。相比于传统的自回归TTS模型,FastSpeech2具有以下优势:
- 生成速度快:非自回归并行生成,推理速度比自回归模型快约50倍
- 语音质量高:引入了更多语音变化信息,如音高、能量等,生成的语音质量可与自回归模型相媲美
- 可控性强:可以精确控制语音的持续时间、音高、能量等属性
- 训练简单:采用端到端训练,无需复杂的教师-学生蒸馏过程
FastSpeech2的核心思想是引入变分适配器(Variance Adaptor),在训练时直接从真实语音中提取持续时间、音高、能量等信息作为条件输入,在推理时则使用预测值。这种方法既简化了训练过程,又提高了生成语音的质量和可控性。
FastSpeech2架构
FastSpeech2的整体架构如下图所示:
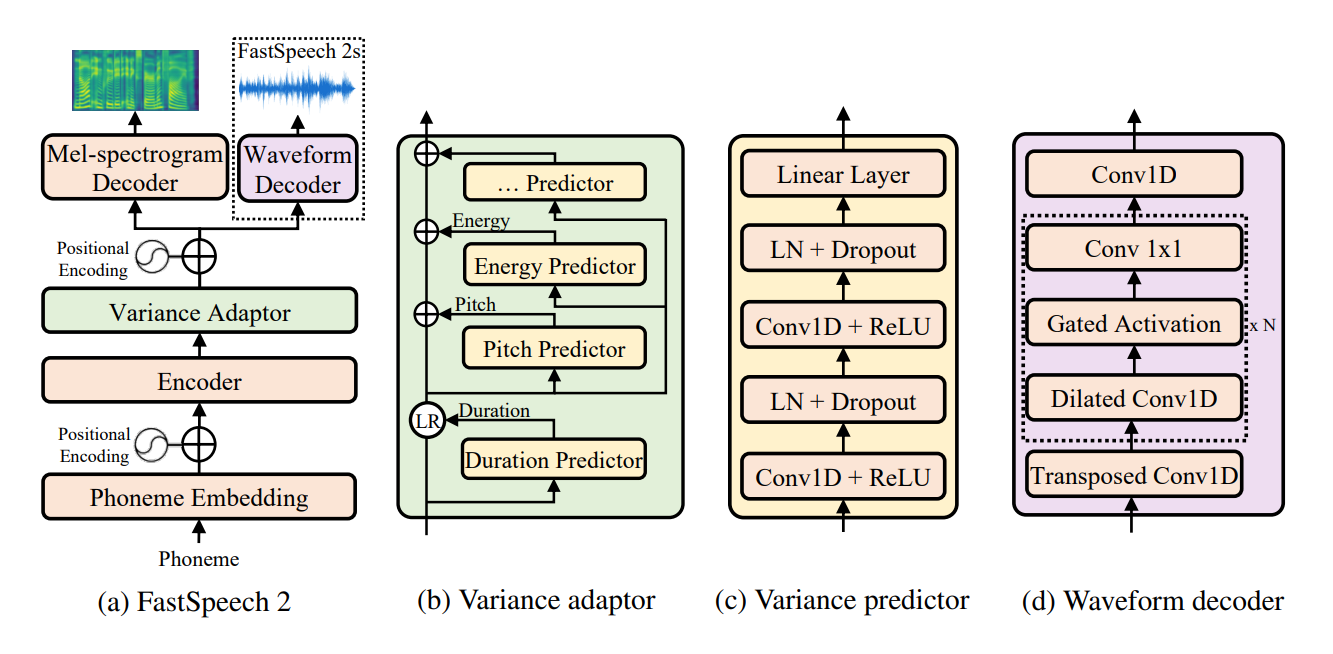
主要包括以下几个部分:
- 音素编码器:将输入文本转换为音素序列,并编码为隐藏序列
- 变分适配器:添加持续时间、音高、能量等变化信息
- 梅尔谱图解码器:将隐藏序列转换为梅尔谱图
- 声码器:将梅尔谱图转换为波形
其中变分适配器是FastSpeech2的核心创新,包含持续时间预测器、音高预测器和能量预测器。
如何学习FastSpeech2
-
阅读论文:从FastSpeech 2: Fast and High-Quality End-to-End Text to Speech开始,理解模型的基本原理
-
查看代码实现:可以参考rishikksh20/FastSpeech2这个非官方PyTorch实现
-
运行Demo:使用提供的Colab Notebook快速体验模型效果
-
准备环境:
pip install torch torchvision pip install -r requirements.txt -
数据预处理:
python nvidia_preprocessing.py -d path_of_wavs python compute_statistics.py -
模型训练:
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name" -
推理生成:
python inference.py -c configs/default.yaml -p checkpoints/model.pyt --text "Your text here" -
进阶学习:尝试修改模型结构,调整超参数,在更多数据集上训练等
相关资源
通过以上学习路径和资源,相信大家可以快速入门FastSpeech2,并在此基础上进行更多探索。欢迎在评论区分享你的学习心得!










