
FollowYourPose:基于无姿势视频的姿势引导文本到视频生成
FollowYourPose是由香港科技大学和腾讯AI Lab的研究人员共同开发的一个创新性文本到视频生成框架。该项目旨在解决生成可文本编辑和姿势可控的角色视频这一具有迫切需求的任务。
项目背景
生成可文本编辑和姿势可控的角色视频在创建各种数字人物方面具有广泛的应用前景。然而,这项任务长期以来受到两个主要限制:
- 缺乏包含配对视频-姿势描述的综合数据集
- 缺乏针对视频的生成先验模型
为了克服这些限制,FollowYourPose项目提出了一种新颖的两阶段训练方案,可以充分利用易于获取的数据集(如图像-姿势对和无姿势视频)以及预训练的文本到图像(T2I)模型,来实现姿势可控的角色视频生成。
技术方法
FollowYourPose的训练过程分为两个主要阶段:
-
第一阶段:仅使用关键点-图像对进行可控的文本到图像生成。研究人员设计了一个零初始化的卷积编码器来编码姿势信息。
-
第二阶段:通过添加可学习的时间自注意力和改进的跨帧自注意力模块,使用无姿势视频数据集对上述网络的运动进行微调。
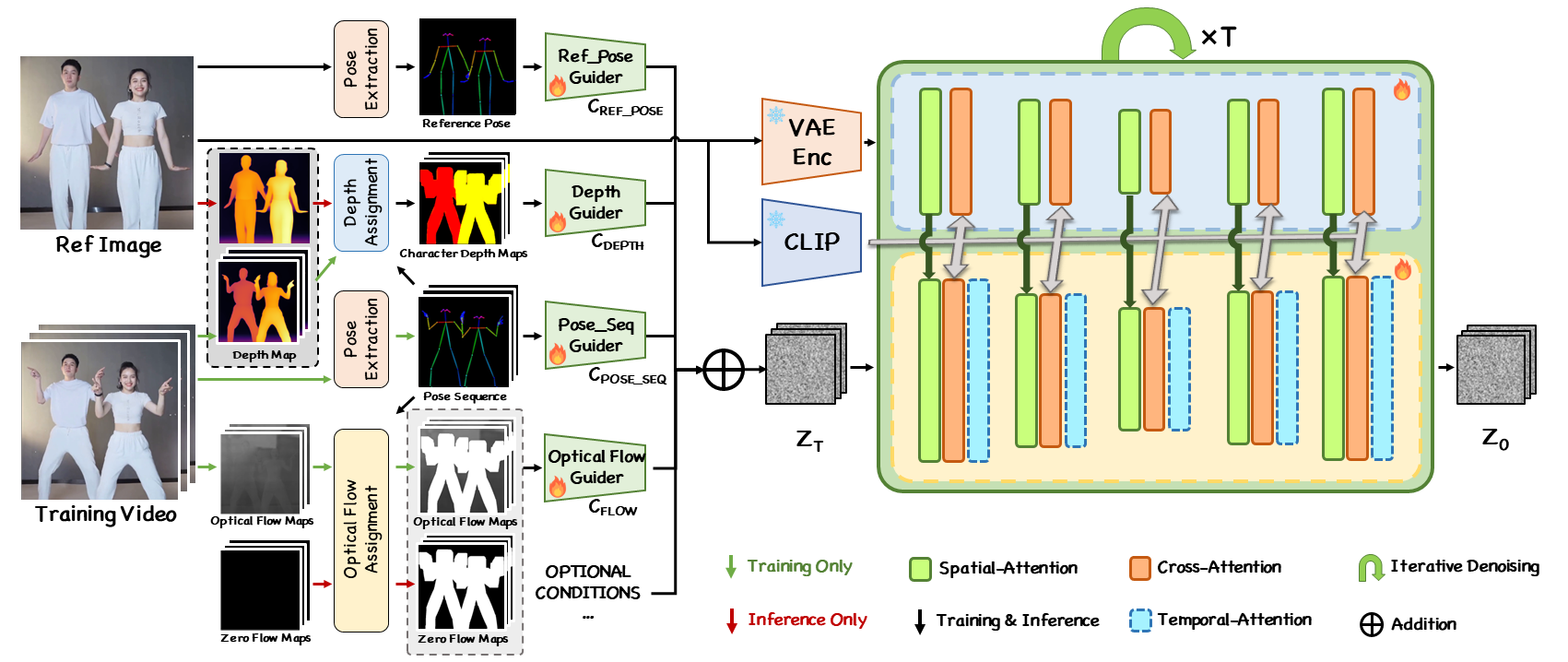
这种创新的设计使得FollowYourPose能够成功生成连续可控的姿势引导角色视频,同时保留预训练T2I模型的编辑和概念组合能力。
主要特点
FollowYourPose具有以下几个显著特点:
-
无需配对数据:该方法可以利用易获得的图像-姿势对和无姿势视频数据集进行训练,避免了收集大规模配对视频-姿势描述数据集的困难。
-
灵活的姿势控制:通过输入不同的姿势序列,可以灵活控制生成视频中角色的动作。
-
文本引导生成:支持使用自然语言描述来指定生成视频的场景、角色特征等内容。
-
保留预训练模型能力:该方法保留了预训练T2I模型的编辑和概念组合能力,可以生成多样化的视频内容。
-
连续稳定的生成:能够生成连续流畅、姿势稳定的视频序列。
应用示例
FollowYourPose可以应用于多种场景,以下是一些典型示例:
- 动画角色生成:

描述:"宇航员,地球背景,卡通风格"
- 真实人物动作生成:

描述:"特朗普,在山上"
- 虚构角色生成:

描述:"钢铁侠,在街道上"
- 艺术风格化生成:

描述:"公园里的男人,梵高风格"
这些示例展示了FollowYourPose在生成多样化、富有创意的姿势引导视频方面的强大能力。
技术实现
FollowYourPose的实现基于以下主要技术组件:
-
预训练T2I模型:使用Stable Diffusion v1-4作为基础模型。
-
姿势编码器:设计了一个专门的卷积编码器来处理姿势信息。
-
时间自注意力模块:用于捕捉视频帧之间的时序关系。
-
改进的跨帧自注意力:增强了模型对长序列视频生成的能力。
-
加速器和XFormers:利用这些工具来优化训练过程,提高效率。
项目代码主要使用PyTorch实现,并提供了详细的训练和推理脚本。研究人员还开发了基于Gradio的演示界面,方便用户直观体验FollowYourPose的功能。
未来展望
尽管FollowYourPose已经展现出令人印象深刻的性能,但该领域仍有巨大的发展潜力。未来的研究方向可能包括:
- 提高生成视频的分辨率和帧率
- 增强对复杂动作和多人场景的处理能力
- 整合音频生成,实现多模态的视频内容创作
- 探索在更大规模数据集上的预训练,以增强模型的泛化能力
- 研究如何更好地保持角色的一致性,特别是在长视频序列中
FollowYourPose为姿势引导的文本到视频生成开辟了新的研究方向,为数字内容创作提供了强大的工具。随着技术的不断进步,我们可以期待看到更多令人兴奋的应用在未来涌现。
总结
FollowYourPose提出了一种创新的两阶段训练方案,成功实现了基于易获得数据集的姿势可控角色视频生成。该方法不仅解决了数据集和先验模型缺乏的问题,还保留了预训练模型的强大能力。通过灵活的姿势控制和文本引导,FollowYourPose为数字内容创作者提供了一个强大而富有创意的工具,有望在动画制作、虚拟现实、数字娱乐等多个领域发挥重要作用。
随着该技术的不断发展和完善,我们可以期待看到更多令人惊叹的应用案例,推动视频生成技术向着更高水平迈进。FollowYourPose无疑为人工智能驱动的创意内容生成开辟了新的可能性,让我们拭目以待它在未来会带来怎样的惊喜。









