GGML: 让AI在边缘设备上腾飞
在人工智能和大语言模型快速发展的今天,如何让这些强大的模型在普通的消费级设备上高效运行,成为了一个重要的挑战。GGML(General-purpose Graph Machine Learning)作为一个专注于这一目标的开源张量库,正在为解决这个问题做出重要贡献。
GGML的特点和优势
GGML是由Georgi Gerganov开发的一个用C语言编写的机器学习张量库。它具有以下几个主要特点:
- 使用C语言编写,具有极高的性能和可移植性
- 支持16位浮点数运算
- 支持整数量化(4-bit, 5-bit, 8-bit等)
- 支持自动微分
- 内置ADAM和L-BFGS优化器
- 针对Apple Silicon进行了优化
- 在x86架构上利用AVX/AVX2指令集
- 无第三方依赖
- 运行时零内存分配
这些特点使得GGML非常适合在资源受限的边缘设备上运行大型语言模型。它的设计理念是简洁、开放和灵活,鼓励开发者探索新的想法,构建有趣的演示,并推动边缘AI的可能性边界。
GGML的应用
GGML已经被广泛应用于多个知名的开源项目中,包括:
- llama.cpp: 在CPU上高效运行Meta的LLaMA大语言模型
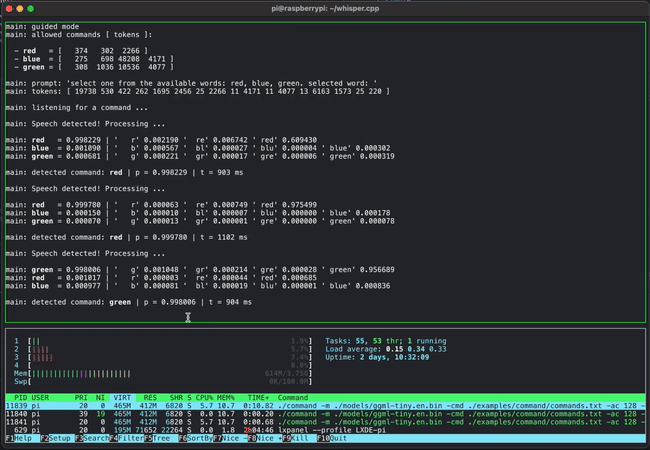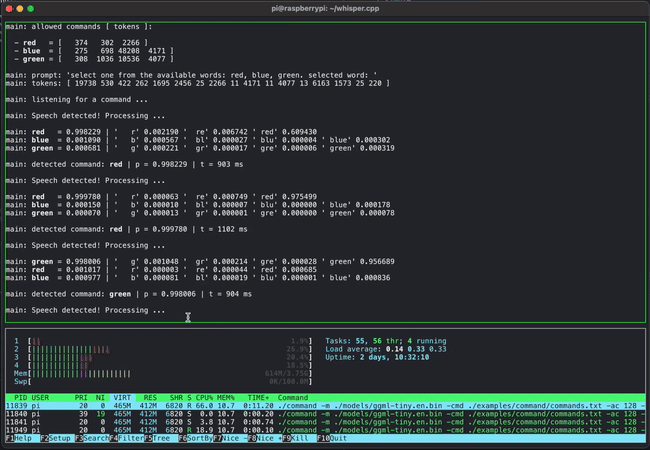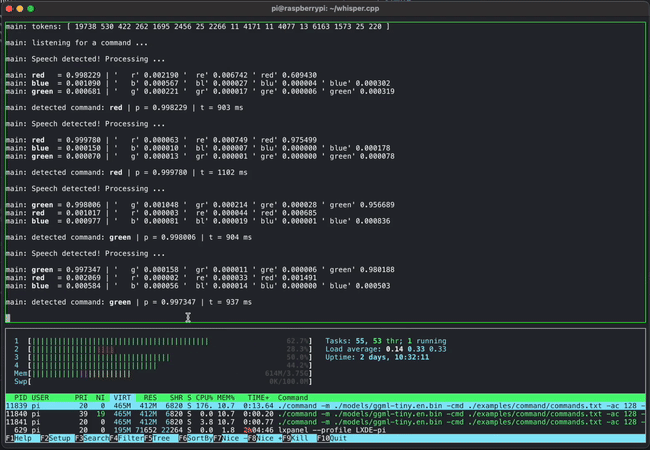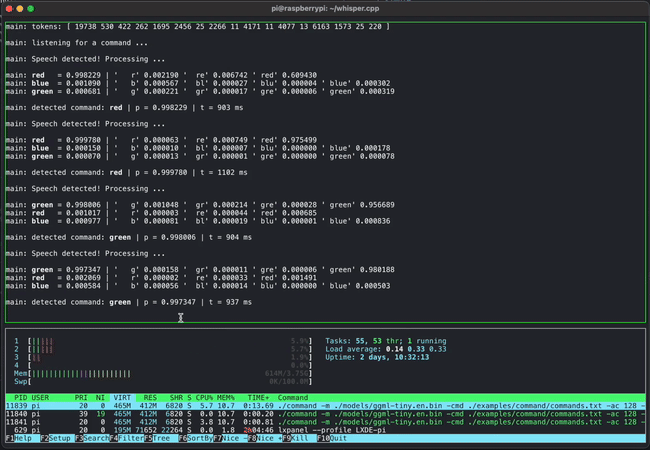
- whisper.cpp: OpenAI的Whisper语音识别模型的高性能C/C++实现
除此之外,GGML还支持多种其他模型的推理,如GPT-2、GPT-J、BLOOM、RWKV、SAM、BERT等。这种广泛的应用证明了GGML在实现大型语言模型本地化方面的强大能力。
GGML的工作原理
GGML的核心是一个高效的张量计算库。它通过以下几个关键概念来组织计算:
- ggml_context: 一个"容器",用于存储张量、计算图和可选数据
- ggml_cgraph: 表示计算图,定义了将传输到后端的"计算顺序"
- ggml_backend: 执行计算图的接口,支持CPU(默认)、CUDA、Metal(Apple Silicon)、Vulkan等多种后端
- ggml_backend_buffer_type: 表示缓冲区类型,作为每个
ggml_backend的"内存分配器" - ggml_backend_buffer: 由
buffer_type分配的缓冲区 - ggml_gallocr: 图形内存分配器,用于高效分配计算图中使用的张量
这种设计允许GGML在不同的硬件平台上高效地执行大型语言模型的推理,同时保持较低的内存占用。
使用GGML
要开始使用GGML,你可以按照以下步骤操作:
-
克隆GGML仓库:
git clone https://github.com/ggerganov/ggml cd ggml -
创建并激活Python虚拟环境:
python3.10 -m venv ggml_env source ./ggml_env/bin/activate pip install -r requirements.txt -
编译示例:
mkdir build && cd build cmake .. cmake --build . --config Release -j 8 -
运行GPT-2示例:
../examples/gpt-2/download-ggml-model.sh 117M ./bin/gpt-2-backend -m models/gpt-2-117M/ggml-model.bin -p "This is an example"
GGML还支持在多种硬件上运行,包括使用Metal在Mac上的GPU加速,以及在支持CUDA的GPU上运行。
GGML的未来发展
GGML项目正处于活跃开发阶段,其部分开发工作目前正在llama.cpp和whisper.cpp等仓库中进行。项目的路线图和宣言可以在GitHub项目页面上找到。
随着边缘AI的重要性不断增加,GGML有望在未来发挥更大的作用。它为开发者提供了一个强大的工具,使他们能够将复杂的AI模型带到资源受限的设备上,从而开启了新的应用可能性。
结语
GGML作为一个专注于边缘AI的开源张量库,正在为大型语言模型的普及做出重要贡献。它的高效、灵活和可移植性使得在普通硬件上运行复杂AI模型成为可能。随着更多开发者加入GGML社区,我们可以期待看到更多创新的边缘AI应用在未来涌现。无论你是AI研究者、应用开发者还是对边缘计算感兴趣的技术爱好者,GGML都值得你去探索和尝试。
让我们共同期待GGML为AI的未来带来更多可能性!