
Grounding DINO简介
Grounding DINO是由IDEA Research团队开发的一种开创性的开放集目标检测模型。它巧妙地结合了DINO (Detection Transformer)和基于语言的预训练技术,实现了使用自然语言来检测图像中的任意物体。这种方法打破了传统目标检测只能识别预定义类别的限制,为计算机视觉领域带来了新的可能性。
Grounding DINO的核心特点
-
开放集检测能力: 利用语言的灵活性,Grounding DINO可以检测任何可以用语言描述的物体,而不局限于预定义的类别。
-
高性能: 在COCO数据集上,Grounding DINO展现了卓越的性能。零样本情况下达到52.5 AP,微调后更是高达63.0 AP。
-
灵活性: 可以与Stable Diffusion等图像编辑技术结合,实现更丰富的应用。
-
多模态融合: 模型包含文本主干网络、图像主干网络、特征增强器、语言引导的查询选择和跨模态解码器,实现了文本和图像的深度融合。
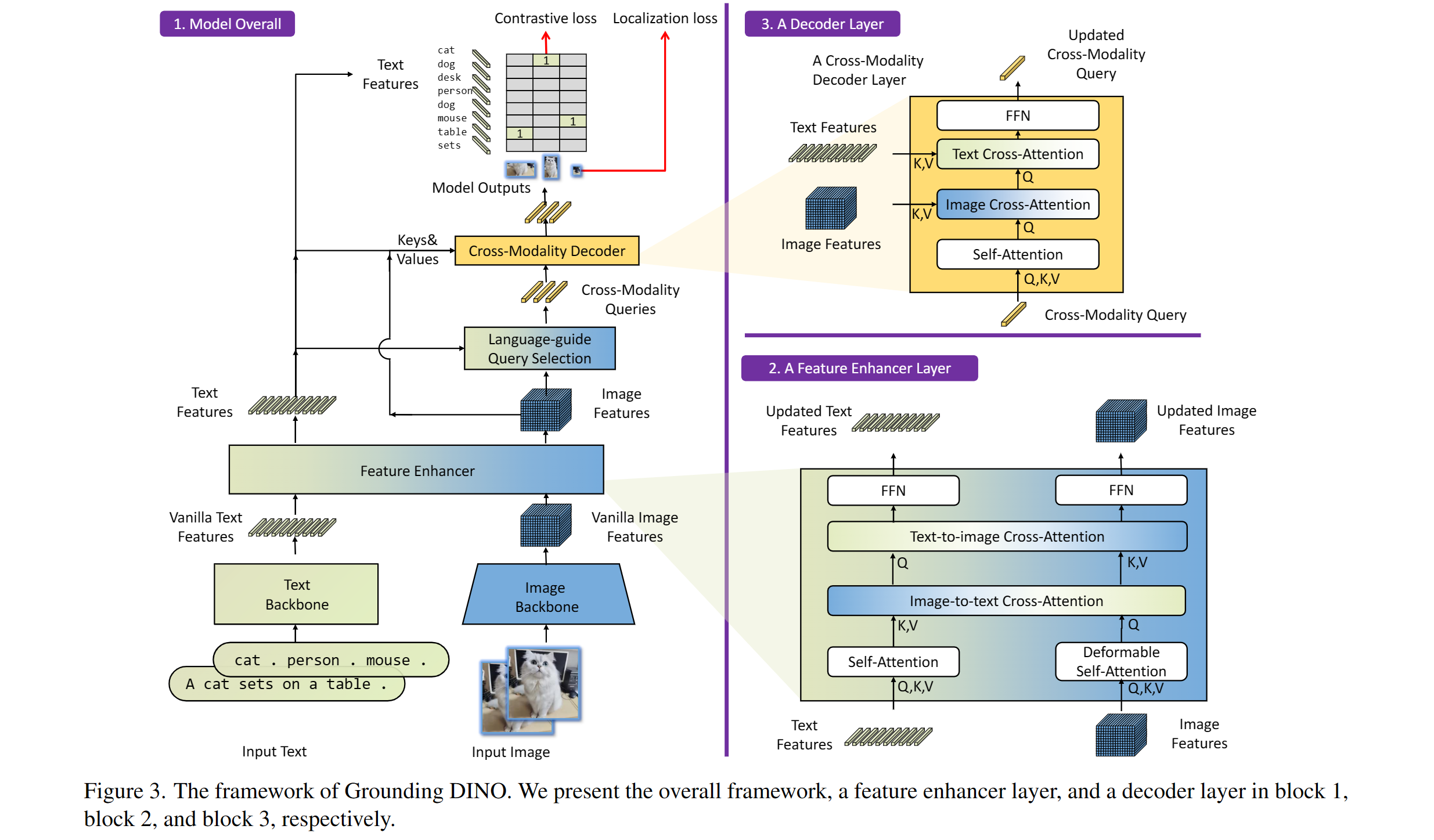
Grounding DINO的技术原理
Grounding DINO的核心思想是将DINO (Detection Transformer)与基于语言的预训练相结合。这种创新的方法使得模型能够理解和利用自然语言指令来进行目标检测。
主要组成部分
-
文本主干网络: 负责处理输入的文本描述,提取语言特征。
-
图像主干网络: 提取输入图像的视觉特征。
-
特征增强器: 进一步提升提取到的特征的表达能力。
-
语言引导的查询选择: 根据语言描述选择相关的查询,提高检测的针对性。
-
跨模态解码器: 融合文本和图像信息,输出最终的检测结果。
这种架构设计使得Grounding DINO能够有效地将语言理解与视觉检测相结合,实现开放集目标检测。
Grounding DINO的最新进展
Grounding DINO项目一直在快速发展,不断推出新的功能和改进。以下是一些最新的进展:
-
Grounded SAM 2: 结合了Grounding DINO和SAM 2 (Segment Anything Model 2),实现了开放世界场景中的任意物体跟踪。
-
Grounding DINO 1.5: IDEA Research推出的最新版本,是目前最强大的开放世界目标检测模型。
-
Hugging Face支持: Grounding DINO和Grounded SAM现已在Hugging Face上得到支持,方便用户使用。
-
与其他技术的结合:
- 与Stable Diffusion结合,用于图像编辑
- 与GLIGEN结合,实现更可控的图像编辑
- 与Segment-Anything结合,支持GroundingDINO中的分割功能
这些进展显示了Grounding DINO在实际应用和与其他技术融合方面的巨大潜力。
Grounding DINO的应用示例
Grounding DINO的灵活性和强大功能使其在多个领域都有广泛的应用前景。以下是一些具体的应用示例:
-
零样本目标检测: Grounding DINO可以检测训练时未见过的物体类别,只需通过文本描述即可。这在处理新出现的物体或罕见物体时特别有用。
from groundingdino.util.inference import load_model, load_image, predict, annotate import cv2 model = load_model("groundingdino/config/GroundingDINO_SwinT_OGC.py", "weights/groundingdino_swint_ogc.pth") IMAGE_PATH = "path_to_your_image.jpg" TEXT_PROMPT = "a rare tropical flower . a colorful bird" image_source, image = load_image(IMAGE_PATH) boxes, logits, phrases = predict(model, image, TEXT_PROMPT, box_threshold=0.35, text_threshold=0.25) annotated_frame = annotate(image_source, boxes, logits, phrases) cv2.imwrite("result.jpg", annotated_frame) -
图像编辑与操作: 结合Stable Diffusion或GLIGEN,Grounding DINO可以实现精确的图像编辑。
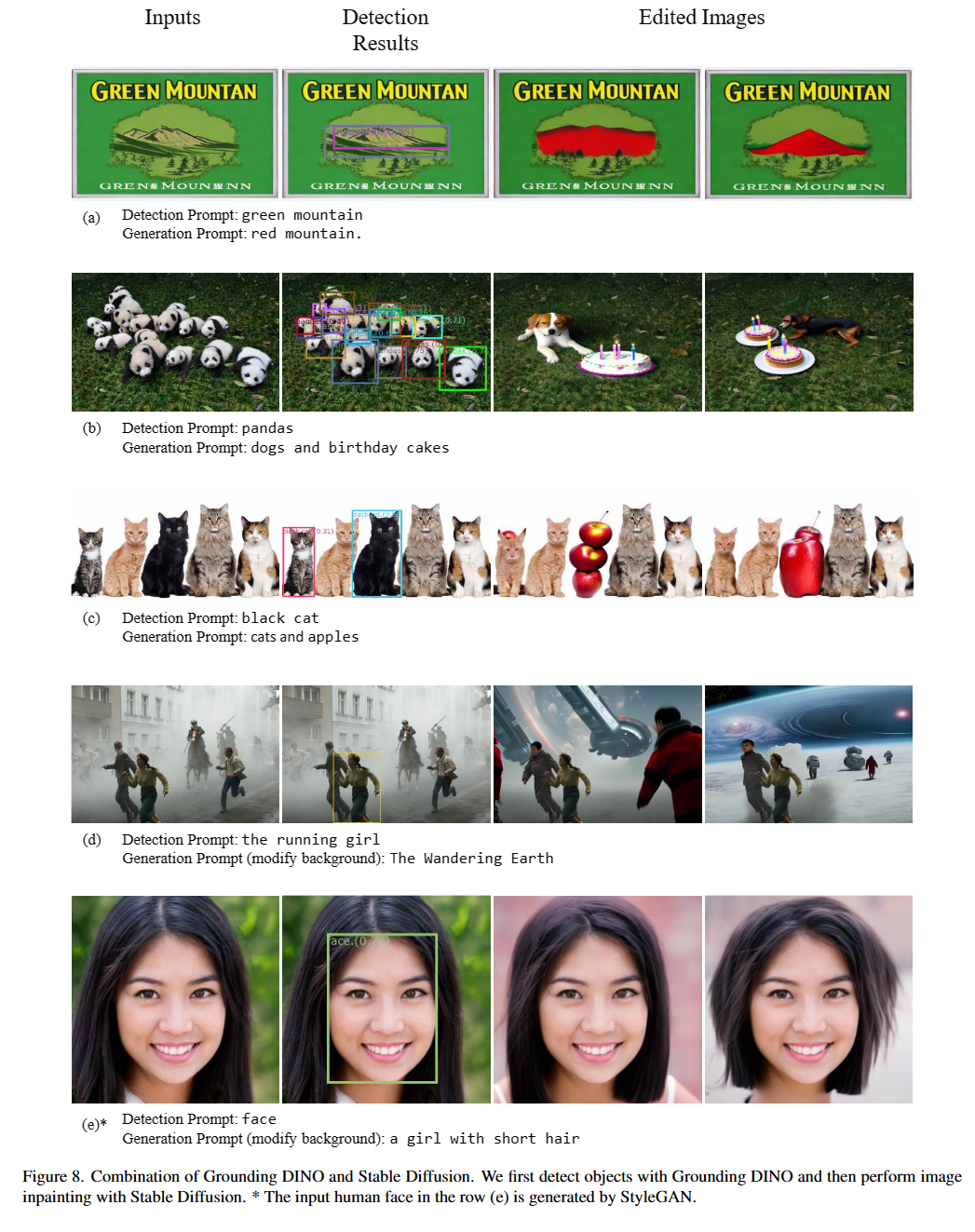
-
自动数据集标注: Grounding DINO可以用于自动标注大规模图像数据集,大大减少人工标注的工作量。
-
视觉问答系统: 结合大型语言模型,Grounding DINO可以用于构建高级的视觉问答系统,理解并回答关于图像内容的复杂问题。
-
医疗图像分析: 在医疗领域,Grounding DINO可以协助医生识别X光片或CT扫描中的异常情况,提高诊断效率和准确性。
-
安防监控: 在安防系统中,Grounding DINO可以实现更灵活的目标检测和跟踪,根据文字描述实时识别可疑人员或物品。
这些应用展示了Grounding DINO在实际场景中的多样性和实用性。随着技术的不断发展,我们可以期待看到更多创新的应用出现。
Grounding DINO的性能评估
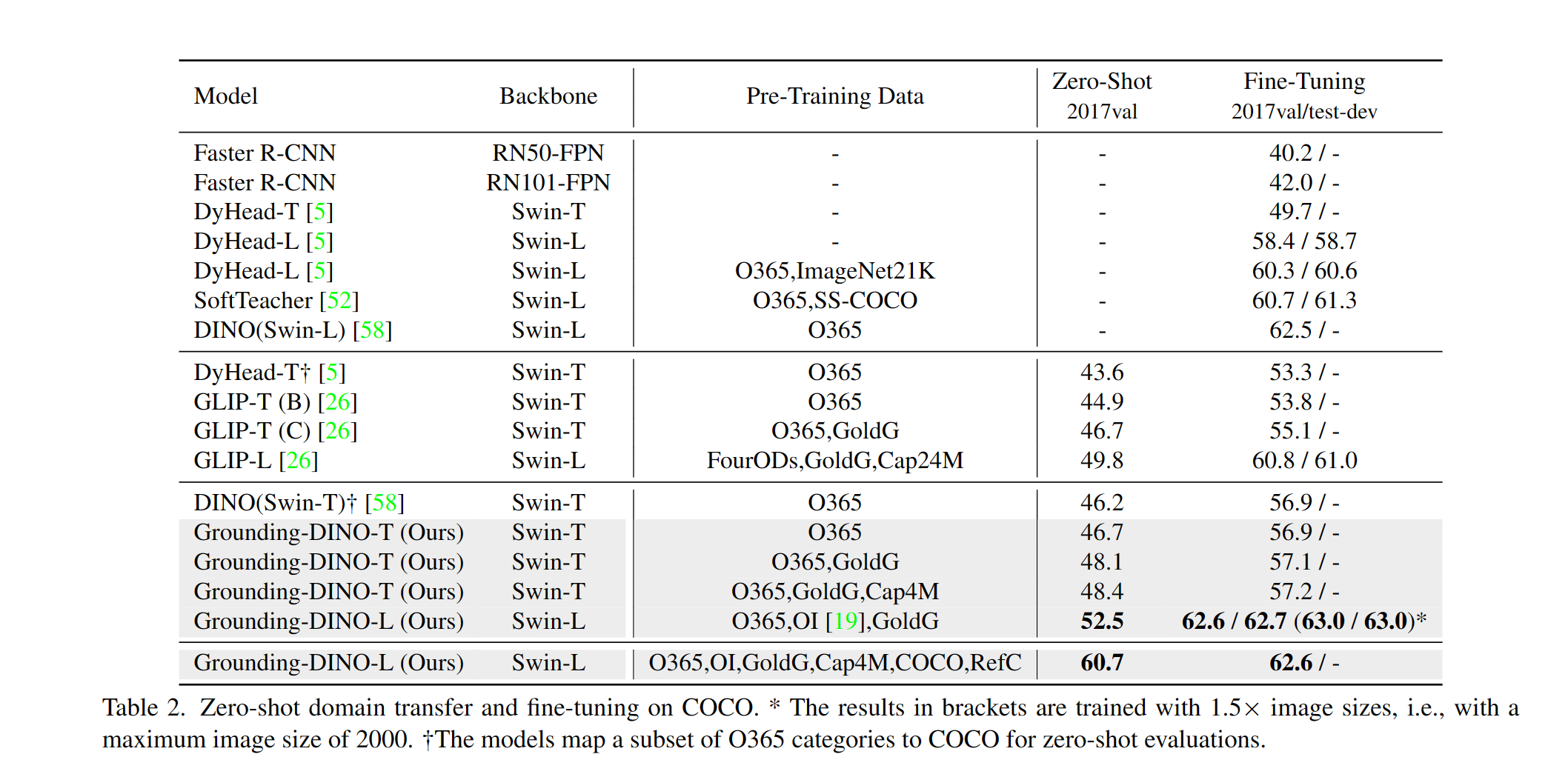
Grounding DINO在多个标准数据集上都展现了卓越的性能,特别是在零样本和微调场景下。以下是一些具体的性能数据:
COCO数据集上的表现
-
零样本性能:
- 在没有使用COCO数据进行训练的情况下,Grounding DINO-T模型在COCO数据集上实现了48.4 AP的零样本检测性能。
- Grounding DINO-B模型更是达到了56.7 AP。
-
微调后性能:
- Grounding DINO-T模型经过微调后,在COCO数据集上达到了57.2 AP。
- 最新的Grounding DINO-B模型在COCO检测基准测试中获得了63.0 AP的高分。
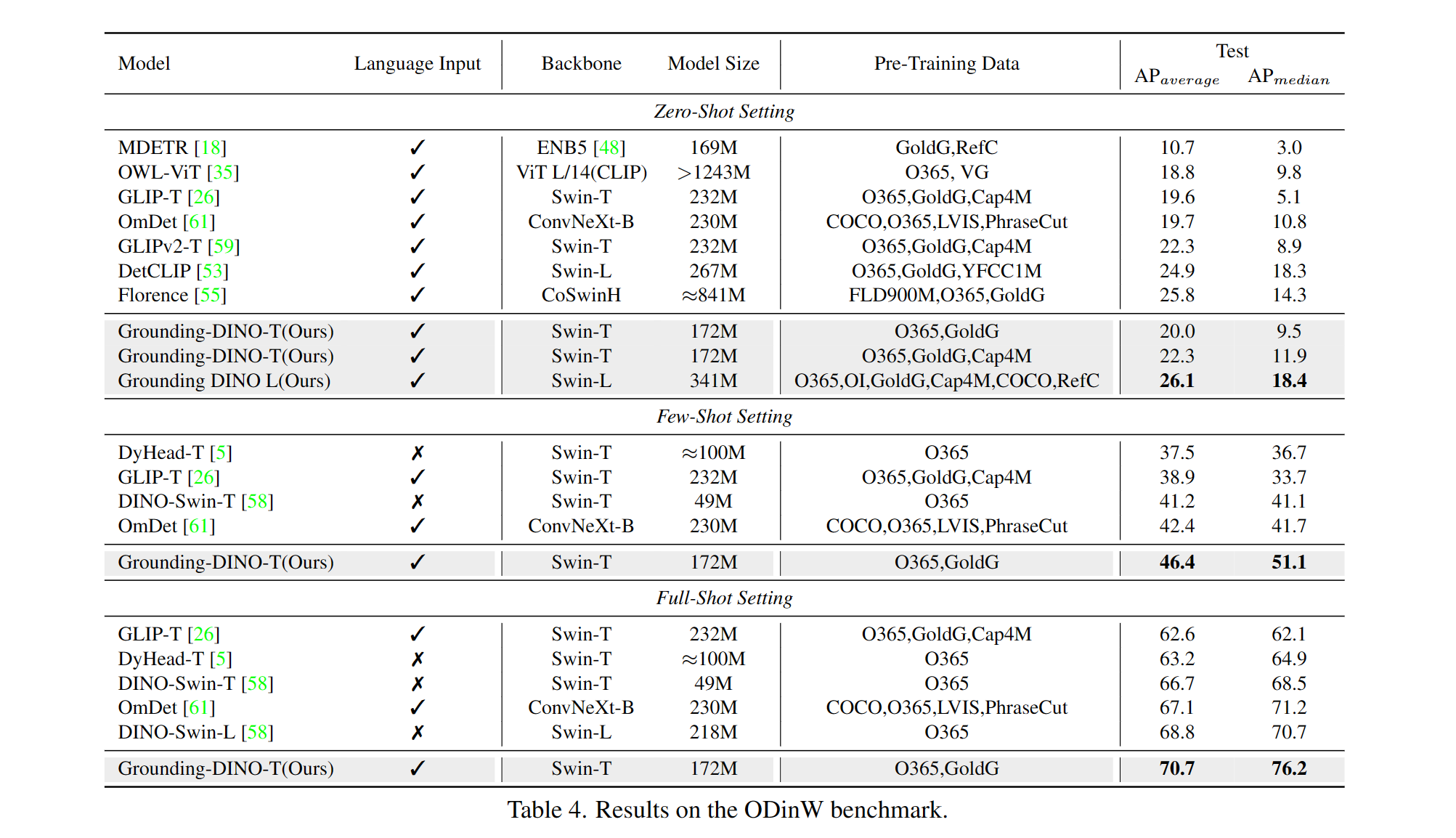
ODinW (Object Detection in the Wild)数据集上的表现
在ODinW数据集上,Grounding DINO同样展现了强大的泛化能力和零样本检测性能。这个数据集包含了多个领域的图像,更好地模拟了现实世界的复杂场景。
Grounding DINO 1.5的性能提升
最新发布的Grounding DINO 1.5进一步提升了模型性能:
- Grounding DINO 1.5 Pro在COCO检测基准测试中达到了54.3 AP。
- 在LVIS-minival零样本转移基准测试中,Grounding DINO 1.5 Pro获得了55.7 AP的高分。
- Grounding DINO 1.5 Edge模型在经过TensorRT优化后,可以达到75.2 FPS的处理速度,同时在LVIS-minival基准测试中获得36.2 AP的零样本性能。
这些数据充分证明了Grounding DINO在开放集目标检测领域的领先地位,无论是在准确性还是处理速度方面都有出色表现。
Grounding DINO的安装与使用
要开始使用Grounding DINO,您需要按照以下步骤进行安装和配置:
-
克隆仓库:
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO -
安装依赖: 在GroundingDINO目录下运行:
pip install -e . -
下载预训练模型:
mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth cd .. -
使用示例: 以下是一个简单的使用示例:
from groundingdino.util.inference import load_model, load_image, predict, annotate import cv2 model = load_model("groundingdino/config/GroundingDINO_SwinT_OGC.py", "weights/groundingdino_swint_ogc.pth") IMAGE_PATH = "path_to_your_image.jpg" TEXT_PROMPT = "chair . person . dog" image_source, image = load_image(IMAGE_PATH) boxes, logits, phrases = predict(model, image, TEXT_PROMPT, box_threshold=0.35, text_threshold=0.25) annotated_frame = annotate(image_source, boxes, logits, phrases) cv2.imwrite("result.jpg", annotated_frame)
这个示例展示了如何加载模型、处理图像并生成带有检测结果的标注图像。您可以根据需要调整文本提示和阈值参数。
Grounding DINO的未来展望
随着Grounding DINO的不断发展和完善,我们可以期待看到更多令人兴奋的进展和应用:
-
更强大的语言理解能力: 未来的版本可能会整合更先进的自然语言处理技术,进一步提升模型对复杂语言指令的理解能力。
-
实时处理能力的提升: 随着硬件和算法的优化,我们可能会看到Grounding DINO在实时视频流处理方面的重大突破。
-
跨模态学习的深化: 进一步探索视觉和语言之间的深层联系,可能会带来更智能、更灵活的检测系统。
-
与大型语言模型的结合: 将Grounding DINO与像GPT系列这样的大型语言模型结合,可能会产生更加智能和交互式的视觉理解系统。
-
在特定领域的深度应用: 例如在医疗影像分析、自动驾驶、工业检测等领域的深度定制和应用。
-
多模态融合: 除了图像和文本,未来可能会融合更多模态的数据,如音频、视频等,实现更全面的场景理解。
-
自监督学习的应用: 利用大规模未标注数据进行自监督学习,进一步提升模型的泛化能力和性能。
Grounding DINO的发展无疑会对计算机视觉和人工智能领域产生深远的影响。它不仅推动了技术的进步,也为解决实际问题提供了强大的工具。研究人员和开发者可以期待这项技术带来的无限可能,并积极参与到其未来的发展中来。
结语
Grounding DINO代表了目标检测技术的一个重要里程碑。它突破了传统目标检测的局限性,开创了语言引导的开放集目标检测的新范式。通过将强大的视觉模型与灵活的语言理解相结合,Grounding DINO为计算机视觉领域带来了前所未有的可能性。
从零样本检测到与其他先进技术的融合,Grounding DINO展现了其在各种应用场景中的巨大潜力。无论是在学术研究还是工业应用中,它都为我们提供了一个强大而灵活的工具。
随着技术的不断进步和完善,我们可以期待看到Grounding DINO在更多领域发挥重要作用,推动人工智能和计算机视觉技术向更高水平发展。对于研究人员和开发者来说,深入探索和利用Grounding DINO无疑是一个充满机遇的方向。
让我们共同期待Grounding DINO及其相关技术在未来带来更多令人惊叹的突破和应用!












