
HDLTex:突破传统分类方法的层次化深度学习模型
近年来,随着数字化进程的加速,产生的文档数量呈爆炸式增长。这给信息检索、管理和组织带来了巨大挑战,其中文档分类成为一个核心问题。传统的监督式分类方法在文档数量和类别数量急剧增加的情况下,性能出现了明显下降。为了解决这一问题,研究人员提出了一种名为HDLTex(Hierarchical Deep Learning for Text classification)的创新方法。
HDLTex的核心思想
HDLTex区别于将文档分类视为多分类问题的传统方法,而是采用层次化分类的思路。它利用堆叠式深度学习架构,为文档层次结构的每个级别提供专门的理解。这种方法能够更好地处理大规模、多层次的文档分类任务。
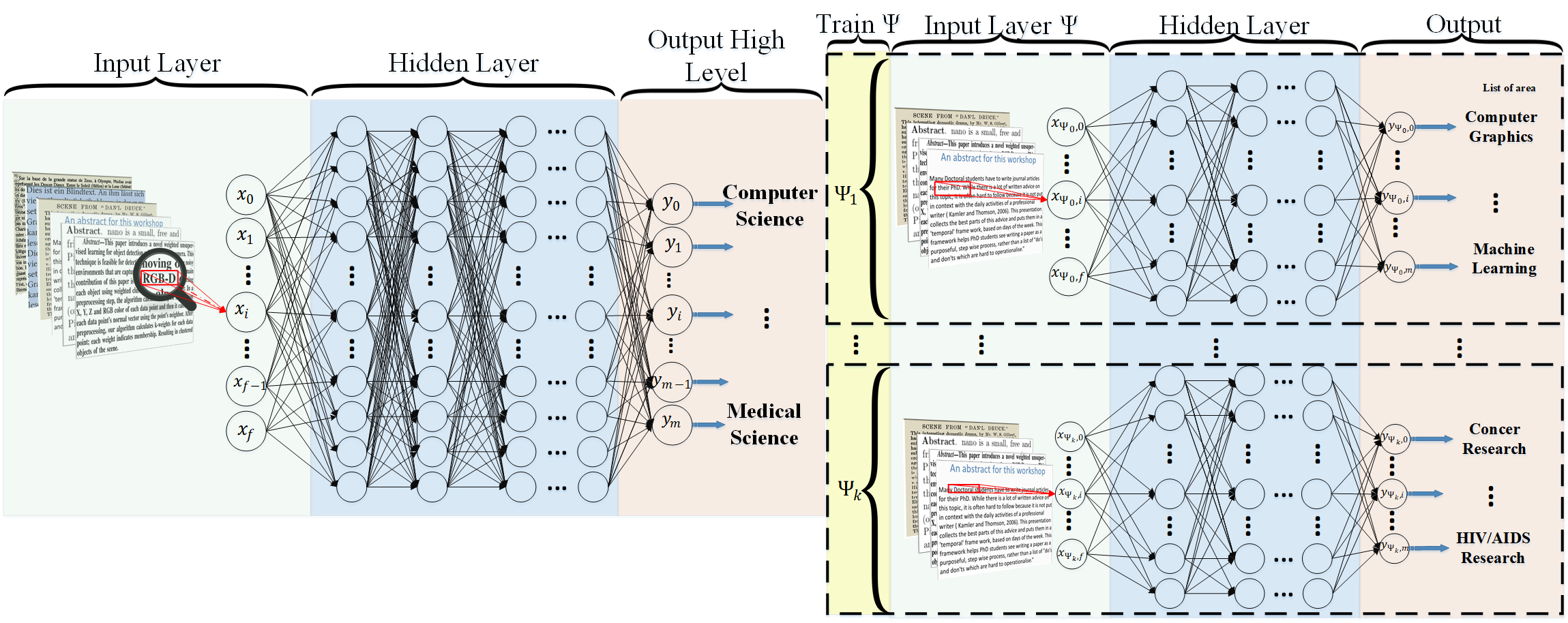
HDLTex的技术实现
-
深度学习架构:HDLTex采用了多种深度学习模型,包括卷积神经网络(CNN)、循环神经网络(RNN)和深度神经网络(DNN)。这些模型被组织成一个层次化的结构,以匹配文档的层次分类需求。
-
特征提取:HDLTex使用全局向量词表示(GloVe)进行特征提取。这种方法能够捕捉词语之间的语义关系,提高分类的准确性。
-
GPU加速:为了处理大规模数据集,HDLTex支持GPU加速,利用CUDA和cuDNN等技术提高计算效率。
HDLTex的优势
-
可扩展性:HDLTex能够处理大规模文档集合和复杂的类别层次结构,适应现代信息环境的需求。
-
性能提升:通过为每个层次level提供专门的理解,HDLTex在处理复杂分类任务时表现出色,克服了传统方法在类别数量增加时性能下降的问题。
-
灵活性:HDLTex的架构允许研究者根据具体任务需求选择和组合不同的深度学习模型。
HDLTex的应用前景
HDLTex在多个领域都有广阔的应用前景:
-
科研文献管理:可用于自动分类和组织大量学术论文,提高研究效率。
-
新闻分类:帮助媒体机构快速对海量新闻进行主题分类。
-
电子商务:优化产品分类系统,提升用户搜索和浏览体验。
-
医疗信息管理:协助医疗机构对病历和医学文献进行精确分类。
HDLTex的未来发展
尽管HDLTex在文本分类领域取得了显著成果,但仍有进一步改进的空间:
-
多语言支持:扩展HDLTex以支持更多语言的文本分类任务。
-
实时学习:开发能够从持续输入的新数据中学习的在线版本。
-
可解释性:增强模型的可解释性,使决策过程更加透明。
-
跨领域迁移:研究如何将HDLTex应用到其他领域的分类任务中。
HDLTex为解决大规模文本分类问题提供了一种创新的方法。随着数字内容的持续增长,这种层次化深度学习方法将在信息管理和知识组织中发挥越来越重要的作用。研究人员和实践者可以基于HDLTex的开源代码进行进一步的探索和应用,推动文本分类技术的不断进步。
🔗 相关链接:
通过不断的创新和优化,HDLTex有望在未来成为处理复杂文本分类任务的标准方法之一,为信息时代的知识管理提供强大支持。


















