
HippoRAG:为大型语言模型打造神经生物学启发的长期记忆系统
在人工智能和自然语言处理领域,大型语言模型(LLMs)的发展日新月异,但在持续学习和知识整合方面仍面临挑战。为了解决这一问题,来自俄亥俄州立大学的研究团队开发了一个名为HippoRAG的创新框架,旨在为LLMs提供类似人类大脑的长期记忆能力。这个框架的设计灵感来自人类大脑中的海马体索引理论,能够帮助LLMs更有效地整合和利用外部知识。
HippoRAG的核心理念
HippoRAG的核心思想是模仿人类大脑中海马体、新皮层和海马旁区域在长期记忆形成和检索中的协同作用。在这个框架中:
- LLM扮演了人工新皮层的角色,负责处理和提取高层次信息。
- 知识图谱结合个性化PageRank算法模拟了海马体的功能,创建记忆索引。
- 检索编码器则充当了海马旁区域的角色,在pipeline中起到中间传递的作用。
这种设计使得HippoRAG能够实现两个关键目标:模式分离(确保不同感知经验的表征是独特的)和模式完成(从部分刺激中回忆完整记忆)。
HippoRAG的工作流程
HippoRAG的工作流程分为两个主要阶段:离线索引和在线检索。
离线索引阶段
- 使用指令调优的LLM对输入文档进行命名实体识别,并提取实体形成三元组。
- 将生成的实体存储在无模式知识图谱中,根据它们的连接进行组织。
- 使用检索编码器对实体进行向量表示,以便后续相似度计算。
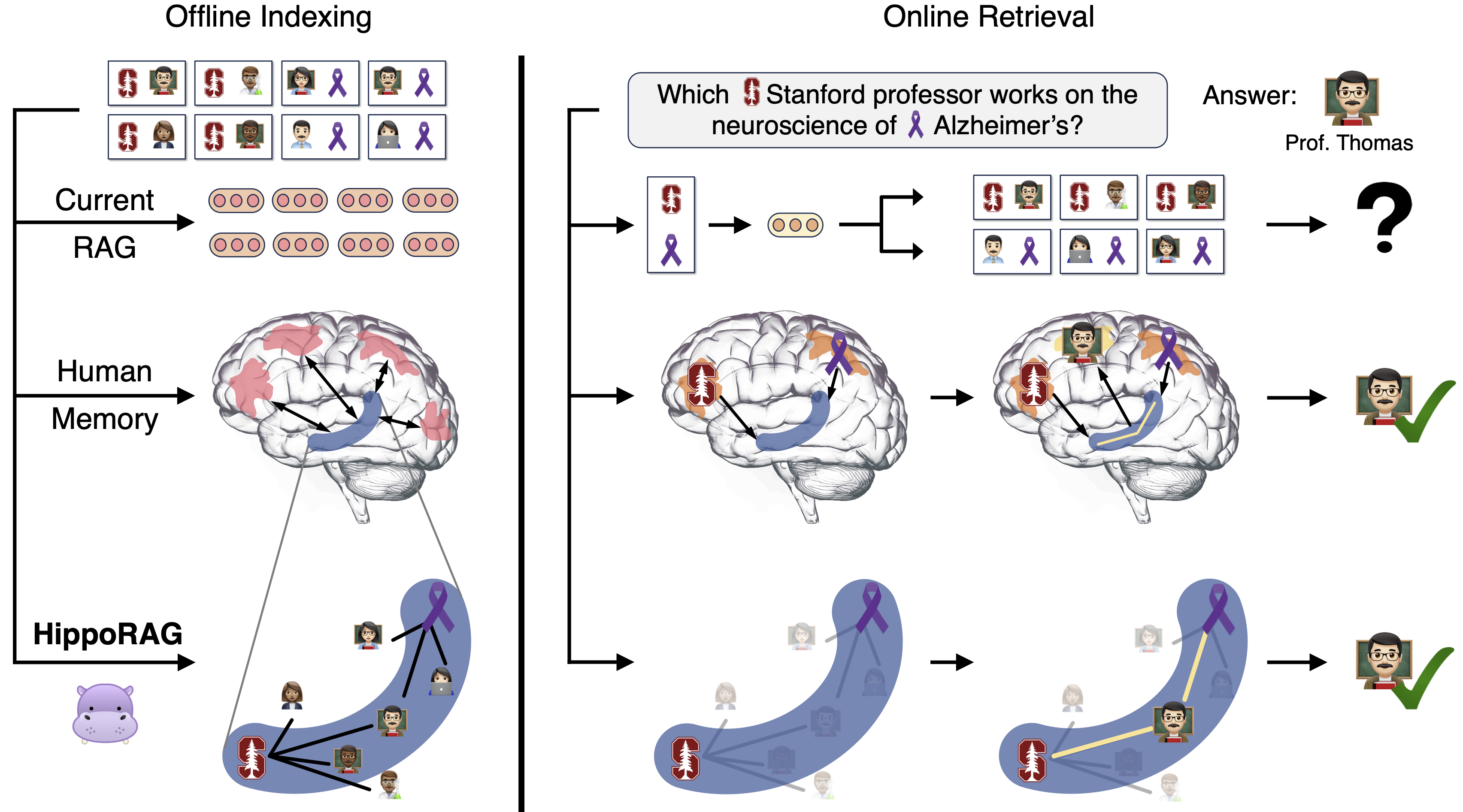
在线检索阶段
- 当用户提出查询时,系统使用一次性提示从查询中提取命名实体。
- 根据余弦相似度,选择知识图谱中与查询实体最相似的节点作为查询节点。
- 在知识图谱上运行个性化PageRank算法,确保每个查询节点具有相等的概率,而其他节点概率为零。
- 根据PageRank结果对先前索引的段落进行排序,并返回最相关的信息。
HippoRAG的优势
- 高效的多跳推理:通过单步检索即可完成传统RAG系统需要多次迭代才能实现的复杂推理任务。
- 知识整合能力:能够在不同文档间建立联系,提供更全面的答案。
- 计算效率:相比传统的迭代RAG方法,HippoRAG在保持或提高性能的同时,显著降低了计算成本和延迟。
- 透明性:可以追踪PageRank遍历过程中访问最多的节点,提供推理过程的可解释性。
实际应用场景
HippoRAG在多个领域展现出巨大潜力,特别是在需要复杂知识整合的任务中:
- 科学文献综述:能够从大量论文中提取和综合关键信息,帮助研究人员快速把握领域动态。
- 法律案例分析:可以连接不同法律文件中的相关信息,协助律师进行全面的案例研究。
- 医疗诊断支持:通过整合患者病历、医学文献和临床指南,为医生提供诊断建议。
- 多语言信息检索:利用其强大的知识图谱和检索能力,实现跨语言的信息整合和查询。
技术实现细节
HippoRAG的实现涉及多个技术组件:
- 知识图谱构建:使用开放信息抽取(Open IE)技术从文本中提取实体和关系。
- 检索编码器:采用如ColBERTv2或Contriever等先进的检索模型进行文本编码。
- 个性化PageRank算法:在知识图谱上运行,实现高效的多跳信息检索。
- LangChain集成:通过LangChain调用不同的LLM API,提高了框架的灵活性和可扩展性。
未来展望
HippoRAG为大型语言模型的长期记忆和知识整合开辟了新的方向。未来的研究可能会集中在以下几个方面:
- 本地部署LLMs:降低对在线API的依赖,提高隐私保护和响应速度。
- 提示词灵活性:开发更灵活的提示策略,以适应不同类型的查询和任务。
- 图数据库支持:集成如Neo4j等成熟的图数据库,进一步提升知识管理能力。
- 图的读写API:开发更全面的API,允许用户直接操作和查询知识图谱。
HippoRAG的出现标志着检索增强生成技术的一个重要里程碑。它不仅提高了大型语言模型处理复杂信息的能力,还为AI系统在长期学习和知识应用方面开辟了新的可能性。随着技术的不断完善和应用范围的扩大,HippoRAG有望在未来的AI应用中发挥越来越重要的作用,为各行各业带来革命性的变革。









