
活字3.0:突破性的中文大模型
在人工智能和自然语言处理快速发展的今天,大规模语言模型(LLM)已成为学术界和工业界的焦点。作为这一浪潮中的重要一员,哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)近期推出了其最新成果——活字3.0大模型,为中文自然语言处理领域带来了新的可能性。
模型概览
活字3.0是一个专门为中文设计的通用大模型,基于Chinese-Mixtral-8x7B架构,经过约30万行指令数据的微调而成。该模型具有以下主要特点:
- 支持32K上下文长度,能够有效处理长文本
- 继承了基座模型丰富的中英文知识
- 在数学推理和代码生成等任务上表现出色
- 经过指令微调,具有强大的指令遵循能力和安全性
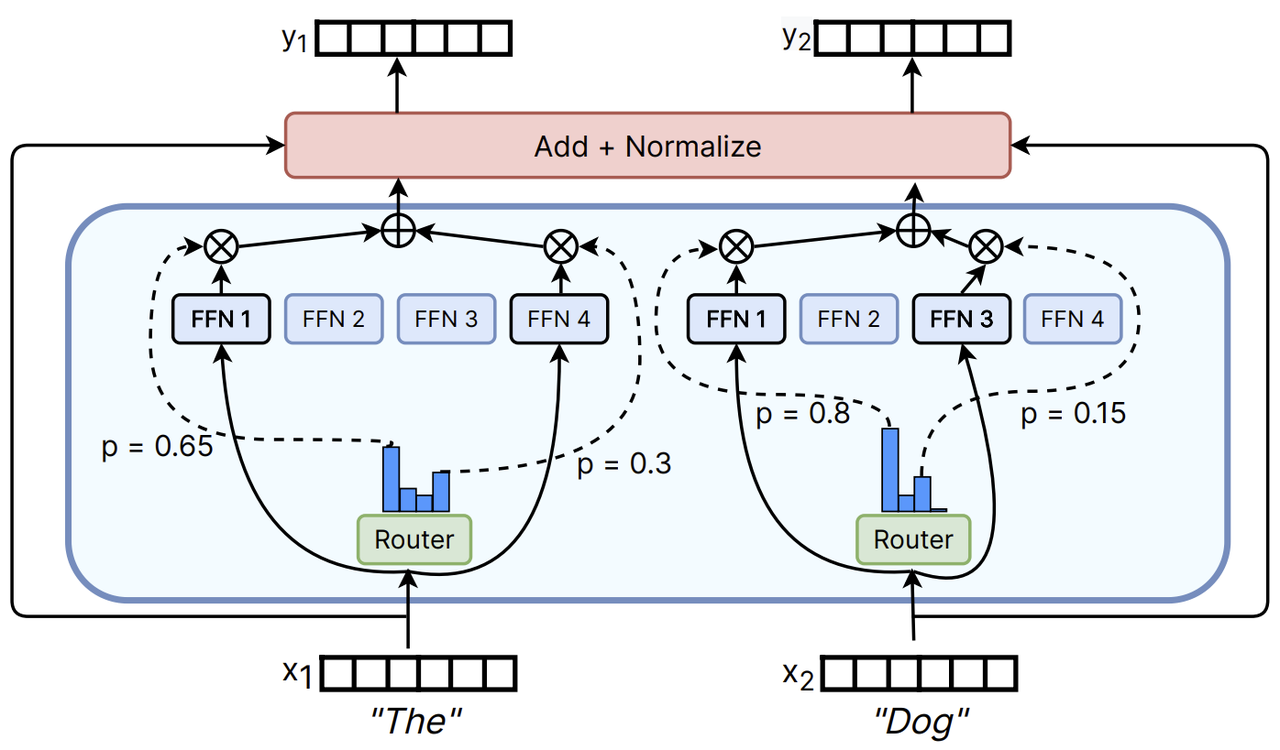
创新的模型结构
活字3.0采用了稀疏混合专家(SMoE)模型结构,这是一种区别于传统Transformer架构的创新设计。在SMoE中,每个前馈神经网络(FFN)层被替换为包含8个FFN和一个"路由器"的"专家层"。这种设计允许模型在推理过程中,针对每个token独立地选择最适合处理它的两个专家。
尽管活字3.0的总参数量达到46.7B,但得益于其稀疏激活的特性,实际推理时仅需激活13B参数。这一创新大大提升了计算效率和处理速度,使得模型在保持强大性能的同时,能够更加高效地运行。
训练过程
活字3.0的训练过程经历了多个精心设计的阶段:
- 基于Mixtral-8x7B进行中文扩词表增量预训练,显著提高了模型对中文的编解码效率。
- 在扩词表模型基础上进行指令微调,进一步增强了模型的中文理解和生成能力。
- 通过大规模指令数据的训练,优化了模型的指令遵循能力和安全性。
这一训练过程确保了活字3.0在中文处理、指令理解和安全性方面都达到了很高的水平。
模型性能评测
为了全面评估活字3.0的性能,研究团队使用了多个权威的评测数据集,包括C-Eval、CMMLU、GAOKAO、MMLU、HellaSwag、GSM8K、HumanEval、MT-Bench等。这些数据集涵盖了从基础知识到高级推理的多个方面,能够全面反映模型的综合能力。
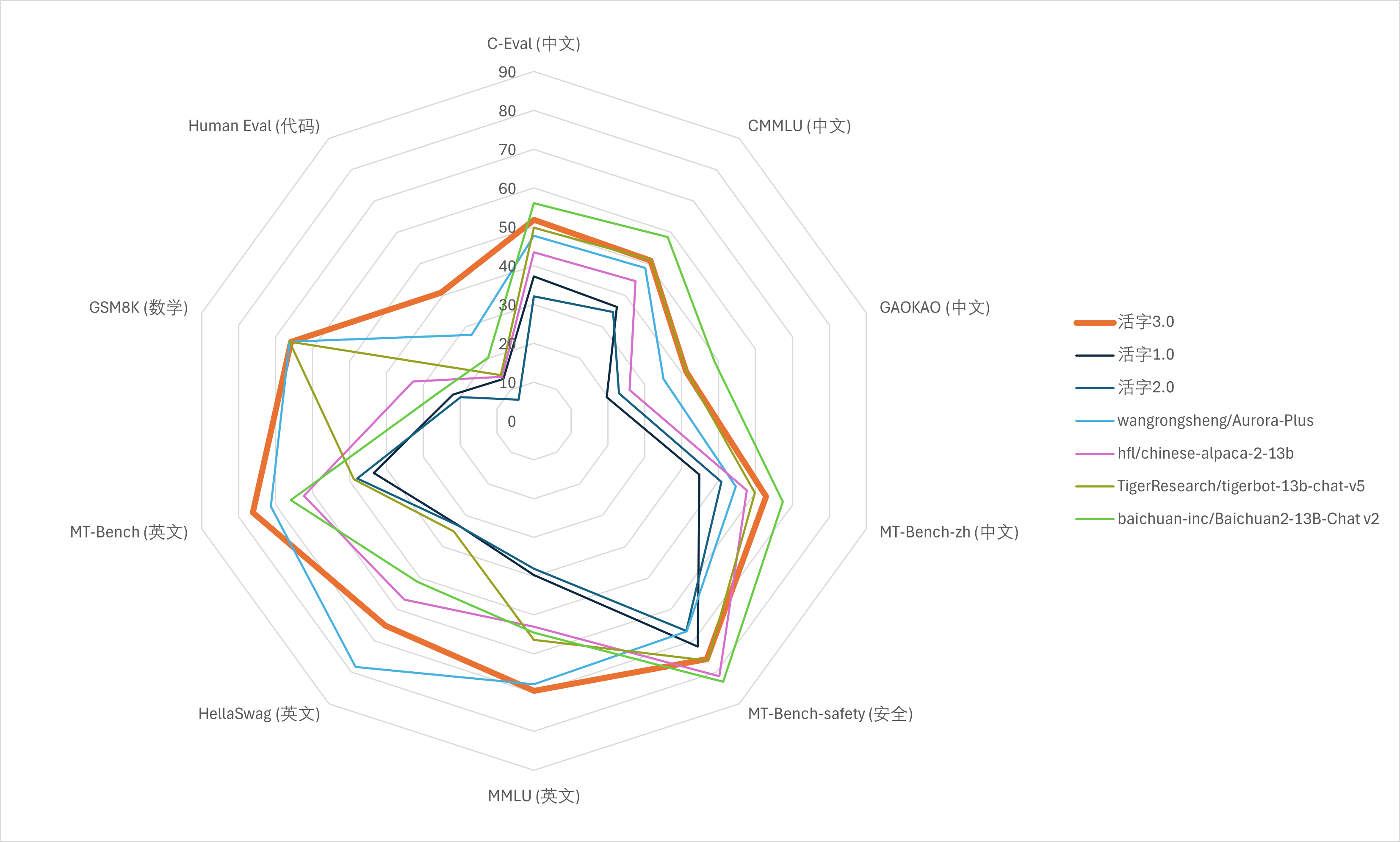
评测结果显示,活字3.0在多个指标上都取得了优异的成绩,特别是在中文相关的任务上表现突出。例如,在C-Eval、CMMLU和GAOKAO等中文评测集上,活字3.0的表现超越了许多同等规模的模型。这充分证明了该模型在中文处理方面的卓越能力。
值得注意的是,活字3.0在英文任务如MMLU和HellaSwag上也展现出了不俗的性能,说明模型具备良好的跨语言能力。在数学推理(GSM8K)和代码生成(HumanEval)等专业任务上,活字3.0同样表现出色,体现了其在复杂任务处理方面的潜力。
模型应用与部署
活字3.0提供了多种灵活的部署和使用方式,以满足不同场景的需求:
1. 直接使用Transformers库
使用Hugging Face的Transformers库可以快速加载和使用活字3.0模型:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "HIT-SCIR/huozi3"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
# 使用模型进行推理
2. vLLM推理加速
对于需要高效推理的场景,可以使用vLLM框架来加速活字3.0的推理过程:
from vllm import LLM, SamplingParams
llm = LLM(
model="HIT-SCIR/huozi3",
tensor_parallel_size=4,
)
# 使用vLLM进行推理
3. OpenAI API兼容服务
活字3.0还可以部署为支持OpenAI API协议的服务,这使得已经适配OpenAI API的应用可以直接使用活字3.0:
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:8000/v1",
)
# 使用OpenAI API调用活字3.0
4. 量化推理
为了在有限的硬件资源上运行活字3.0,模型提供了多种量化方案:
- GGUF格式:支持llama.cpp等推理框架,可以将显存占用降低到18GB甚至更低。
- AWQ格式:使用AutoAWQForCausalLM加载,可以在32GB显存上运行完整模型。
这些量化方案大大提高了模型的部署灵活性,使得活字3.0能够在更多场景中发挥作用。
开源与社区贡献
活字3.0项目秉承开源精神,不仅开放了模型权重,还提供了详细的使用文档和示例代码。研究团队同时开源了中文MT-Bench评测数据集,为中文大模型的评估提供了新的标准。
项目欢迎社区贡献,包括但不限于:
- 提交Issue报告问题或提出建议
- 贡献Pull Request改进代码
- 参与模型应用的开发和优化
通过GitHub仓库HIT-SCIR/huozi,开发者可以方便地获取最新的模型更新和相关资源。
未来展望
活字3.0的发布标志着中文大模型研究又迈出了重要一步。未来,研究团队计划从以下几个方向继续推进模型的发展:
- 进一步扩大模型规模,探索更大参数量下的性能提升。
- 优化模型结构,提高推理效率和响应速度。
- 增强多模态能力,使模型能够处理图像、音频等多种输入。
- 深化领域知识,提升模型在专业领域的应用能力。
- 加强模型的可解释性和伦理安全性。
随着活字项目的不断发展,我们有理由相信,它将为中文自然语言处理领域带来更多创新和突破,推动人工智能技术在中文环境下的广泛应用。
结语
活字3.0的推出为中文自然语言处理领域带来了新的可能性。它不仅在性能上达到了国际领先水平,还在中文处理方面展现出了独特优势。通过开源和社区协作,活字项目正在推动中文AI技术的快速发展。我们期待看到更多基于活字3.0的创新应用,以及它在推动中文信息处理技术进步中发挥的重要作用。










