
iGAN简介
iGAN(Interactive GAN)是由加州大学伯克利分校的Jun-Yan Zhu等人于2016年提出的一种交互式图像生成和编辑系统。它基于生成对抗网络(GAN)技术,允许用户通过简单的涂鸦和编辑操作来生成和操控逼真的图像。iGAN的核心思想是将用户的编辑意图映射到GAN的潜在空间,从而生成符合用户期望的高质量图像。
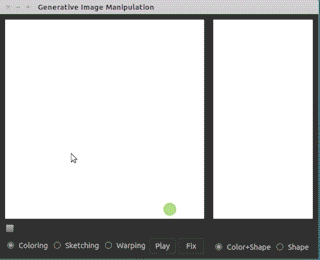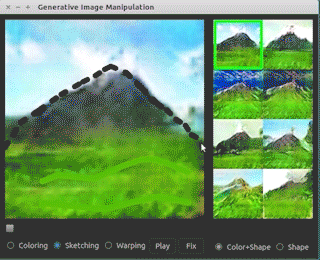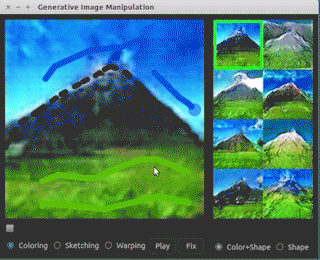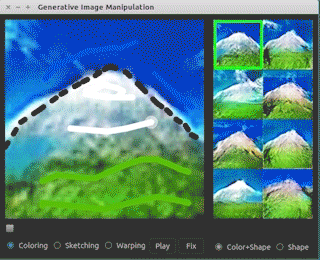
如上图所示,iGAN提供了一个直观的用户界面,用户可以通过涂鸦、勾勒轮廓等简单操作来指导图像的生成过程。系统会实时响应用户的输入,生成符合用户意图的逼真图像。这种交互式的图像生成方式为创意设计、艺术创作等领域带来了新的可能性。
iGAN的技术原理
iGAN的核心是将用户的编辑操作映射到预训练GAN模型的潜在空间。具体来说,iGAN采用了以下关键技术:
-
预训练的DCGAN模型:iGAN使用DCGAN(Deep Convolutional GAN)作为基础生成模型。DCGAN在大规模图像数据集上预训练,能够生成高质量的逼真图像。
-
交互式编辑接口:iGAN提供了直观的绘图工具,包括涂色笔刷、素描笔刷和变形笔刷,允许用户自由编辑图像。
-
约束优化:系统将用户的编辑操作转化为潜在空间中的约束条件,通过优化算法在潜在空间中寻找最佳的潜在向量。
-
实时反馈:iGAN能够实时响应用户的编辑操作,快速生成符合用户意图的图像,提供流畅的交互体验。
-
多模态生成:系统可以生成多个候选结果,让用户选择最满意的图像。
通过这些技术的结合,iGAN实现了直观、高效的交互式图像生成和编辑功能。
iGAN的主要功能
iGAN提供了多种强大的图像生成和编辑功能:
-
交互式图像生成:用户可以通过简单的涂鸦来指导系统生成符合期望的图像。例如,用户可以勾勒出建筑物的轮廓,系统会自动生成相应的逼真建筑图像。
-
图像编辑:用户可以对已有图像进行编辑,如改变颜色、修改形状等。系统会保持图像的整体结构和风格,同时满足用户的编辑需求。
-
多样化结果:对于给定的用户输入,iGAN可以生成多个候选结果,展现不同的可能性,用户可以从中选择最满意的图像。
-
图像插值:系统支持在不同图像之间进行平滑插值,生成过渡序列,展示图像的渐变过程。
-
素描辅助:iGAN还提供了类似ShadowDraw的素描辅助功能,帮助用户更好地绘制物体轮廓。
这些功能使iGAN成为一个强大而灵活的图像生成和编辑工具,适用于多种创意场景。
iGAN的应用场景
iGAN的创新性使其在多个领域都有潜在的应用价值:
-
创意设计:设计师可以使用iGAN快速生成和探索新的设计概念,加速创意过程。
-
艺术创作:艺术家可以利用iGAN创造新颖的视觉效果,拓展艺术表现的可能性。
-
图像编辑:iGAN为图像编辑提供了更直观和智能的方式,使非专业用户也能轻松创作高质量图像。
-
计算机视觉研究:iGAN为研究人员提供了一个可视化和理解深度生成模型的工具。
-
教育:iGAN可以用于教学,帮助学生理解图像生成和编辑的原理。
iGAN的技术细节
模型架构
iGAN主要基于DCGAN(Deep Convolutional GAN)模型。DCGAN是一种将卷积神经网络与GAN结合的模型,能够生成高质量的图像。iGAN使用预训练的DCGAN模型作为基础,通过优化潜在空间中的向量来生成符合用户编辑的图像。
用户交互映射
iGAN的一个关键创新是将用户的编辑操作映射到GAN的潜在空间。具体来说:
- 颜色编辑:用户的颜色涂鸦被转换为像素级的颜色约束。
- 轮廓编辑:用户绘制的轮廓被转换为边缘约束。
- 变形编辑:用户的拖拽操作被转换为局部变形约束。
这些约束被用来在潜在空间中寻找最佳的潜在向量。
优化算法
iGAN采用基于梯度下降的优化算法来寻找最佳的潜在向量。优化目标包括:
- 满足用户编辑约束
- 保持生成图像的真实性
- 接近初始随机向量(以保持多样性)
通过平衡这些目标,iGAN能够生成既符合用户意图又保持真实感的图像。
iGAN的实现和使用
iGAN的源代码已在GitHub上开源(https://github.com/junyanz/iGAN),使用Python和Theano实现。要运行iGAN,需要满足以下要求:
- 硬件:建议使用支持CUDA的NVIDIA GPU以获得实时性能。
- 软件依赖:Python 2.7,OpenCV,Theano,PyQt4等。
- 预训练模型:作者提供了多个预训练的DCGAN模型,包括户外场景、教堂、手提包等。
使用iGAN的基本步骤如下:
- 安装所需的软件依赖。
- 下载预训练模型。
- 运行主程序
iGAN_main.py。 - 在交互界面中使用各种工具进行创作和编辑。
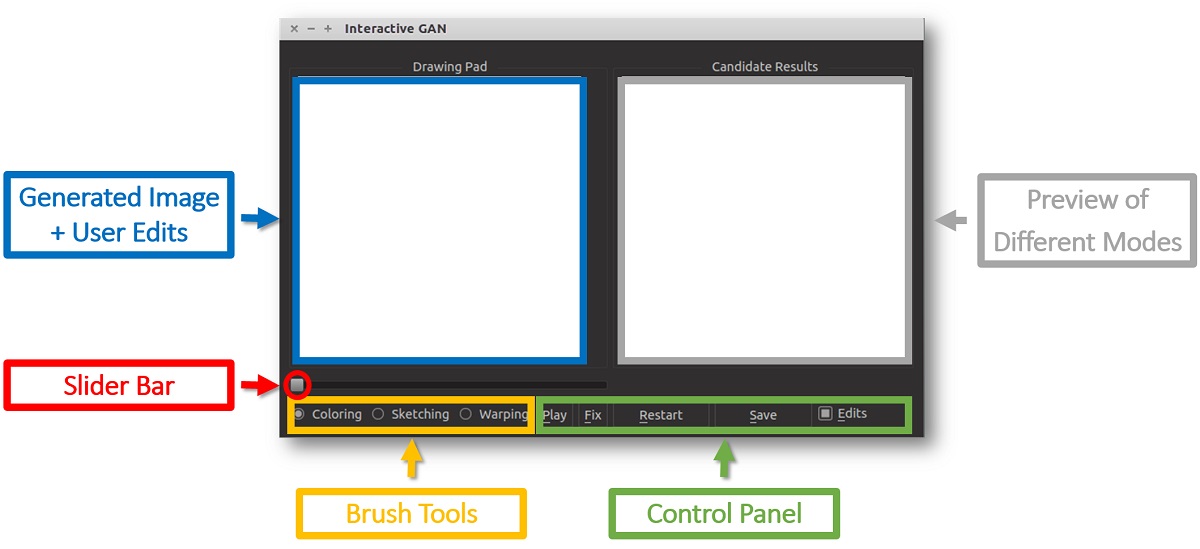
如上图所示,iGAN的界面包括绘图区、候选结果区、工具栏等组件,为用户提供了直观的操作体验。
iGAN的局限性和未来发展
尽管iGAN在交互式图像生成领域取得了重要突破,但它仍存在一些局限性:
- 图像分辨率:当前版本支持的图像分辨率较低(64x64像素),限制了实际应用。
- 模型泛化性:预训练模型的性能高度依赖于训练数据,对于未见过的场景可能表现不佳。
- 实时性:在普通硬件上可能无法达到理想的实时性能。
- 用户控制的精确度:有时用户可能难以精确控制生成结果的细节。
未来,iGAN及类似技术可能在以下方向继续发展:
- 提高图像分辨率和质量
- 增强模型的泛化能力
- 改进优化算法,提高响应速度
- 提供更精细的用户控制
- 与其他图像生成和编辑技术结合
结论
iGAN代表了图像生成和编辑技术的一个重要里程碑。它将深度学习的强大能力与直观的用户交互相结合,为创意工作者提供了一个强大的工具。尽管仍有改进空间,但iGAN已经展示了AI辅助创作的巨大潜力。随着技术的不断进步,我们可以期待看到更多类似iGAN的创新应用,进一步推动计算机图形学和人工智能的发展。
iGAN的成功也启发了后续的多项研究,如pix2pix和CycleGAN等图像转换模型。这些技术正在不断改变我们创作和处理图像的方式,为艺术、设计、娱乐等领域带来新的可能性。未来,随着硬件性能的提升和算法的优化,我们有望看到更加强大和易用的交互式图像生成工具,进一步释放人类的创造力.










