
大语言模型的实践之旅
在人工智能快速发展的今天,大语言模型(Large Language Models, LLMs)已经成为了推动自然语言处理领域革新的核心力量。本文将带领读者深入了解LLMs的实际应用,从理论到实践,全方位探索这一前沿技术。
LLMs实践项目概述
本文将以构建一个金融顾问系统为例,详细介绍如何利用LLMs、向量数据库和流式处理技术来设计、实现和部署一个实时的智能系统。这个项目不仅涵盖了LLMs的核心应用,还融合了当前最先进的MLOps实践。
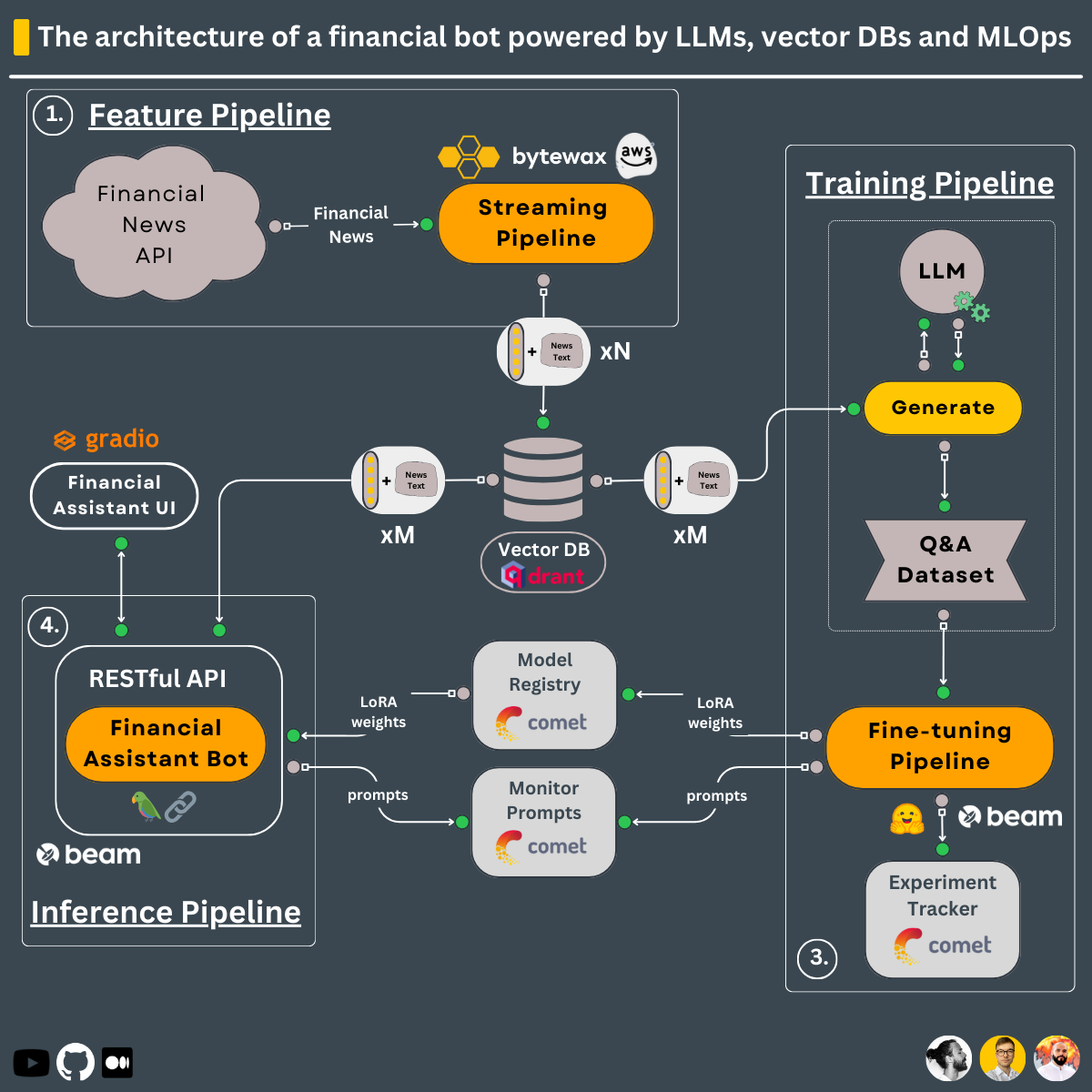
系统核心组件
1. 训练流程
训练流程是整个系统的基石,主要包括以下步骤:
- 加载专有的问答数据集
- 使用QLoRA技术微调开源LLM
- 利用Comet ML进行实验跟踪和模型管理
- 将最佳模型存储在Comet ML的模型注册表中
这一流程通过Beam的无服务器GPU基础设施进行部署,充分利用云计算资源,提高训练效率。
2. 实时流式处理流程
为了保持系统的实时性和准确性,我们设计了一个实时特征工程流程:
- 从Alpaca获取实时金融新闻
- 使用Bytewax进行实时数据清洗和转换
- 将处理后的嵌入向量存储到Qdrant向量数据库中
这个流程通过AWS EC2实例自动部署,确保了系统能够持续获取最新的金融信息。
3. 推理流程
推理流程是系统与用户交互的核心,它利用LangChain构建了一个复杂的处理链:
- 从Comet模型注册表下载微调后的模型
- 接收用户问题并查询Qdrant向量数据库
- 结合用户查询、向量数据库上下文和聊天历史调用微调后的LLM
- 持久化聊天历史并将提示和回答记录到Comet ML的LLMOps监控功能中
这个流程同样通过Beam部署为无服务器的RESTful API,并使用Gradio包装成一个用户友好的界面。
技术栈深度解析
LLM微调技术
在本项目中,我们采用了QLoRA (Quantized Low-Rank Adaptation)技术进行LLM的微调。这种方法不仅能够有效减少计算资源的需求,还能保持模型性能的同时提高微调的效率。
# QLoRA微调示例代码
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
model = prepare_model_for_kbit_training(model)
config = LoraConfig(r=8, lora_alpha=32, target_modules=["query_key_value"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM")
model = get_peft_model(model, config)
向量数据库应用
Qdrant作为本项目的向量数据库,在处理大规模嵌入向量和实现高效相似度搜索方面发挥了关键作用。它的应用使得系统能够快速检索相关的金融新闻,为LLM提供丰富的上下文信息。
# Qdrant向量数据库使用示例
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
client = QdrantClient("localhost", port=6333)
client.create_collection(
collection_name="financial_news",
vectors_config=VectorParams(size=768, distance=Distance.COSINE),
)
流式处理技术
Bytewax的应用使得系统能够实时处理incoming的金融新闻流。这种流式处理方法不仅提高了系统的响应速度,还能确保金融顾问系统始终基于最新的市场信息提供建议。
# Bytewax流式处理示例
from bytewax.dataflow import Dataflow
from bytewax.inputs import SimpleInput
def process_news(item):
# 处理新闻item的逻辑
return processed_item
flow = Dataflow()
flow.input("input", SimpleInput(range(10)))
flow.map(process_news)
flow.output("output", print)
MLOps最佳实践
在本项目中,我们充分利用了Comet ML提供的MLOps功能,实现了模型开发到持续训练流水线的全过程管理。这包括:
- 实验跟踪:记录每次训练的超参数、性能指标等。
- 模型版本控制:管理不同版本的模型,便于回滚和比较。
- 生产监控:实时监控模型在生产环境中的表现。
这些实践不仅提高了模型开发的效率,还确保了模型在生产环境中的稳定性和可靠性。
部署与扩展
整个系统的部署充分利用了云服务的优势,主要包括:
- 训练和推理流程:使用Beam的无服务器GPU资源,按需分配计算能力。
- 特征工程流程:部署在AWS EC2实例上,确保稳定的实时数据处理。
- 向量数据库:使用Qdrant的云服务,简化了数据库的管理和扩展。
这种部署方式不仅降低了运维成本,还提供了良好的可扩展性,能够根据需求快速调整系统资源。
未来展望
随着LLMs技术的不断进步,我们可以预见以下几个方向的发展:
- 模型效率优化:进一步减小模型size的同时保持性能,使得在边缘设备上部署成为可能。
- 多模态融合:结合图像、音频等多种数据源,提供更全面的分析能力。
- 持续学习:实现模型在生产环境中的自动更新,保持对最新信息的敏感度。
结语
大语言模型的实践应用是一个充满挑战但也极具回报的领域。通过本文介绍的金融顾问系统案例,我们不仅展示了LLMs的强大功能,还阐述了如何将其与现代软件工程和MLOps实践相结合。这只是LLMs应用的冰山一角,未来还有更多激动人心的可能性等待我们去探索。
希望本文能为读者提供有价值的见解,激发更多创新应用的灵感。让我们共同期待LLMs为各行各业带来的变革与机遇!


















