
Indic NLP Library简介
Indic NLP Library是一个专门为印度语言设计的自然语言处理工具库。它由Anoop Kunchukuttan开发,旨在为印度语言提供通用的文本处理和自然语言处理功能。印度语言在脚本、语音学和语法等方面有许多相似之处,该库试图为印度语言文本提供一个通用的解决方案。
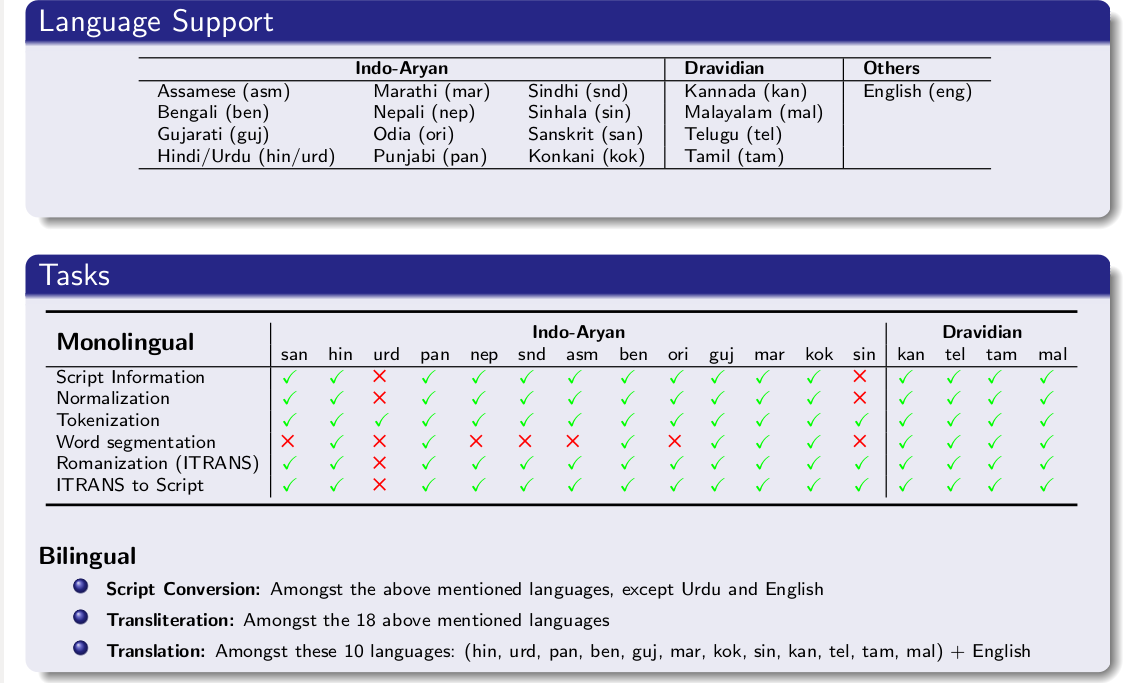
主要功能
Indic NLP Library提供了以下主要功能:
-
文本规范化:处理印度语言文本中的各种异常和不一致问题。
-
脚本信息:提供关于印度语言脚本的各种信息。
-
分词和去分词:将文本分割成单词,或将单词重新组合成文本。
-
句子分割:将文本分割成句子。
-
词语分割:将复合词分割成更小的单位。
-
音节划分:将单词分割成音节。
-
脚本转换:在不同的印度语言脚本之间进行转换。
-
罗马化:将印度语言文本转换为罗马字母。
-
印度化:将罗马化文本转换回印度语言脚本。
这些功能涵盖了处理印度语言文本时最常见的需求,为研究人员和开发者提供了强大的工具支持。
支持的语言
Indic NLP Library支持多种印度语言,包括但不限于:
- 印地语
- 泰米尔语
- 泰卢固语
- 马拉地语
- 孟加拉语
- 古吉拉特语
- 奥里亚语
- 旁遮普语
- 马拉雅拉姆语
- 卡纳达语
这几乎涵盖了印度所有主要的语言,使得该库可以应用于广泛的印度语言处理任务。
使用方法
使用Indic NLP Library非常简单。首先需要通过pip安装:
pip install indic-nlp-library
然后可以在Python代码中导入并使用:
from indicnlp.normalize.indic_normalize import IndicNormalizerFactory
from indicnlp.tokenize import indic_tokenize
# 创建一个Hindi文本规范化器
normalizer = IndicNormalizerFactory().get_normalizer("hi")
# 规范化文本
normalized_text = normalizer.normalize(input_text)
# 分词
tokens = indic_tokenize.trivial_tokenize(normalized_text)
库提供了统一的命令行接口,可以方便地进行常见操作:
python -m indicnlp <operation> <input_file> <output_file> <language>
其中<operation>可以是normalize、tokenize等。
资源和文档
Indic NLP Library需要一些额外的数据资源才能发挥全部功能。这些资源可以从Indic NLP Resources项目下载。
详细的API文档和使用说明可以在官方文档中找到。此外,项目还提供了一个IPython Notebook,展示了如何使用Python API。
应用案例
Indic NLP Library已经被多个重要的组织和项目采用,包括:
-
AI4Bharat-IndicNLPSuite: 一个综合的印度语言NLP工具套件。
-
The Classical Language Toolkit (CLTK): 用于处理古典语言的工具包,其中的梵语部分借鉴了Indic NLP Library。
-
Microsoft NLP Recipes: 微软的NLP最佳实践和示例代码集合。
-
Facebook M2M-100: Facebook的多语言机器翻译模型。
这些应用案例充分证明了Indic NLP Library在学术研究和工业应用中的价值。
结语
Indic NLP Library为印度语言的自然语言处理提供了一个强大而灵活的工具集。无论是进行学术研究还是开发实际应用,它都是一个不可或缺的资源。随着印度科技行业的迅速发展和印度语言在全球范围内重要性的提升,Indic NLP Library必将在未来发挥更加重要的作用。
对于有志于研究印度语言或开发相关应用的人来说,Indic NLP Library无疑是一个值得深入学习和使用的工具。它不仅可以大大提高工作效率,还能帮助我们更好地理解和处理印度丰富多样的语言体系。









